摘要
机器学习与大规模生物数据的进展重新激发了构建虚拟细胞(预测细胞行为的计算模型,可加速生物学发现)的研究前景。该愿景的核心应用是体外表型筛选,即模型预测细胞扰动在未知生物场景下的效应,该任务融合异质文本输入与多样表型输出,高度适配大语言模型与智能体系统。但目前该任务缺乏标准化基准,现有研究仅聚焦分子层面读数,与真实药物研发流程中的表型终点脱节。本研究推出基于1,920个公开CRISPR筛选构建的表型筛选预测基准AssayBench,覆盖5大类细胞表型;将筛选预测任务定义为单筛选基因排序任务,提出调整型归一化折损累积增益(AnDCG)用于异质检测的统一评估。大量评估表明,现有方法远未达到经验性能上限,零样本通用大语言模型优于生物专用模型与可训练基线;微调、集成、提示优化可进一步提升模型性能。总体而言,AssayBench为体外表型筛选与虚拟细胞模型研究提供了实用测试平台,基准已开源。
https://github.com/Genentech/AssayBench
{debroue1,edwarc24,wua33,scaliag}@gene.com
#虚拟细胞 #表型筛选 #CRISPR筛选 #大语言模型 #智能体 #基准测试 #调整型归一化折损累积增益 #多组学数据
数据准备
筛选数据整理与归一化
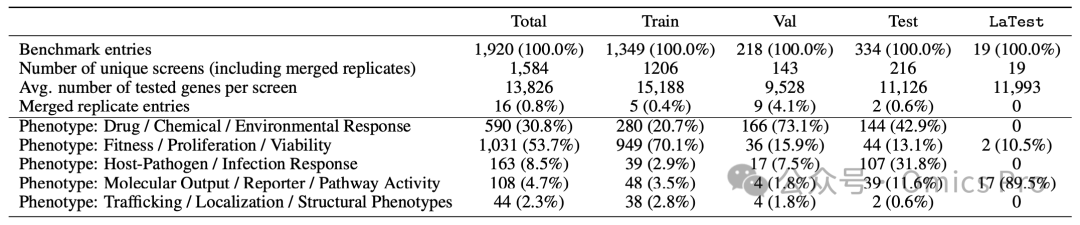
表1 按数据划分的AssayBench数据集统计信息
基准总条目数、训练/验证/测试/最新集的条目占比、唯一筛选数量、单筛选平均检测基因数、合并重复条目数,以及5大表型类别在各划分集中的数量与占比。
提示词生成
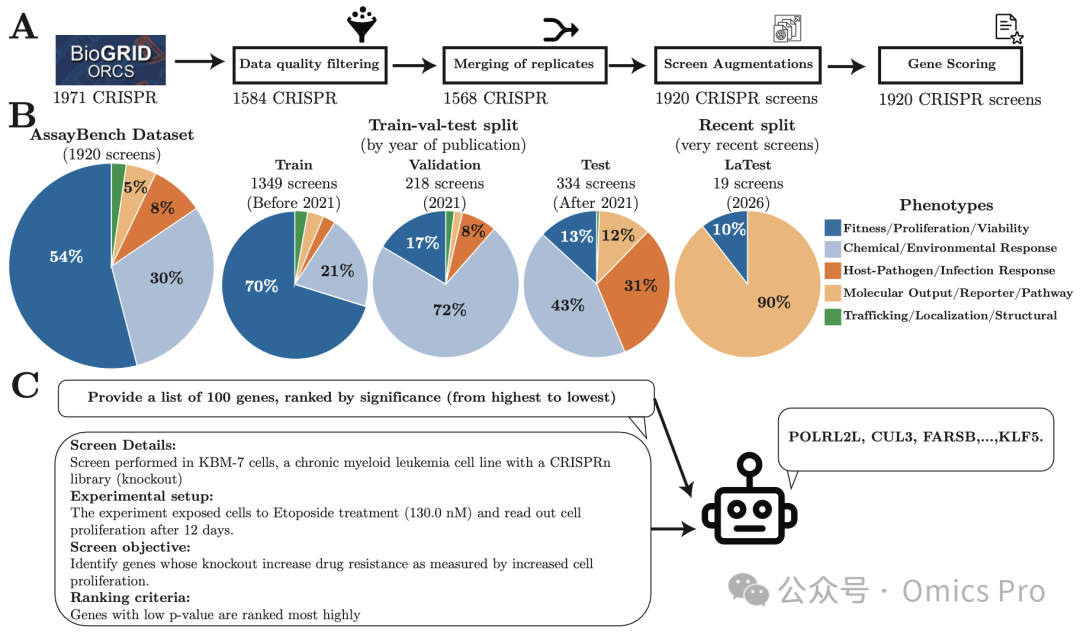
图1 AssayBench基准构建流程概览
(A) 从1,971个人类CRISPR筛选出发,经数据质量过滤、技术重复合并、数据增强,最终得到1,920个高质量筛选条目;
(B) 数据集的表型构成与4大划分集分布,采用贴合真实场景的时序划分策略;
(C) 给定筛选描述与排序规则,模型需输出100个按表型显著性从高到低排序的基因。
实验结果
前沿通用大语言模型领跑基准测试性能
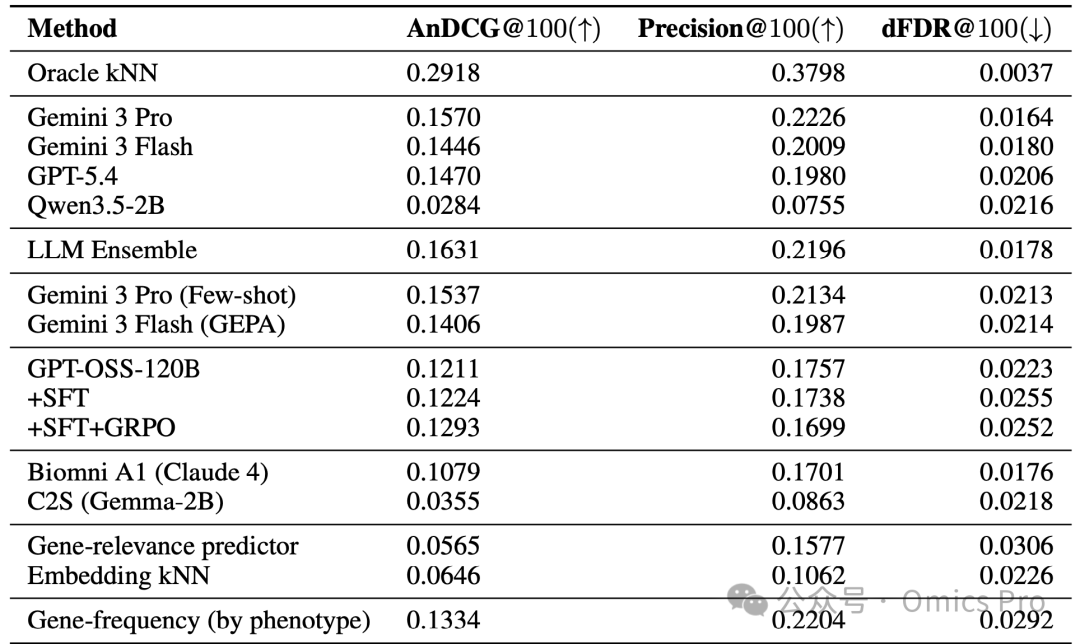
表2 测试集各模型的AnDCG@100、精确率@100与定向错误发现率@100结果
箭头指示指标优劣(↑数值越高性能越好,↓数值越低性能越好),展示不同模型在测试集上的3项核心评估指标数值。
最优模型仍远未达到性能上限
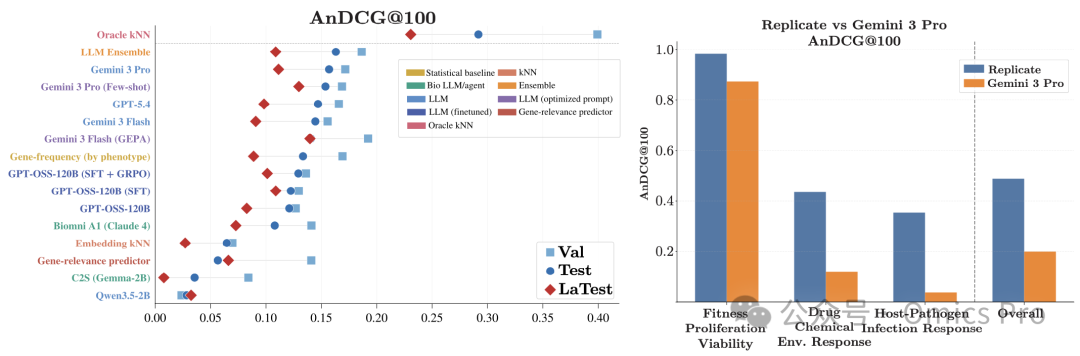
图2 主流模型性能与技术重复基线对比
(左) 按模型类别着色的主流模型AnDCG@k数值;
(右) 基于32个技术重复筛选,对比Gemini 3 Pro与技术重复基线的AnDCG@100性能。
预测性能随表型类型与模型规模变化
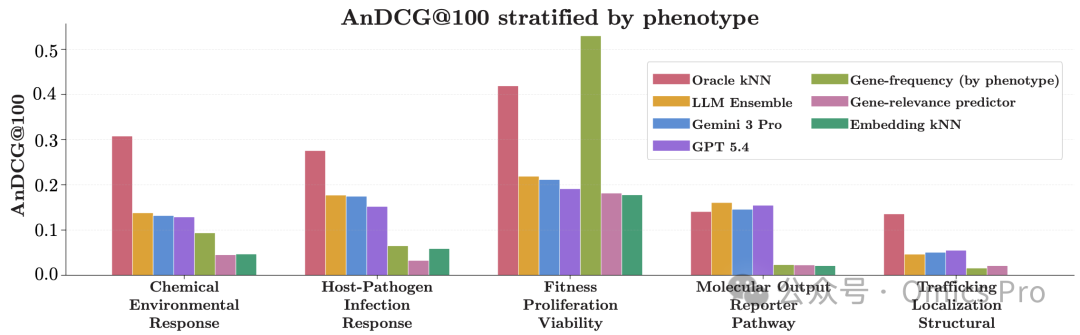
图 3 测试集部分模型按表型划分的AnDCG@100性能
展示选定模型在5大表型类别上的AnDCG@100数值,体现不同表型的预测难度差异。
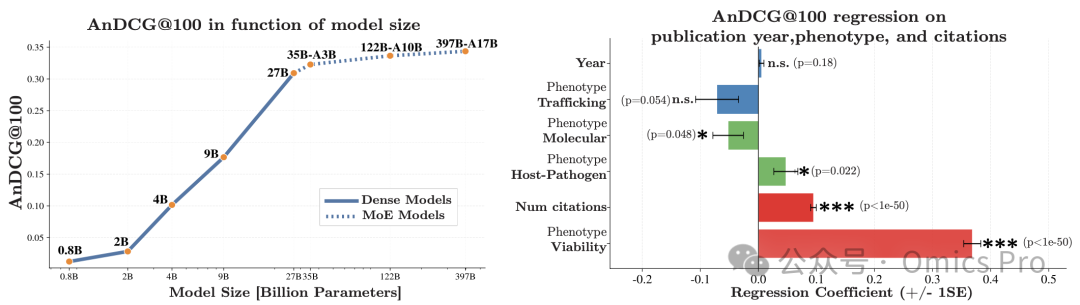
图 4 模型参数规模效应与性能协变量回归分析
(左) Qwen3.5系列模型参数规模与AnDCG@100的关系,大模型(混合专家模型)性能上升并趋于平稳;
(右) 发表年份、表型、引用量对Gemini 3 Pro性能的回归系数,引用量为极显著影响因素。
大语言模型的生物偏好性评估
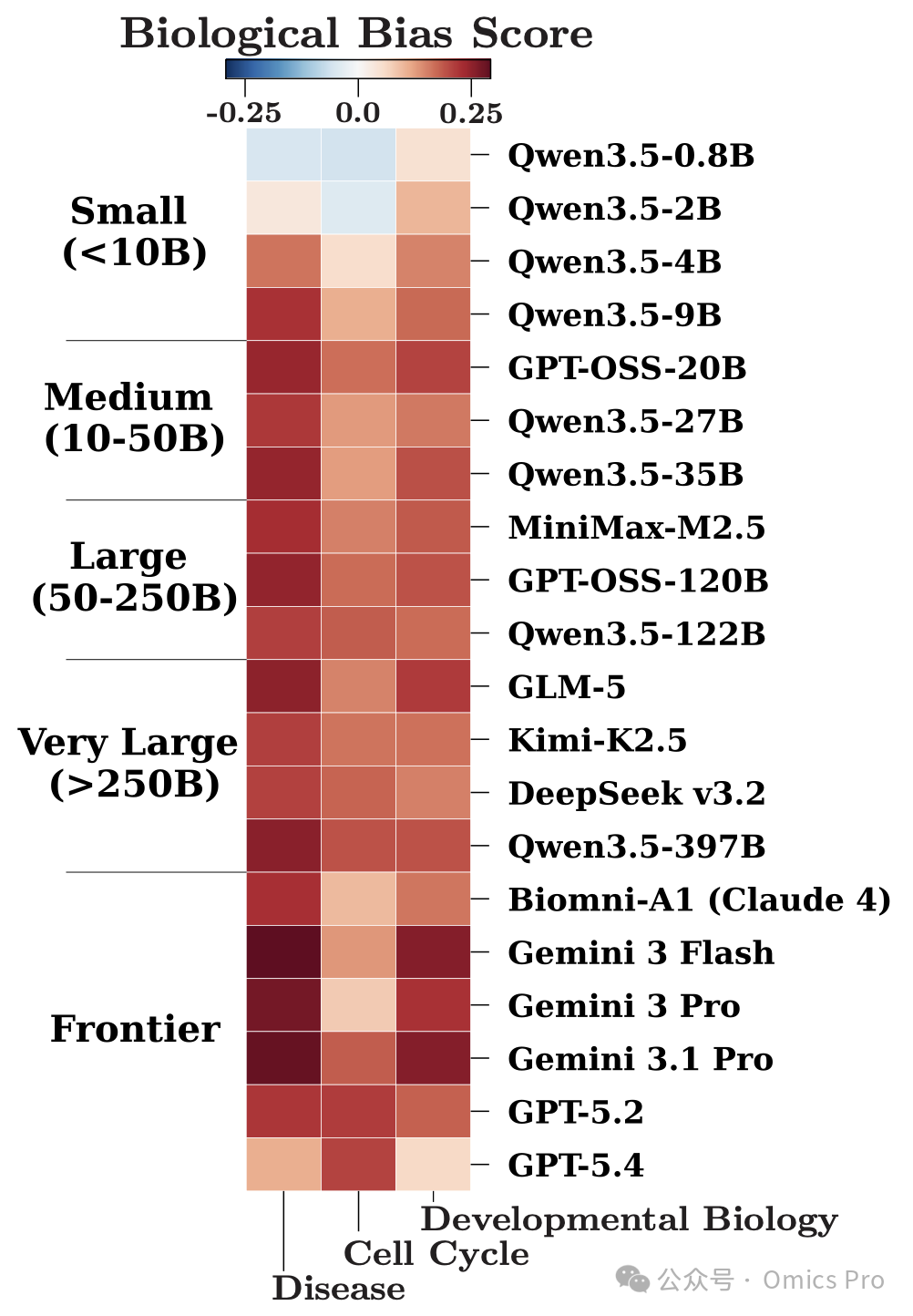
图 5 不同模型的生物偏好性评分
展示各模型在疾病相关基因、发育生物学基因、细胞周期基因集上的偏好偏差,正值代表模型过度代表该类基因,负值代表代表不足。
详细总结
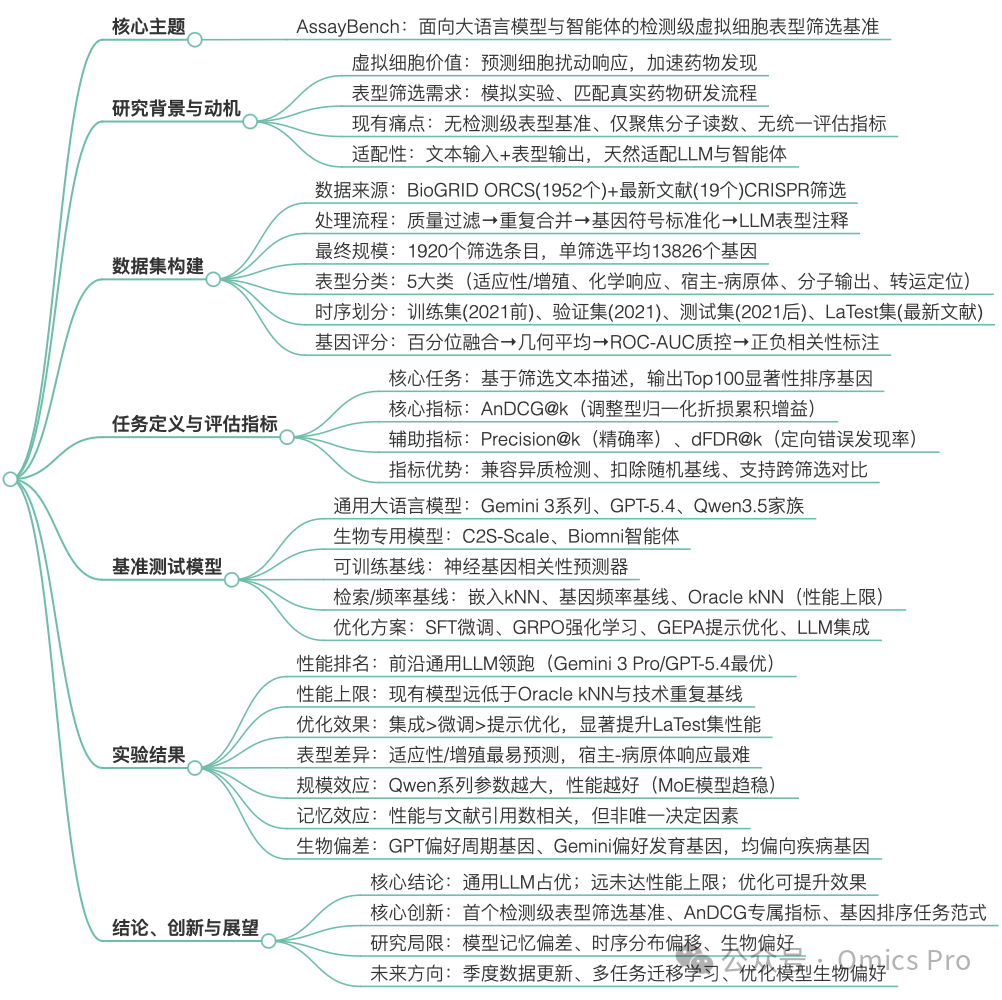
思维导图
参考
AssayBench: An Assay-Level Virtual Cell Benchmark for LLMs and Agents
https://doi.org/10.48550/arXiv.2605.10876
注:AI辅助创作,如有错误欢迎指出。内容仅供参考,不构成任何建议。
《基因泰克:检测级虚拟细胞基准!大语言模型+智能体》 是转载文章,点击查看原文。

