chunks/6aa33e512648af4a.js","/_next/static/chunks/0ef7a81eb15c6e1e.js","/_next/static/chunks/ac3bed0a14b9cb37.js"],"default"]
1d:I[14984,["/_next/static/chunks/9f5585e398b26f04.js","/_next/static/chunks/c75cb1bef6e71994.js","/_next/static/chunks/61807fc645e355b8.js","/_next/static/chunks/3e5f3fa61a51b363.js","/_next/static/chunks/6aa33e512648af4a.js","/_next/static/chunks/0ef7a81eb15c6e1e.js","/_next/static/chunks/ac3bed0a14b9cb37.js"],"default"]
1f:I[36773,["/_next/static/chunks/9f5585e398b26f04.js","/_next/static/chunks/c75cb1bef6e71994.js","/_next/static/chunks/61807fc645e355b8.js","/_next/static/chunks/3e5f3fa61a51b363.js","/_next/static/chunks/6aa33e512648af4a.js","/_next/static/chunks/0ef7a81eb15c6e1e.js","/_next/static/chunks/ac3bed0a14b9cb37.js"],"default"]
20:I[35094,["/_next/static/chunks/9f5585e398b26f04.js","/_next/static/chunks/c75cb1bef6e71994.js","/_next/static/chunks/61807fc645e355b8.js","/_next/static/chunks/3e5f3fa61a51b363.js","/_next/static/chunks/6aa33e512648af4a.js","/_next/static/chunks/0ef7a81eb15c6e1e.js","/_next/static/chunks/ac3bed0a14b9cb37.js"],"default"]
1e:T84d,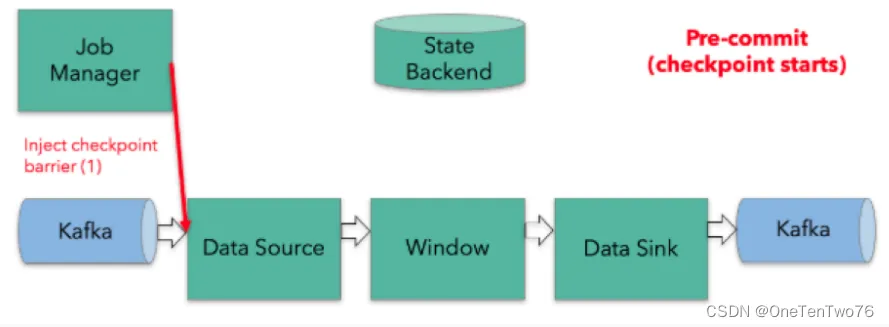
Flink的一阶段提交流程
Apache Flink 是一个分布式流处理框架,用于高效处理大规模数据流。在 Flink 中,“提交”通常指将作业部署到集群执行的过程。用户提到的“一阶段提交”可能指的是 Flink 中某些特定场景下的简化提交机制,尤其是在事务处理或 Sink 端(输出端)的 Exactly-Once 语义实现中。标准 Flink 作业提交涉及多个步骤,但“一阶段提交”更常见于事务管理上下文,例如当 Sink 系统支持幂等操作时,Flink 可以使用一阶段提交来简化流程,避免两阶段提交协议的复杂性。
下面我将逐步解释 Flink 中一阶段提交的流程,以帮助您理解。需要注意的是,一阶段提交通常用于 Sink 端事务,而不是作业本身的提交过程(作业提交一般涉及集群部署)。流程基于 Flink 的 TwoPhaseCommitSinkFunction 或其简化版本。
步骤 1: 理解一阶段提交的背景
- 为什么需要一阶段提交? 在分布式系统中,Flink 使用检查点(Checkpoint)机制确保 Exactly-Once 语义。当数据写入外部系统(如数据库或消息队列)时,Flink 通过事务管理来保证数据不丢失或不重复。两阶段提交(2PC)是常见方法,但它有性能开销(如准备阶段延迟)。一阶段提交作为优化,省略准备阶段,直接提交事务,适用于支持幂等写入的 Sink 系统(例如,某些数据库或文件系统)。
- 适用场景:一阶段提交常用于 Sink 函数中,当外部系统支持原子提交或幂等操作时。Flink 的
TwoPhaseCommitSinkFunction可以扩展为一阶段实现。
步骤 2: Flink 一阶段提交的核心流程
一阶段提交流程主要发生在
Flink的一阶段提交流程
Apache Flink 是一个分布式流处理框架,用于高效处理大规模数据流。在 Flink 中,“提交”通常指将作业部署到集群执行的过程。用户提到的“一阶段提交”可能指的是 Flink 中某些特定场景下的简化提交机制,尤其是在事务处理或 Sink 端(输出端)的 Exactly-Once 语义实现中。标准 Flink 作业提交涉及多个步骤,但“一阶段提交”更常见于事务管理上下文,例如当 Sink 系统支持幂等操作时,Flink 可以使用一阶段提交来简化流程,避免两阶段提交协议的复杂性。
下面我将逐步解释 Flink 中一阶段提交的流程,以帮助您理解。需要注意的是,一阶段提交通常用于 Sink
《flink的一阶段提交的流程》 是转载文章,点击查看原文。