本专栏前文已介绍完成索引模块程序:
目录
1. 验耗时
2. 多线程制作索引
2.1 关于CountDownLatch
2.2 关于线程加锁
2.3 关于守护线程
3. 修改后的Parser类的run方法
1. 验耗时
在Paser类中的run方法内打时间戳检验耗时操作:
1public void run(){ 2 long beg = System.currentTimeMillis(); 3 System.out.println("开始构造索引"); 4 5 long Beg = System.currentTimeMillis(); 6// 1、根据加载文档路径,枚举该路径目录及其子目录下的所有文件(html) 7 ArrayList<File> fileList=new ArrayList<>(); 8 // INPUT-PATH表示开始进行递归遍历的起始目录 9 // fileList表示递归遍历的结果 10 enumFile(INPUT_PATH, fileList); 11 long enumFileEnd = System.currentTimeMillis(); 12 System.out.println("枚举文件耗时:"+(enumFileEnd-Beg)+" ms"); 13 14// 2、根据罗列出的文件路径打开文件,读取文件内容,进行解析并构建索引 15 16 for(File f: fileList){ 17// parseHTML方法用于解析单个HTML文件 18 System.out.println("开始解析 "+f.getAbsolutePath()); 19 parseHTML(f); 20 } 21 long forEnd = System.currentTimeMillis(); 22 System.out.println("遍历文件耗时:"+(forEnd-enumFileEnd)+" ms"); 23// 3、把内存中构造的索引数据结构保存到指定文件中 24 index.save(); 25 System.out.println("完成构造索引"); 26 long end = System.currentTimeMillis(); 27 System.out.println("构建索引耗时:"+(end - beg)+" ms "); 28 }
再次启动Paser类,获取耗时如下:

(省略中间各html文件的遍历输出结果)
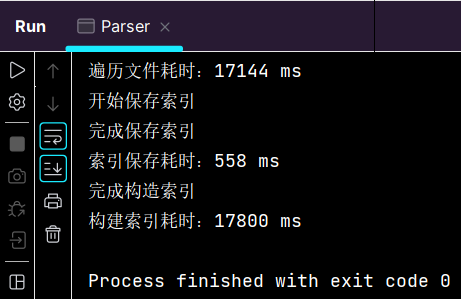
可见在构建索引的枚举、遍历和保存三个操作中,遍历文件耗时占比最高,现基于该问题进行制作索引的优化,考虑使用多线程制作索引。
2. 多线程制作索引
2.1 关于CountDownLatch
CountDownLatch是一个同步辅助工具,允许一个或多个线程等待其他线程完成操作,其实现线程同步的思想是计数器思想,countDown方法实现减少计数器值,await方法实现等待计数器清零。
通过submit向线程池里提交任务,只是把Runnable对象放到阻塞队列中,并不代表线程池中的文档在submit提交完成后也被全部解析完了。为了保证执行save时保存的是完整的解析后的全部文档,采用CountDownLatch的await方法来表示所有任务都完成。
2.2 关于线程加锁
在Index类中有一个addDoc方法,会调用buildForward方法和buildInverted方法,buildForward方法会修改forwardIndex,buildInverted方法会修改invertedIndex,四个线程并发调用addDoc时就存在线程安全问题,需要加锁来解决线程安全问题。
如果直接把synchronized加到parseHTML或addDoc上,加锁粒度太粗使得并发程度较低,需要再细致地考虑加锁的粒度。
在buildForwad方法中,设置docId和将新doc插入到正排索引中两个操作需要加锁:
1 synchronized (locker1){ 2 docInfo.setDocId(forwardIndex.size()); 3 forwardIndex.add(docInfo); 4 }
在buildInverted方法中,在倒排拉链中根据关键词去倒排索引中查找的结果的操作都需要加锁:
1 synchronized (locker2){ 2 List<Weight> invertedList = invertedIndex.get(entry.getKey()); 3 // 如果为空则插入新键值对 4 if(invertedList == null){ 5 ArrayList<Weight> newInvertedList = new ArrayList<>(); 6 // 把当前的文档信息docInfo构造成Weight对象 7 Weight weight = new Weight(); 8 weight.setDocId(docInfo.getDocId()); 9 // 假定权重公式:标题中出现的次数*10+正文中出现的次数*1 10 weight.setWeight(entry.getValue().titleCount*10+entry.getValue().contentCount); 11 newInvertedList.add(weight); 12 invertedIndex.put(entry.getKey(),newInvertedList); 13 }else{ 14 //非空则将当前文档信息docInfo构造成Weight对象插入倒排拉链 15 Weight weight = new Weight(); 16 weight.setDocId(docInfo.getDocId()); 17 weight.setWeight(entry.getValue().titleCount*10+entry.getValue().contentCount); 18 invertedList.add(weight); 19 } 20 }
且注意二者并不竞争同一锁资源,故创建的locker1和locker2为不同锁资源:
1 // 新创建两个锁对象 2 private Object locker1 = new Object(); 3 private Object locker2 = new Object();
2.3 关于守护线程
如果一个线程是守护线程(后台线程),则这个线程的运行状态不会影响到进程结束。
如果一个线程不是守护线程,则这个线程的运行状态就会影响到进程结束。
之前我们采用的是线程池创建线程:
ExecutorService executorService = Executors.newFixedThreadPool(4);
默认创建出来的都是非守护线程,故当main方法执行完后这些线程仍然在等待新任务,并未终止,需要使用shutdown方法进行手动终止。
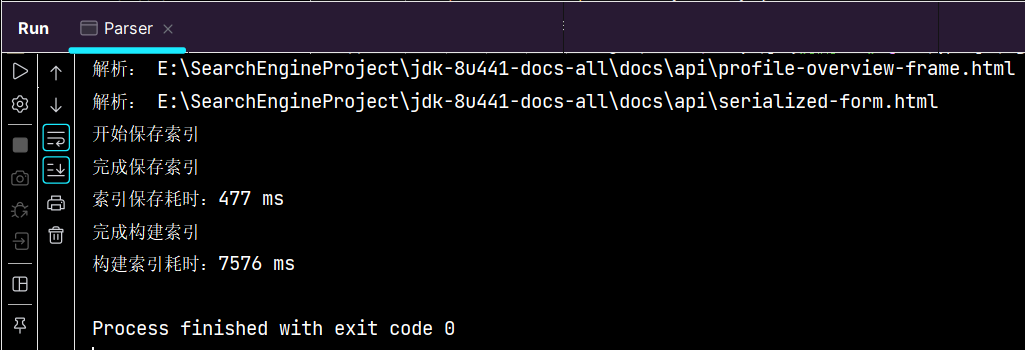
可见使用多线程后,构建索引耗时由17s将至7s,效率得到了提升。
3. 修改后的Parser类的run方法
1 /* 2 * 优化制作索引:多线程制作索引 3 * */ 4 public void run() throws InterruptedException { 5 long beg = System.currentTimeMillis(); 6 System.out.println("开始构建索引"); 7 // 1. 枚举文件: 8 ArrayList<File> files = new ArrayList<>(); 9 enumFile(INPUT_PATH, files); 10 // 2. 多线程循环遍历文件: 11 CountDownLatch latch = new CountDownLatch(files.size()); 12 ExecutorService executorService = Executors.newFixedThreadPool(4); 13 for(File f: files){ 14 // 通过submit向线程池里提交任务,只是把Runnable对象放到阻塞队列中 15 executorService.submit(new Runnable() { 16 @Override 17 public void run() { 18 System.out.println("解析: "+f.getAbsolutePath()); 19 parseHTML(f); 20 latch.countDown(); 21 } 22 }); 23 } 24 // 3. 待所有文件解析完成后再保存索引: 25 latch.await(); 26 // 手动终止线程池中的所有线程 27 executorService.shutdown(); 28 index.save(); 29 30 long end = System.currentTimeMillis(); 31 System.out.println("完成构建索引"); 32 System.out.println("构建索引耗时:"+(end-beg)+" ms"); 33 } 34
《Java8 API文档搜索引擎_优化构建索引速度》 是转载文章,点击查看原文。
