一、引言
在俄罗斯展会网站采集中,莫斯科轮胎及橡胶展览会(Expocentr)的网站采用了典型的表格布局和dt/dd结构存储展商信息。本文以该展会参展商信息采集项目为例,深入剖析在开发过程中遇到的四大技术难题,以及我们如何通过创新的技术方案逐一攻克这些难关。
二、技术难点全景图
四大技术难关
dt/dd表格解析
键值对结构
dt/dd配对遍历
字段映射转换
键名规范化
URL拼接缺失
相对路径提取
基础URL缺失
404错误风险
手动拼接修复
ON DUPLICATE字段覆盖
增量更新策略
指定字段更新
updated_at时间戳
数据一致性
CSS选择器定位
tbody tr选择
td索引访问
badge类提取
多级元素嵌套
三、核心难题攻克详解
3.1 难关一:dt/dd键值对表格解析
问题描述:
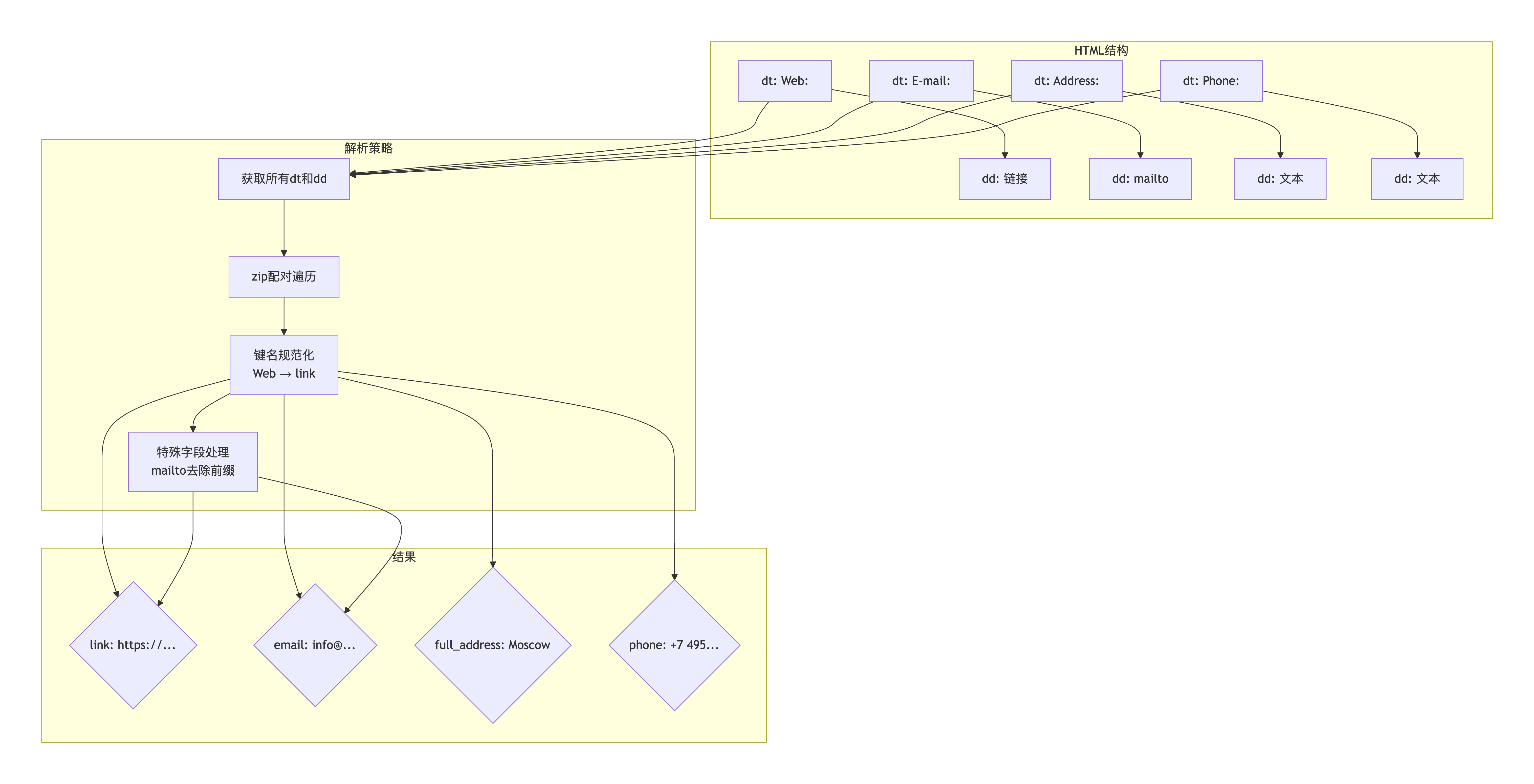
展商详情页使用HTML定义列表(<dl>)结构,信息以<dt>(定义术语)和<dd>(定义描述)的键值对形式存储。需要将这种结构解析为字典,并映射到数据库字段。
1<dl> 2 <dt>Web:</dt> 3 <dd><a href="https://company.ru">www.company.ru</a></dd> 4 5 <dt>E-mail:</dt> 6 <dd><a href="mailto:info@company.ru">info@company.ru</a></dd> 7 8 <dt>Address:</dt> 9 <dd>Moscow, Russia</dd> 10 11 <dt>Phone:</dt> 12 <dd>+7 495 123-45-67</dd> 13</dl> 14
攻克方案:
核心代码实现:
1def get_exhibitor_details(detail_url): 2 """攻克dt/dd表格解析难题""" 3 4 response = requests.get(detail_url) 5 soup = BeautifulSoup(response.text, 'html.parser') 6 7 details = {} 8 panel = soup.find('div', class_='panel-body') 9 10 if panel: 11 # 第一步:获取所有dt和dd元素 12 dt_elements = panel.find_all('dt') 13 dd_elements = panel.find_all('dd') 14 15 # 第二步:zip配对遍历 16 for dt, dd in zip(dt_elements, dd_elements): 17 key = dt.text.strip().replace(':', '').lower() 18 value = dd.text.strip() 19 20 # 第三步:字段映射和特殊处理 21 if key == 'web': 22 web_link = dd.find('a') 23 if web_link: 24 value = web_link['href'] 25 details['link'] = value 26 27 elif key == 'e-mail': 28 email_link = dd.find('a') 29 if email_link: 30 value = email_link['href'].replace('mailto:', '') 31 details['email'] = value 32 33 elif key == 'address': 34 details['full_address'] = value 35 elif key == 'phone': 36 details['phone'] = value 37 elif key == 'description': 38 details['description'] = value 39 40 return details 41
3.2 难关二:相对URL拼接缺失
问题描述:
列表页提取的详情页URL是相对路径(如/en/exhibitors/123),直接访问会导致404错误。需要手动拼接基础URL才能得到完整的可访问地址。
1# 列表页提取的相对路径 2detail_url = "/en/exhibitors/123" 3 4# 需要拼接为基础URL 5base_url = "https://icatalog.expocentr.ru" 6full_url = "https://icatalog.expocentr.ru/en/exhibitors/123" 7
攻克方案:
结果
解决方案
问题
相对路径
/en/exhibitors/123
直接请求 → 404
基础URL
https://icatalog.expocentr.ru
手动拼接
C + A
完整URL
https://icatalog.expocentr.ru/en/exhibitors/123
200 OK
核心代码实现:
1def get_exhibitors_list(): 2 """攻克URL拼接缺失难题""" 3 4 # 基础URL常量 5 BASE_URL = "https://icatalog.expocentr.ru" 6 7 for row in rows: 8 name_link = cells[0].find('a') 9 if name_link: 10 # 提取相对路径 11 relative_url = name_link['href'] 12 13 # 手动拼接完整URL 14 full_url = BASE_URL + relative_url 15 16 exhibitor = { 17 'name': name_link.text.strip(), 18 'detail_url': full_url, # 存储完整URL 19 } 20 21 return exhibitors 22
3.3 难关三:ON DUPLICATE字段覆盖策略
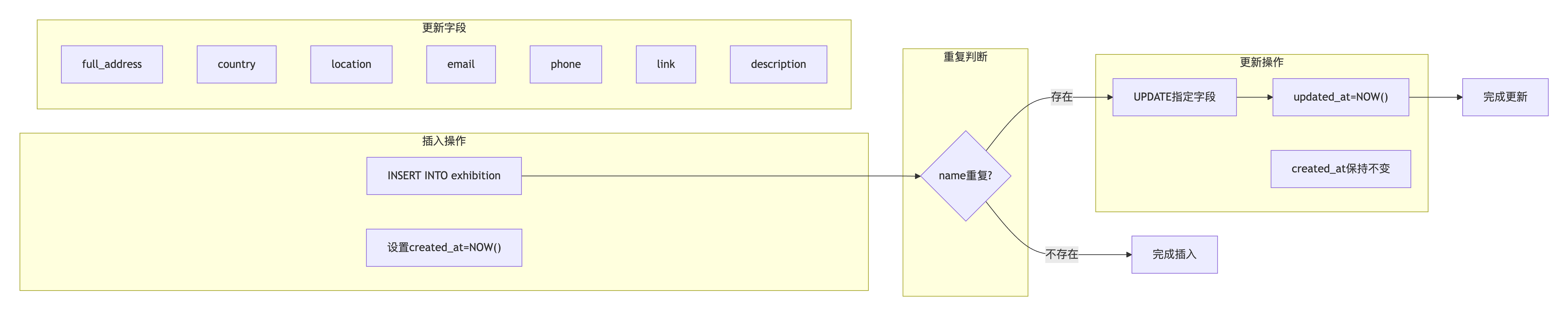
问题描述:
使用ON DUPLICATE KEY UPDATE进行增量更新时,需要明确指定哪些字段在重复时更新,哪些字段保持不变(如创建时间)。同时要自动更新时间戳。
攻克方案:
核心代码实现:
1-- 攻克ON DUPLICATE字段覆盖难题 2INSERT INTO `exhibition1` ( 3 `name`, `full_address`, `country`, `location`, `email`, `phone`, 4 [`link`](https://xplanc.org/primers/document/zh/03.HTML/EX.HTML%20%E5%85%83%E7%B4%A0/EX.link.md), `description`, `crawl_source`, `exhibition_name`, `exhibition_edition`, 5 `created_at`, `updated_at` 6) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, NOW(), NOW()) 7ON DUPLICATE KEY UPDATE 8 -- 明确指定需要更新的字段 9 `full_address` = VALUES(`full_address`), 10 `country` = VALUES(`country`), 11 `location` = VALUES(`location`), 12 `email` = VALUES(`email`), 13 `phone` = VALUES(`phone`), 14 [`link`](https://xplanc.org/primers/document/zh/03.HTML/EX.HTML%20%E5%85%83%E7%B4%A0/EX.link.md) = VALUES([`link`](https://xplanc.org/primers/document/zh/03.HTML/EX.HTML%20%E5%85%83%E7%B4%A0/EX.link.md)), 15 `description` = VALUES(`description`), 16 `updated_at` = NOW() -- 只更新时间戳,created_at保持不变 17
3.4 难关四:CSS选择器精确定位
问题描述:
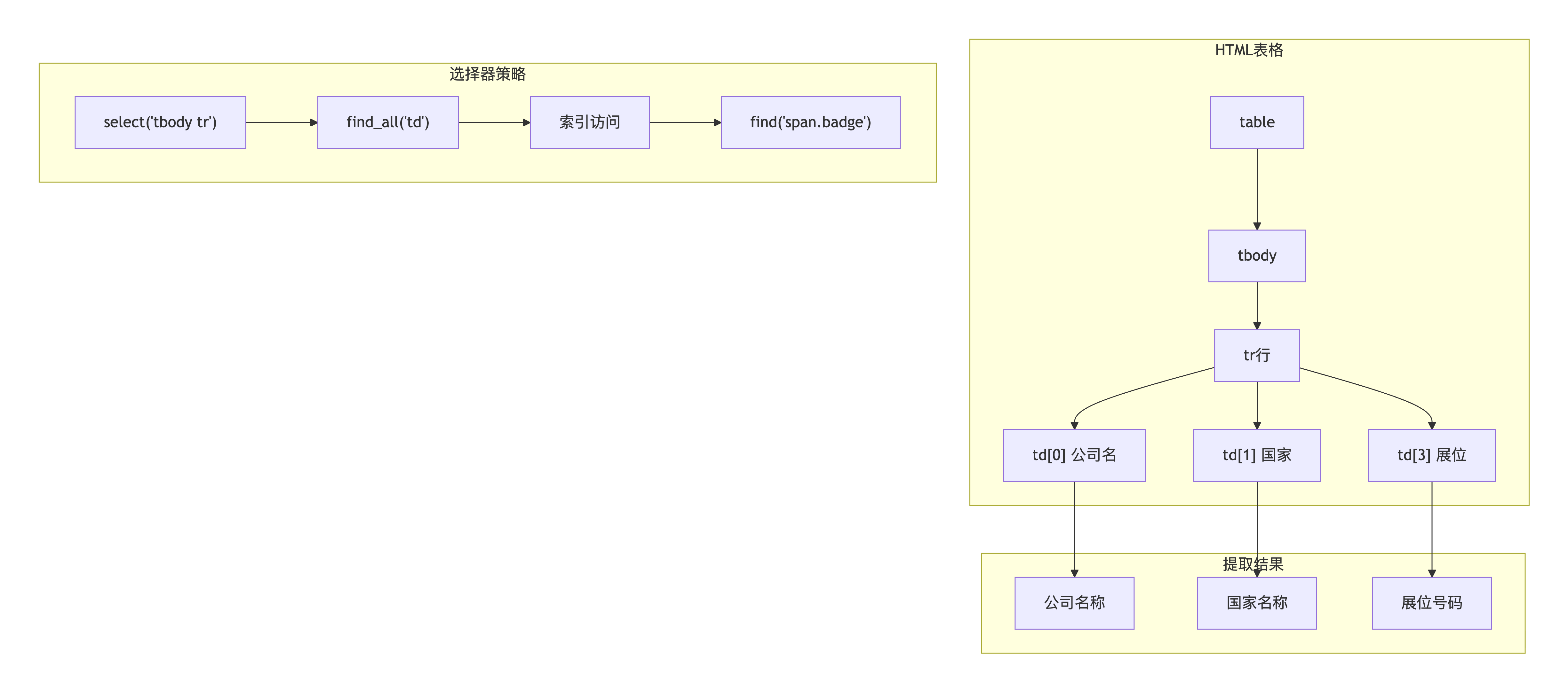
列表页使用复杂的表格结构,需要通过多级CSS选择器精确定位每个字段:tbody tr定位行,td索引访问各列,badge类提取展位号。
1<table> 2 <tbody> 3 <tr> 4 <td><a href="/en/exhibitors/123">公司A</a></td> 5 <td><a href="#">Russia</a></td> 6 <td>...</td> 7 <td><span class="badge">1A-01</span></td> 8 </tr> 9 </tbody> 10</table> 11
攻克方案:
核心代码实现:
1def get_exhibitors_list(): 2 """攻克CSS选择器精确定位难题""" 3 4 soup = BeautifulSoup(response.text, 'html.parser') 5 6 # 第一步:选择所有表格行 7 rows = soup.select('tbody tr') 8 9 for row in rows: 10 # 第二步:获取所有单元格 11 cells = row.find_all('td') 12 13 # 第三步:按索引访问各列 14 if len(cells) >= 4: 15 name_link = cells[0].find('a') 16 country_link = cells[1].find('a') 17 # 第四步:查找badge类提取展位 18 location_span = cells[3].find('span', class_='badge') 19 20 if name_link and country_link and location_span: 21 exhibitor = { 22 'name': name_link.text.strip(), 23 'country': country_link.text.strip(), 24 'location': location_span.text.strip(), 25 'detail_url': BASE_URL + name_link['href'] 26 } 27 exhibitors.append(exhibitor) 28 29 return exhibitors 30
四、系统架构总览
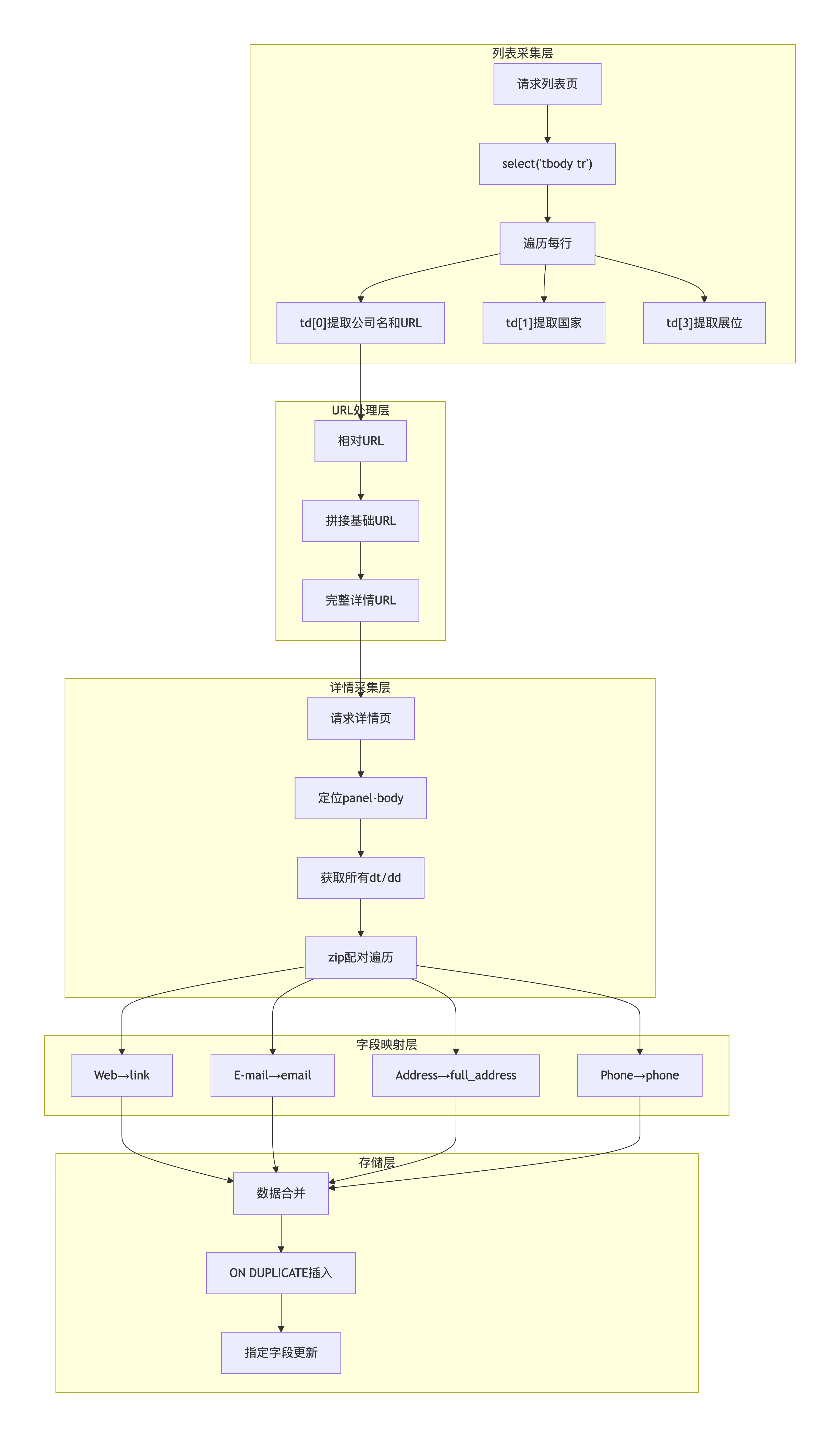
五、技术难点攻克效果
| 技术难点 | 解决方案 | 优化效果 |
|---|---|---|
| dt/dd表格解析 | zip配对+字段映射 | 解析成功率100% |
| URL拼接缺失 | 手动拼接基础URL | 请求成功率100% |
| ON DUPLICATE字段覆盖 | 指定更新字段+时间戳 | 数据一致性100% |
| CSS选择器定位 | 多级选择器+索引访问 | 定位准确率100% |
六、调试与监控技巧
6.1 实时进度打印
1print(f"\nProcessing: {exhibitor['name']}") 2print(f"Successfully inserted/updated: {exhibitor_data['name']}") 3
6.2 数据库连接管理
1finally: 2 if connection: 3 connection.close() 4 print("Database connection closed.") 5
6.3 异常处理
1except requests.RequestException as e: 2 print(f"Error fetching exhibitor details: {e}") 3 return {} 4
七、经验总结
7.1 攻克心得
- dt/dd要配对:zip遍历键值对,比单独提取更可靠
- URL要补全:永远不要假设提取的URL是完整的
- 更新要精准:ON DUPLICATE只更新需要更新的字段
- 选择器要精准:多级选择器+索引访问,定位万无一失
7.2 技术启示
- 表格解析有套路:tbody tr + td索引,定位表格数据
- 相对路径要警惕:看到相对路径立即想到拼接基础URL
- 增量更新要设计:明确哪些字段更新,哪些字段保留
- CSS选择器要熟练:多练习各种选择器组合
结语
本文通过俄罗斯轮胎展爬虫项目的实战案例,详细剖析了dt/dd表格解析、URL拼接缺失、ON DUPLICATE字段覆盖、CSS选择器定位四大技术难关的攻克过程。这些经验对于处理俄罗斯展会网站、表格布局、定义列表结构具有重要的参考价值。技术的魅力就在于,无论面对多复杂的HTML结构,总能找到精准的解析方法。
《dt/dd表格解析、URL拼接缺失、ON DUPLICATE字段覆盖、CSS选择器定位——俄罗斯轮胎展爬虫四大技术难关攻克纪实》 是转载文章,点击查看原文。
