第一题
题目:
使用正则完成下列内容的匹配
- 匹配陕西省区号 029-12345
- 匹配邮政编码 745100
- 匹配邮箱 lijian@xianoupeng.com
- 匹配身份证号 62282519960504337X
代码:
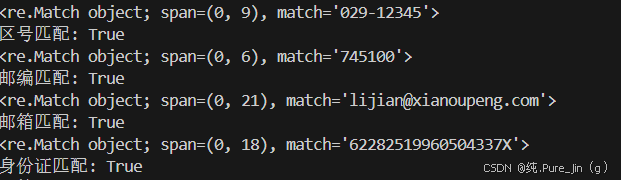
1import re 2# 1. 匹配陕西省区号 029-12345 3pattern_area = r'^029-\d{5}$' # 精确匹配 029- 开头,后接5位数字 4test_area = '029-12345' 5print("区号匹配:", re.match(pattern_area, test_area) is not None) 6 7# 2. 匹配邮政编码 745100 8pattern_post = r'^\d{6}$' # 精确匹配6位数字 9test_post = '745100' 10print("邮编匹配:", re.match(pattern_post, test_post) is not None) 11 12# 3. 匹配邮箱 lijian@xianoupeng.com 13pattern_email = r'^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$' 14test_email = 'lijian@xianoupeng.com' 15print("邮箱匹配:", re.match(pattern_email, test_email) is not None) 16 17# 4. 匹配身份证号 62282519960504337X 18pattern_id = r'^\d{17}[\dXx]$' # 17位数字 + 1位数字或X/x 19test_id = '62282519960504337X' 20print("身份证匹配:", re.match(pattern_id, test_id) is not None) 21
运行结果:
第二题
题目:
爬取学校官网,获取所有图片途径并将路径存储在本地文件中,使用装饰器完成
代码:
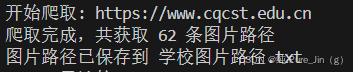
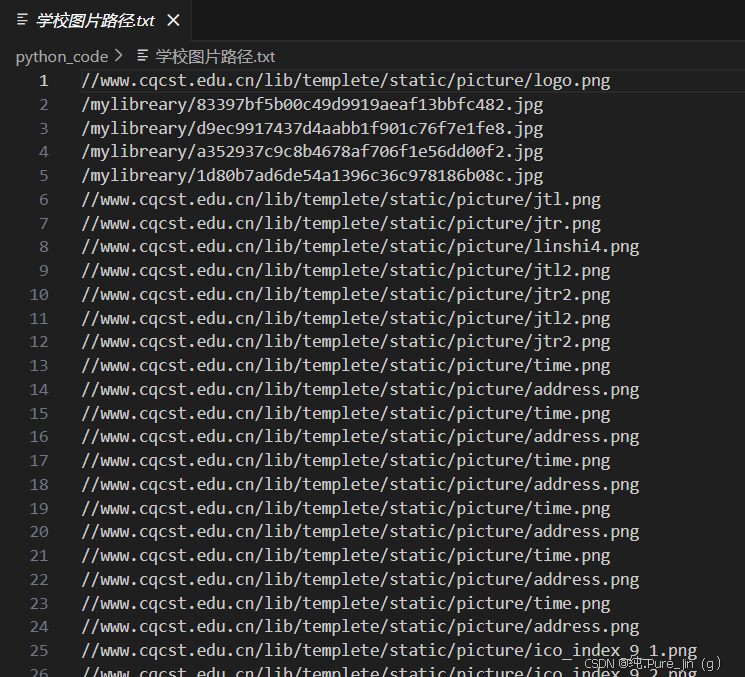
1import requests 2import re 3 4# 装饰器:记录爬取任务 5def log_crawl_task(func): 6 def wrapper(url): 7 print(f"开始爬取: {url}") 8 result = func(url) 9 print(f"爬取完成,共获取 {len(result)} 条图片路径") 10 return result 11 return wrapper 12 13# 爬取函数 14@log_crawl_task 15def crawl_school_images(url): 16 try: 17 # 基础请求配置,避免被反爬 18 headers = {"User-Agent": "Mozilla/5.0"} 19 response = requests.get(url, headers=headers, timeout=10) 20 response.encoding = "utf-8" # 确保中文路径不乱码 21 22 # 正则提取img标签的src属性 23 img_paths = re.findall(r'<img src="(.*?)"', response.text) 24 return img_paths 25 except Exception as e: 26 print(f"爬取失败: {str(e)}") 27 return [] 28 29# 保存路径到本地文件 30def save_image_paths(paths): 31 with open("学校图片路径.txt", "w", encoding="utf-8") as f: 32 f.write("\n".join(paths)) 33 print("图片路径已保存到 学校图片路径.txt") 34 35# 调用示例 36if __name__ == "__main__": 37 school_url = "https://www.cqcst.edu.cn" 38 image_paths = crawl_school_images(school_url) 39 if image_paths: 40 save_image_paths(image_paths) 41 else: 42 print("未获取到任何图片路径") 43
运行结果:
《【Python练习五】Python 正则与网络爬虫实战:专项练习(2道经典练习带你巩固基础——看完包会)》 是转载文章,点击查看原文。


