简介
本文介绍清华大学语音处理与机器智能实验室(Speech Processing and Machine Intelligence, SPMI)与美团的联合工作 — CUSIDE:分块、模拟未来、解码的流式语音识别新框架,刷新了目前Aishell-1上 流式模型的SOTA(State Of The Art, 最好结果)。该工作已被语音领域的国际会议Interspeech2022接收,论文的作者是安柯宇、郑华焕、欧智坚、向鸿雨、丁科、万广鲁。

论文链接:
http://oa.ee.tsinghua.edu.cn/\~ouzhijian/pdf/cuside-intespeech2022-camera.pdf

流式语音识别
流式语音识别,是指在说话人讲话的同时进行识别,而不是等到说话人讲完整句话后再开始识别。然而,目前业界常用的神经网络结构,例如基于自注意力机制的transformer和conformer,通常使用整句作为输入,因此不适用于低延迟语音识别。为了解决这一问题,很多系统采用了分块(chunk)的模型。具体而言,一句话会被切分为多个块,然后再送入神经网络逐块进行识别,这样就将延迟降低为一个块的长度。
上下文感知块
在基于块的低延迟语音识别模型中,一个常见做法是为每个块附加一定的历史帧和未来帧,以提供上下文信息,构成上下文感知块(context sensitive chunk)。已有的工作表明,上下文信息对精确的声学建模至关重要,上下文信息的缺失将造成10%以上的识别准确率损失。但是,为了获取未来信息,模型必须等到一定数量的未来帧到达后再开始识别,这显著增加了识别延迟。为了解决这一问题,该论文提出了一种基于分块、预测未来、解码(Chunking, Simulating future context and Decoding,CUSIDE)的低延迟语音识别框架。
CUSIDE
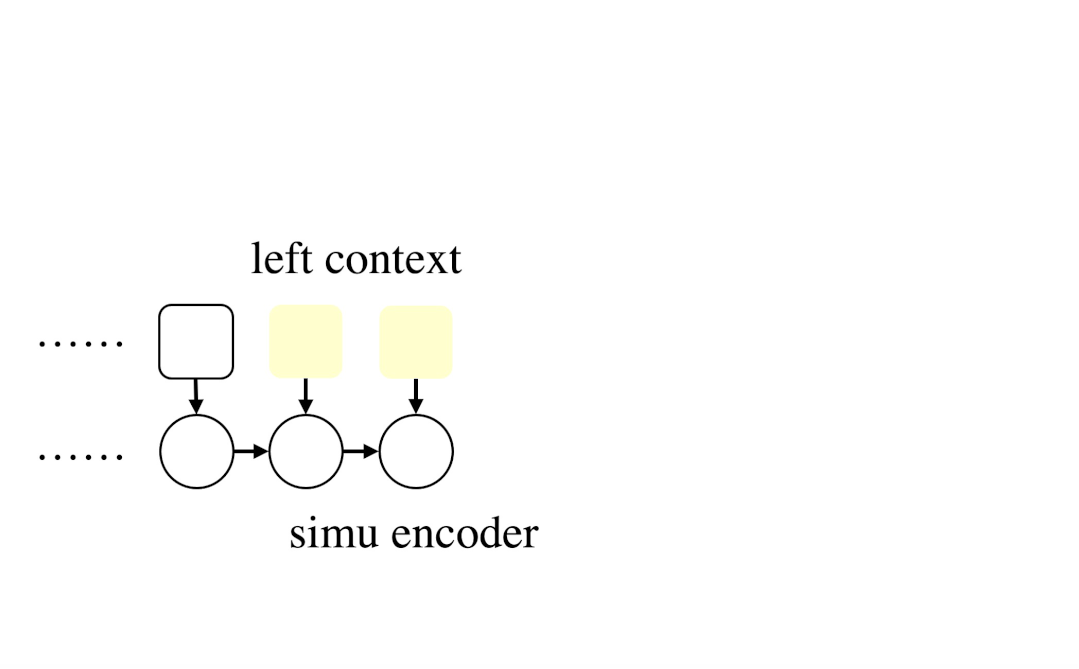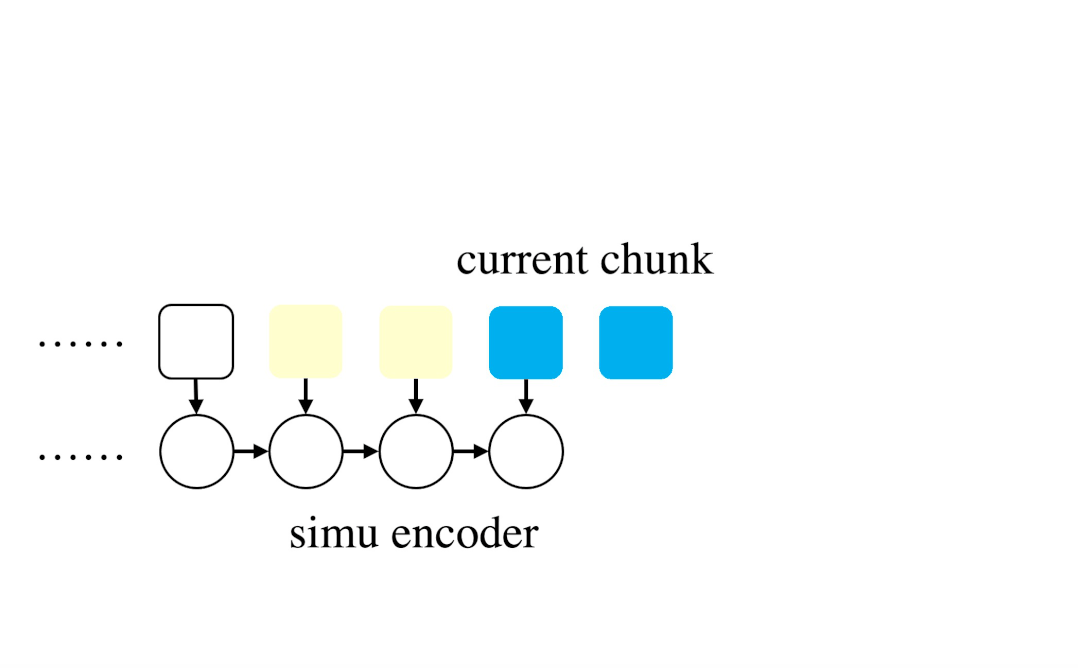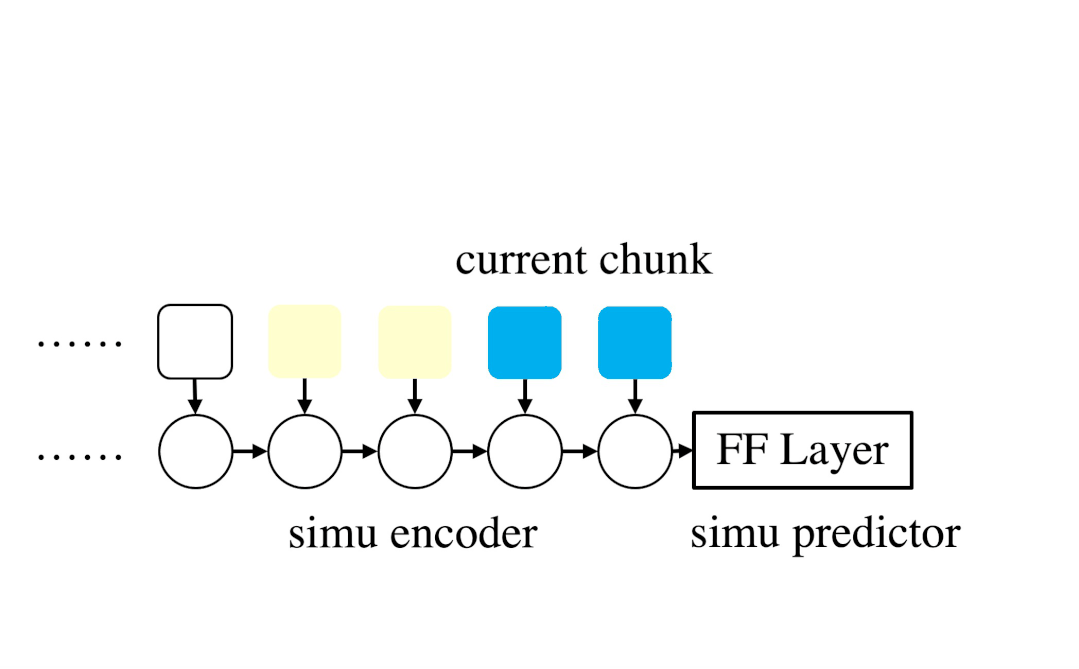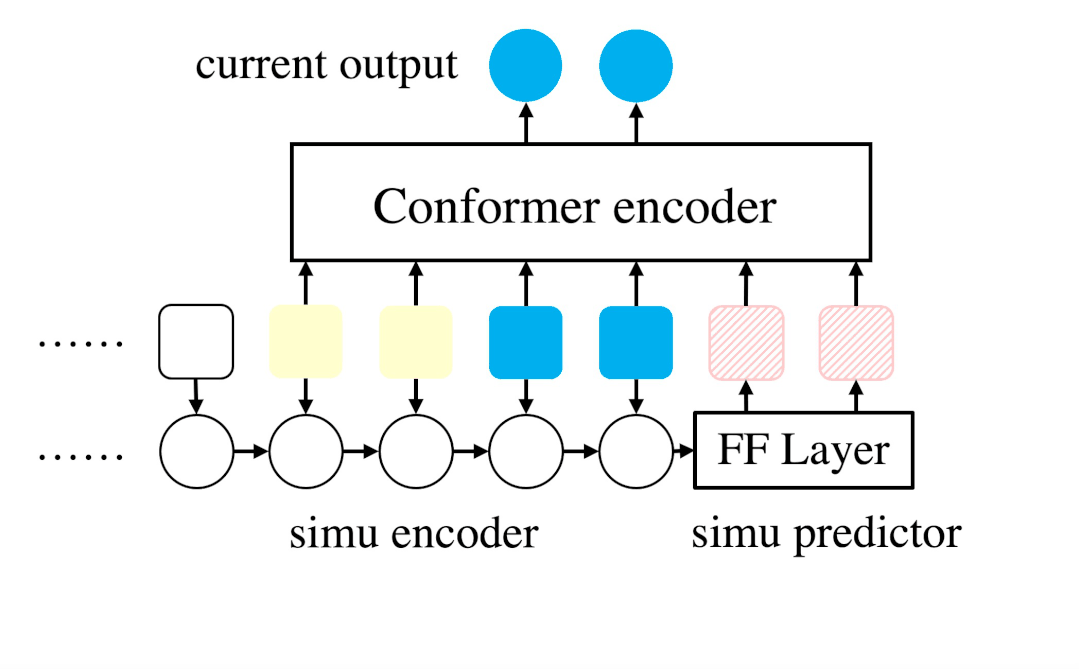
CUSIDE模型的核心思想是,使用模拟的未来帧而不是真实未来帧来构建上下文感知块,由此可以免除对未来信息的依赖,减小识别延迟。具体来说,CUSIDE使用一个合成器以流式的方式生成模拟帧。该合成器由合成编码器和合成预测器构成,合成编码器是一个循环神经网络(在该文的实验中是一个三层单向GRU模型),用于对输入帧进行编码,合成预测器以合成编码器的隐状态作为输入,输出一定数量的预测未来帧。合成器可以以无监督方式进行训练(因为将输入帧向前移动即可得到对应的预测目标,这里受到了无监督表征学习方法APC的启发),不需要额外的标注信息。此外,CUSIDE还通过训练中块大小抖动(chunk size jitter)、流式/非流式模型共享参数和联合训练等方法(unified streaming/non-streaming model),进一步提高了流式模型的识别准确率,减小了流式模型和非流式模型之间的性能差距。
结果
该论文主要在Aishell-1数据集上进行了实验评测。声学模型是一个使用12层Conformer神经网络的CTC-CRF模型,基于CAT工具包实现。解码使用一个3gram WFST。chunk大小设置为400ms,历史帧和预测未来帧长度分别设置为800ms和400ms。CUSIDE与其他流式模型的结果对比见下表。
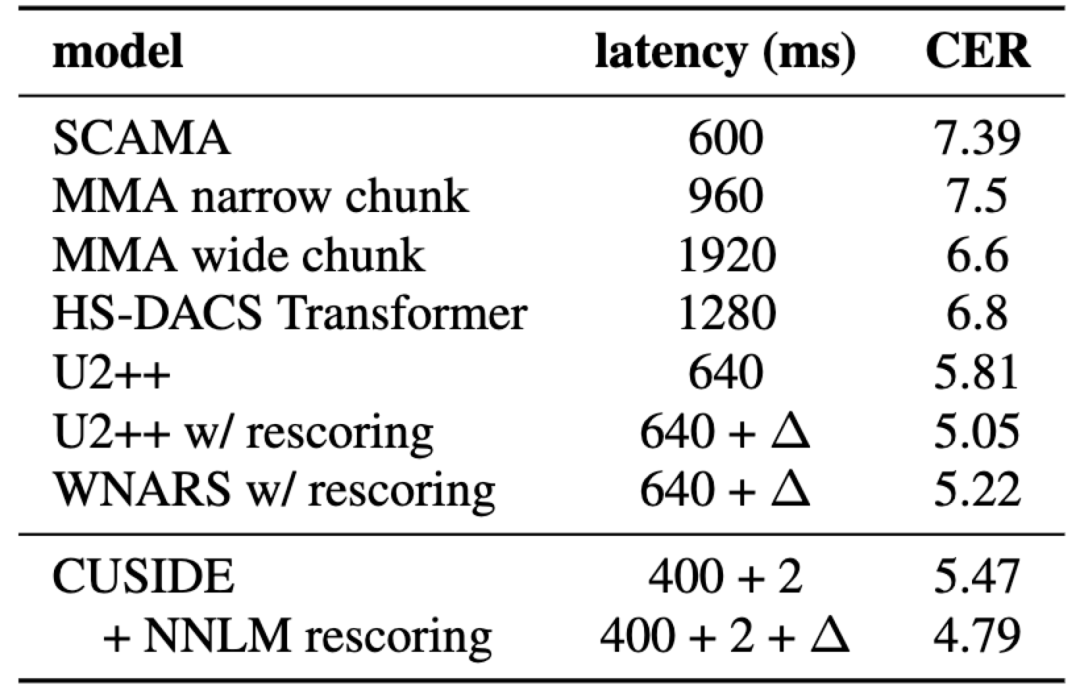
一般将latency定义为chunk的长度。表格中的Δ是rescoring所用的时间,一般在100ms以内。CUSIDE模型中额外的2ms代表了模拟未来帧所用的时间。可以看到,基于CTC-CRF的CUSIDE模型在低延时下取得了最好的识别准确率,4.79也是目前Aishell-1上 流式模型的 最好结果 。
需要说明的是,CUSIDE并不局限于CTC-CRF模型。不难看出,CUSIDE可以方便地用于其他语音识别模型,例如RNN-T和LAS。CUSIDE将于近期在CAT工具包开源发布,敬请关注!
CAT工具包链接:https://github.com/thu-spmi/CAT

《Interspeech2022论文解读 | CUSIDE:一个流式语音识别新框架,刷新SOTA》 是转载文章,点击查看原文。


