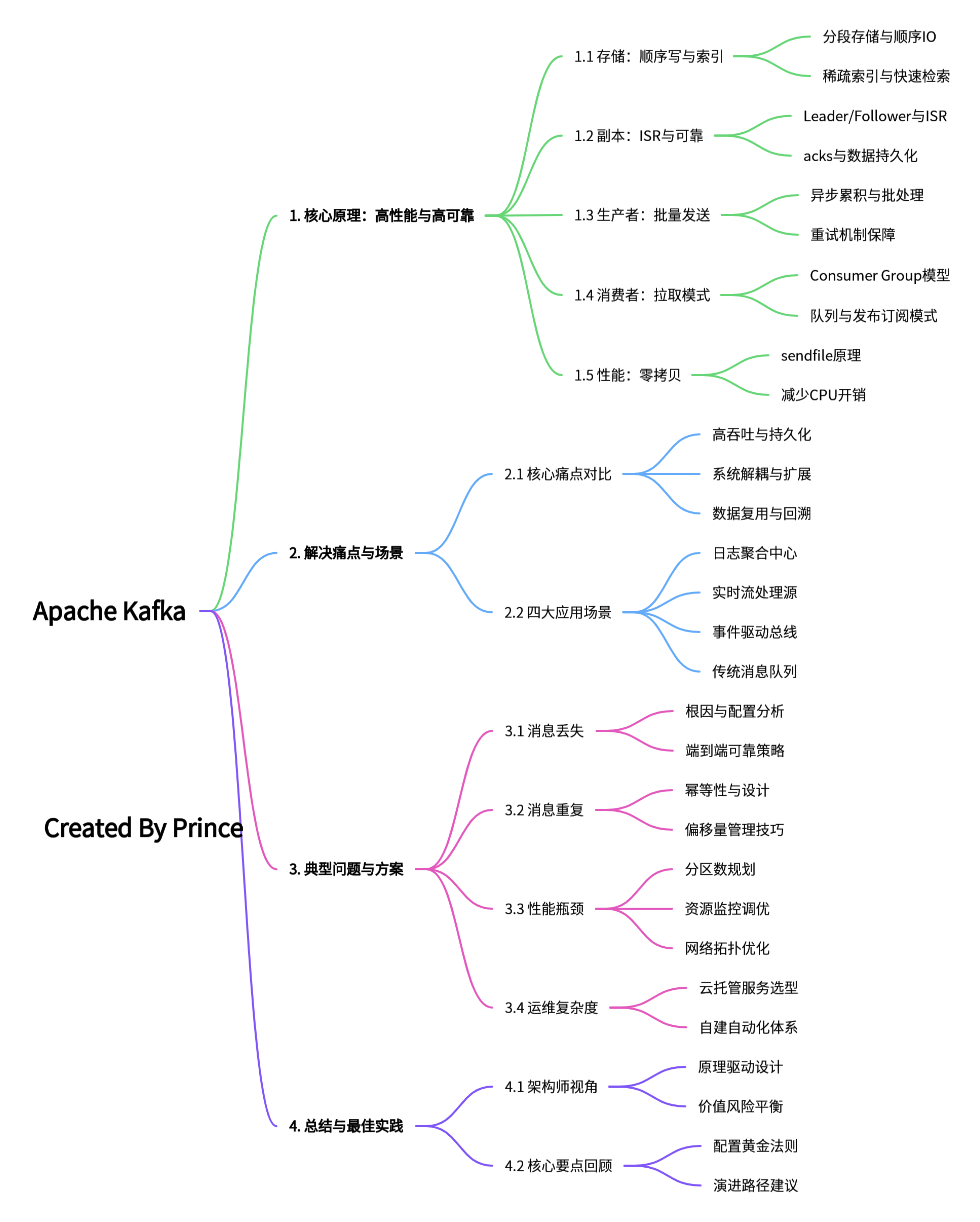
1. Kafka 知识脑图
2. Kafka 整体架构
首先,我们通过一张总览图来建立对Kafka生态系统的整体认知。这张图描绘了数据从生产到消费的完整路径,以及各核心组件之间的协作关系:
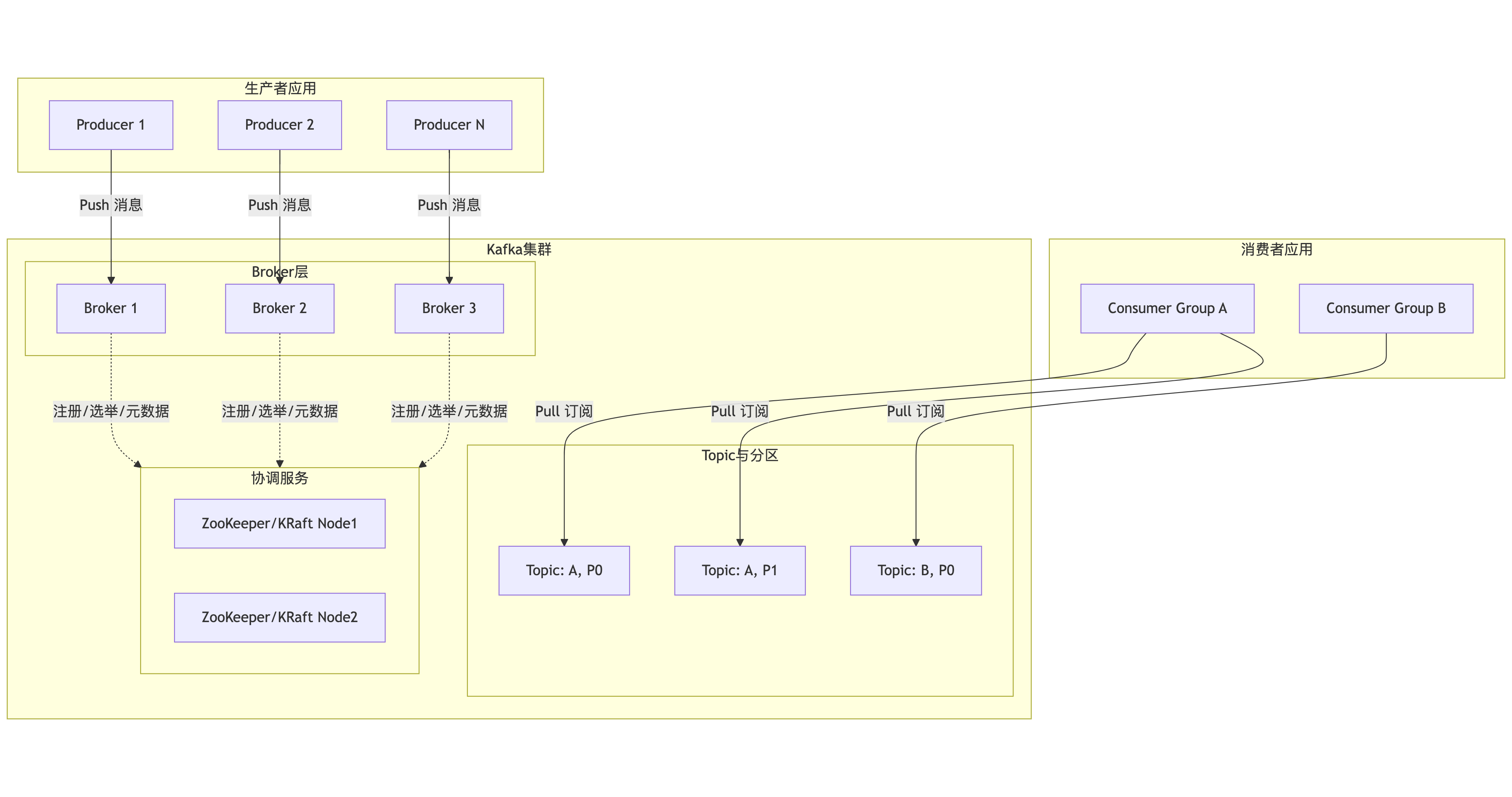
架构图解读:
- 数据流向:生产者(Producer)将消息推送(Push) 到Broker集群;消费者(Consumer)以拉取(Pull) 方式从Broker订阅消息。这种设计让消费者能根据自身处理能力控制速率,实现天然背压。
- 核心角色:
- Broker:Kafka服务节点,负责消息存储、传输和集群协调。
- Topic & Partition:Topic是逻辑分类,每个Topic被分为多个Partition(分区),这是实现水平扩展和并行处理的基石。
- 协调服务:早期依赖ZooKeeper管理集群元数据、Leader选举等。新版本采用KRaft模式,将元数据管理内置于Kafka自身,简化了架构。
- 消费者组(Consumer Group):这是实现“队列模式”与“发布-订阅模式”的关键。组内消费者协同消费,一个分区只能被组内一个消费者消费,从而实现负载均衡;不同消费者组则可独立消费全量消息,实现广播。
3. Kafka的核心实现原理
Kafka的卓越表现并非偶然,而是其一系列精巧设计共同作用的结果。其核心原理可以概括为:以分区(Partition)为并行单元,以顺序追加日志(Append-Only Log)为存储模型,通过副本机制(Replication)保障可靠性,并辅以多项性能优化技术。
3.1 顺序读写与高效检索
Kafka的消息持久化在磁盘上,但其性能却远超传统数据库,关键在于顺序IO。每个Partition在物理上对应一个目录,内部由一系列分段(Segment)文件组成。新消息永远只追加到当前活跃Segment的末尾,这种纯粹的顺序写操作是磁盘最快的工作模式,速度可比随机读写快上百倍。
为了快速定位消息,Kafka采用了“稀疏索引”机制。每个.log数据文件对应一个.index索引文件。索引并不记录每条消息的位置,而是每隔一定数据量建立一条索引条目(包含相对偏移量和物理位置)。查找时,先通过二分法确定消息所在的Segment,再在内存中的索引文件里进行二分查找,找到最接近的索引条目,最后在.log文件中只需做一次很小的顺序扫描即可定位目标消息。这种设计避免了索引文件过大,同时保证了高效的查询性能。
3.2 ISR
Kafka的高可用和数据可靠性依赖于其副本机制。每个Topic的Partition都有多个副本(Replica),分散在不同Broker上。其中一个副本被选为Leader,负责处理所有读写请求;其他副本作为Follower,从Leader异步拉取数据进行同步。核心在于ISR(In-Sync Replicas) 列表的管理。ISR是当前与Leader保持“同步”的副本集合(必定包含Leader)。一个Follower要被认为“同步”,需满足:1)与ZooKeeper保持心跳;2)其复制进度不能落后Leader太多(由参数replica.lag.time.max.ms控制)。
生产者(Producer)可以配置acks参数来决定消息的持久化强度:
acks=0:发送即认为成功,性能最高,可靠性最低。acks=1:Leader写入本地日志即返回成功。acks=all(或-1):需要等待Leader将消息复制到所有ISR副本并确认后,才返回成功。这是保证数据不丢失的关键配置。
Kafka通过动态管理ISR,在数据可靠性和写入延迟之间取得了巧妙平衡。它既不是强同步(等待所有副本),也不是纯异步,而是确保消息在“足够多”(ISR内)的副本上持久化后才确认,从而在多数情况下避免数据丢失。
3.3 生产者与消费者
- 生产者端:采用异步批量发送机制。消息并非逐条发送,而是先在客户端缓冲区(RecordAccumulator)中累积,达到一定大小(
batch.size)或时间(linger.ms)后,批量发送给Broker。这极大地减少了网络IO次数,是达成高吞吐量的关键。同时,生产者支持重试(retries)机制,以应对网络抖动等临时故障。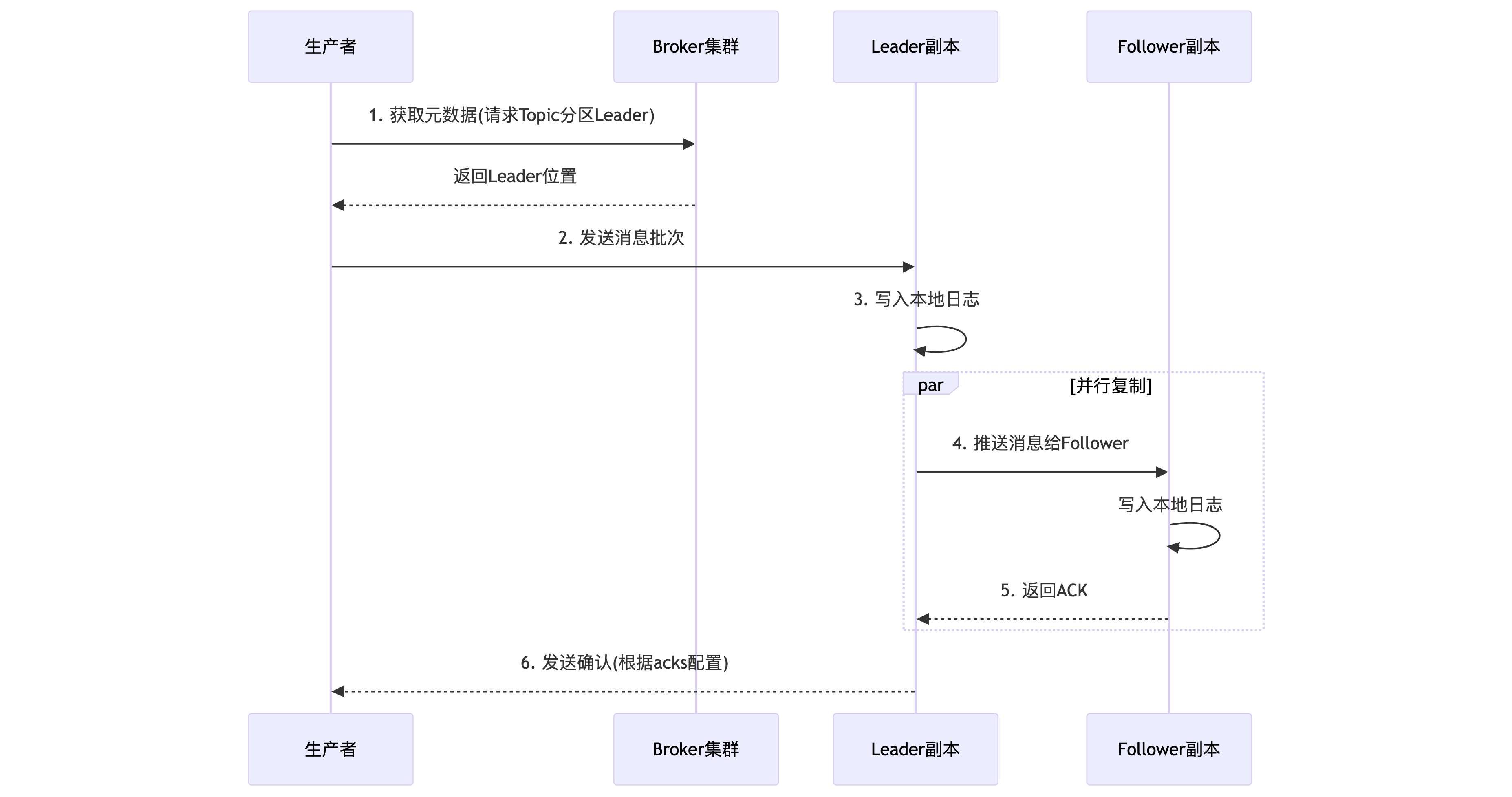
- 消费者端:采用主动拉取(Pull)模型。消费者按自己的处理能力从Broker拉取消息,天然具备背压(Backpressure)能力。消费者必须属于一个消费者组(Consumer Group)。Kafka通过消费者组实现了两种经典模式:
- 队列模式:同一消费者组内的多个消费者,共同消费一个Topic,每条消息只会被组内的一个消费者消费。具体分配原则是:一个Partition在同一时刻只能被同一个消费者组内的一个消费者消费。因此,消费者的最大并行度受限于Topic的Partition数量。
- 发布/订阅模式:不同消费者组可以独立消费同一个Topic的全量消息,实现消息的广播。
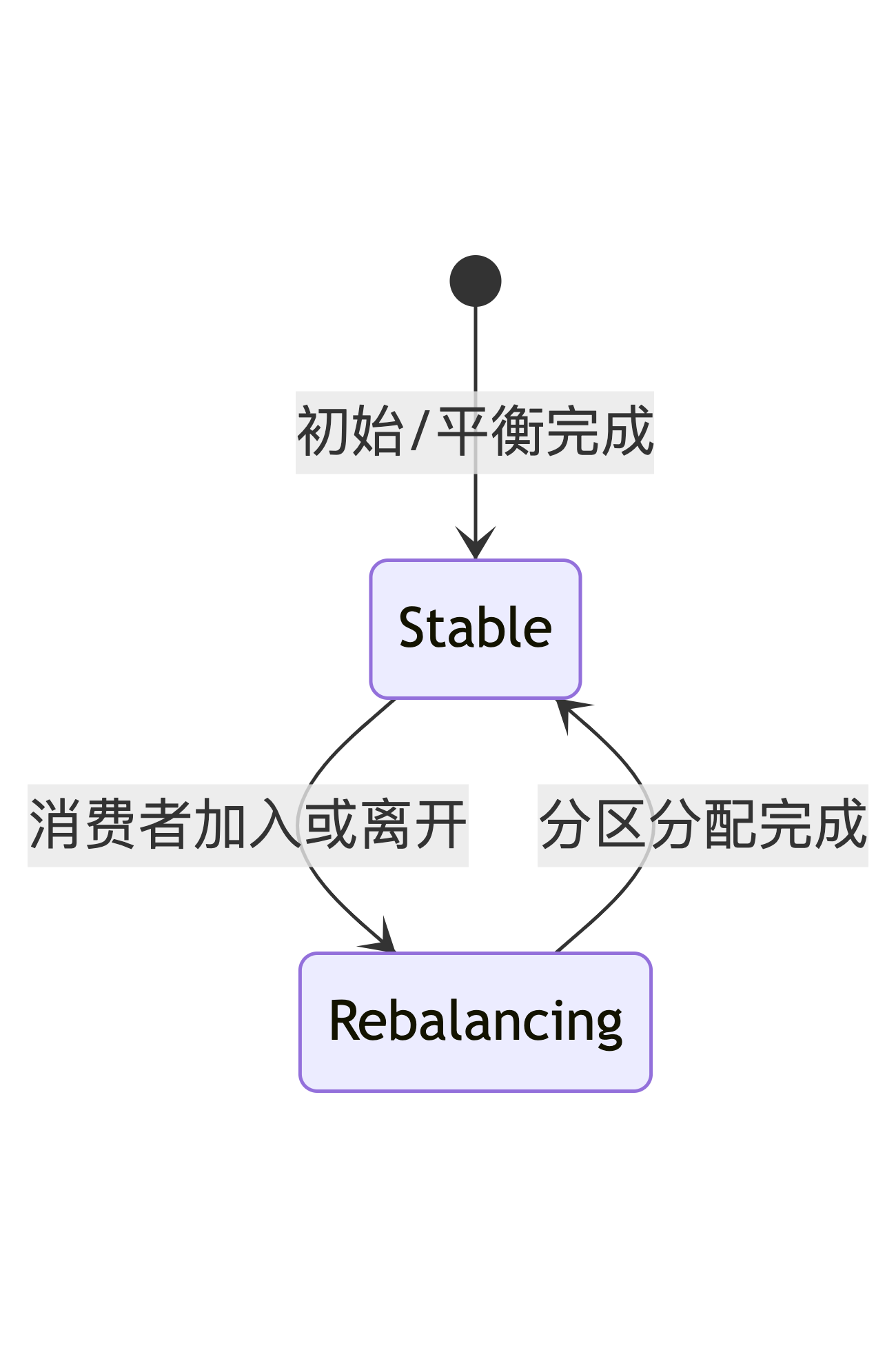
- Rebalance:当消费者数量变化时,会触发rebalance机制,保障所有消息都能被消费。
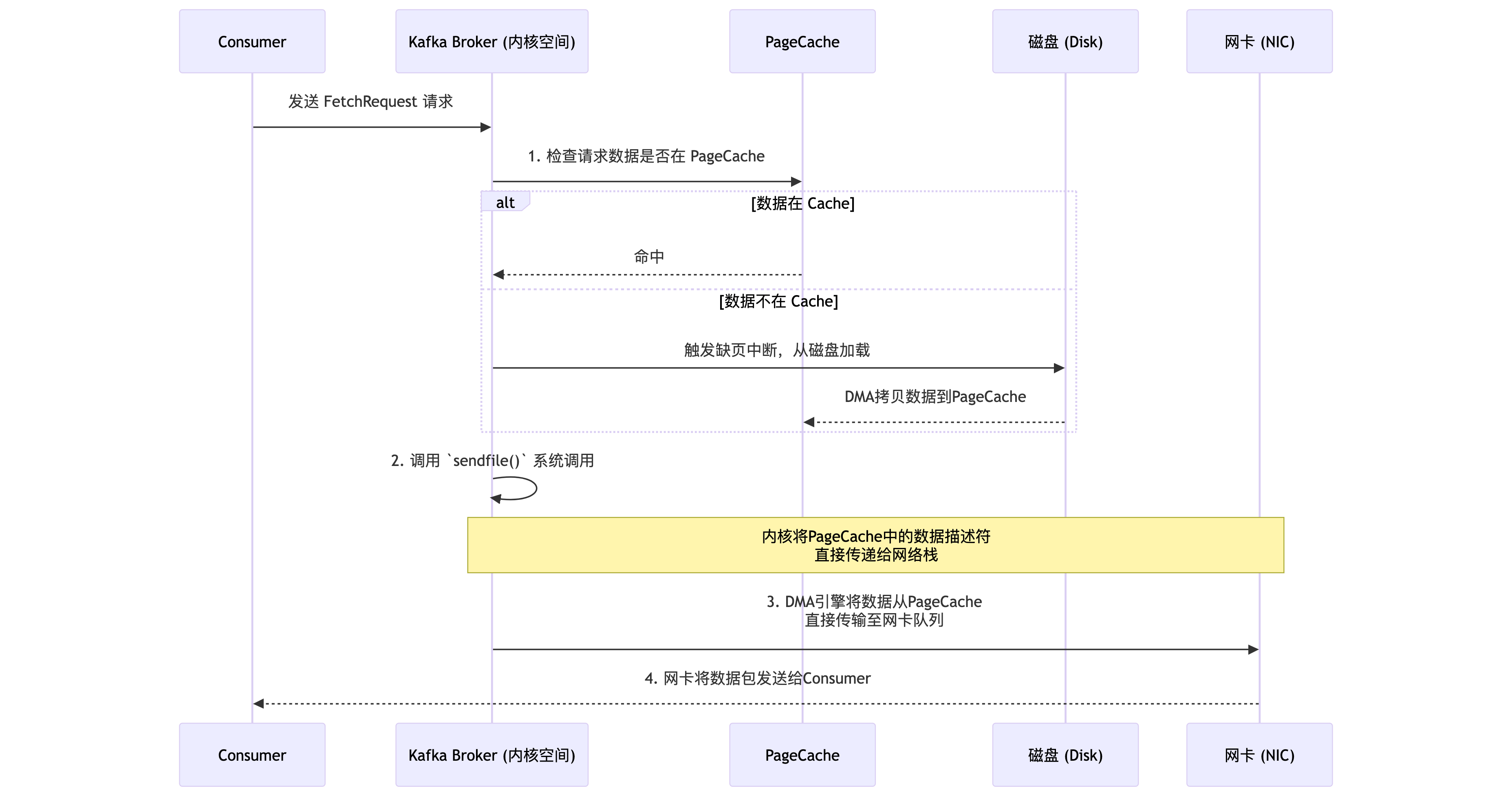
3.4 零拷贝(Zero-Copy)
这是Kafka在Broker端减少数据拷贝开销的核心技术。在传统的数据从磁盘发送到网络的过程中,数据需要在操作系统内核空间和用户空间之间多次拷贝。Kafka利用Linux的sendfile()系统调用,实现了零拷贝:数据直接从磁盘文件(通过PageCache)拷贝到网卡缓冲区,无需经过应用程序内存。这大幅降低了CPU开销和上下文切换,提升了网络传输效率。
4. Kafka解决的痛点与对应使用场景
Kafka的设计初衷就是为了解决传统消息中间件在大数据、实时性场景下的不足。
4.1 核心解决的痛点
- 高吞吐与海量数据积压:传统消息队列(如RabbitMQ、ActiveMQ)设计目标更侧重于低延迟和复杂路由,其吞吐量通常在每秒数万级。而Kafka通过顺序IO、批处理和零拷贝,轻松实现每秒百万级消息的吞吐,能够承接互联网级别的数据洪流。
- 数据持久化与复用:传统队列消息消费后通常被删除。Kafka将所有消息持久化到磁盘,并保留一段时间(可配置),允许消费者重复消费、回溯消费,也方便流处理系统进行重复计算。
- 系统解耦与扩展性:作为消息总线,Kafka彻底解耦生产者和消费者,双方可独立扩展和演进。其分布式架构使得通过增加Broker即可线性扩展存储能力和处理能力。
4.2 典型使用场景
- 日志收集与聚合:这是Kafka最经典的应用。将各服务节点产生的日志统一推送至Kafka,下游再对接Elasticsearch、HDFS或实时计算平台,实现集中式的日志管理、监控和审计。
- 实时流处理(Stream Processing):Kafka作为流处理平台(如Apache Flink、Spark Streaming)的可靠数据源。实时交易数据、用户点击流、IoT设备数据先写入Kafka,再由流处理任务进行实时风控、实时推荐、实时仪表盘计算等。
- 事件驱动架构(EDA):在微服务体系中,Kafka作为事件中心。服务将状态变更以事件形式发布到Topic,其他订阅该事件的服务异步接收并处理,实现服务间的松耦合、异步通信和最终一致性。
- 消息队列:用于传统的异步任务处理、削峰填谷。例如,电商下单后,将订单消息发往Kafka,由下游的库存服务、物流服务异步消费处理,缓解高峰时段对核心交易链路的压力。
5. 常见问题与架构师解决方案
即便设计优秀,在实际运维中仍会面临挑战。以下是几个关键问题及应对策略:
5.1 消息丢失
- 问题描述:生产者认为发送成功,但消费者从未读到;或因Broker故障导致已存储数据丢失。
- 根因分析:
- 生产者配置
acks=0或acks=1,在Leader副本写入后未等Follower同步即返回成功,若此时Leader宕机且数据未同步,则丢失。 - Broker端
min.insync.replicas设置为1,即使配置acks=all,也允许在仅有一个副本(Leader)在ISR时写入,风险高。
- 生产者配置
- 解决方案:
- 生产者配置:务必设置
acks=all,并启用重试retries=3(或更高)。 - Broker配置:根据副本因子(如3)合理设置
min.insync.replicas=2。这意味着至少需要2个副本(包括Leader)确认,写入才成功,在容忍一个副本故障的同时保证数据不丢。 - 消费者配置:关闭自动提交偏移量(
enable.auto.commit=false),在处理完消息后手动同步提交偏移量(commitSync())。
- 生产者配置:务必设置
5.2 消息重复消费
- 问题描述:消费者重启或异常后,部分消息被再次处理。
- 根因分析:消费者在消费消息后、提交偏移量(Offset)前发生崩溃或重平衡(Rebalance)。当它恢复后,会从上次提交的Offset开始消费,导致未提交Offset的消息被重复处理。
- 解决方案:
- 实现消费幂等性:这是根本解决方案。在消费者业务逻辑中,确保对同一消息的多次处理结果一致(例如,通过数据库唯一键、Redis setnx等)。
- 谨慎管理Offset:如前所述,采用手动同步提交。或缩短自动提交间隔
auto.commit.interval.ms,但无法完全避免。
5.3 性能瓶颈与资源问题
- 问题描述:吞吐量不达预期、磁盘写满、CPU或网络成为瓶颈。
- 根因分析与解决:
- 分区数不足:Topic的并发处理能力受限于分区数。若消费者吞吐量不足,可适当增加分区数,以允许更多的消费者并行处理。但分区数并非越多越好,过多会导致元数据膨胀和更频繁的重平衡。
- 磁盘写满:Kafka会因磁盘满而停止服务。需合理配置日志保留策略(
log.retention.hours和log.retention.bytes),并设置监控告警。 - 网络带宽与跨机房延迟:副本同步(特别是跨机房)会占用大量带宽并引入延迟。可通过配置
broker.rack让Kafka优先在同机架(机房)内选择副本,优化同步路径。
5.4 运维复杂性
- 问题描述:自建Kafka集群需要深度维护Broker、ZooKeeper、监控、扩缩容、安全等,对团队要求高。
- 解决方案:
- 采用托管服务:如阿里云消息队列Kafka版等云服务,提供开箱即用、免运维、自动扩缩容、更高SLA保障(如99.99%可用性、8个9的数据可靠性)的能力,让团队更专注于业务开发。
- 标准化与自动化:若坚持自建,需建立完善的部署模板、监控告警体系(关注Broker负载、ISR变化、网络流量、磁盘IO等)和自动化运维流程。
《技术架构系列 - 详解Kafka》 是转载文章,点击查看原文。


