CNN简介
卷积神经网络就是一个包括卷积层和池化层的神经网络,主要应用于计算机视觉方面,应用场景包括图像分类、目标检测、面部解锁、自动驾驶等。
整体架构流程
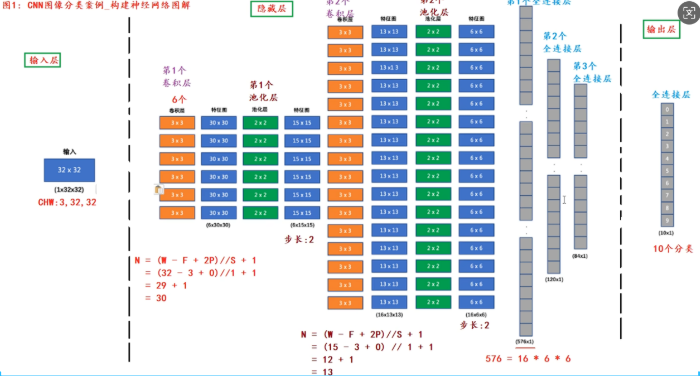
CNN的主要结构为 输入层,隐藏层 和输出层,主体架构主要体现在隐藏层中的网络,依次为卷积层 池化层 然后全连接层直接输出。CNN分别进行了两场卷积和池化 ,最终通过三个全连接层进行输出。
卷积层结构图
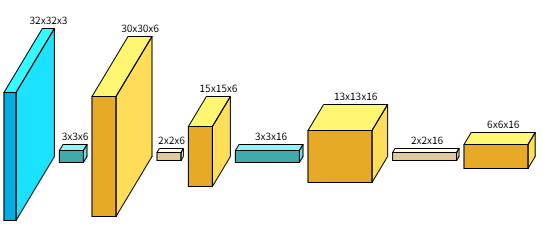
1input(32, 32, 3) 2conv(3, 3, 6) 3relu(30, 30, 6) 4pool(2, 2, 6) 5relu(15, 15, 6) 6conv(3, 3, 16) 7relu(13, 13, 16) 8pool(2, 2, 16) 9relu(6, 6, 16)
ConvNetDraw(支持在线)是生成这个图片的网站。
ConvNetDraw是一个使用配置命令的CNN神经网络画图工具;需要了解神经网络结构和代码,就很简单啦!结果可保存为图片。
优点:绘制结果为3D,可简单调整x,y,z这3个维度;
缺点:单一、传统、能满足基础需求
图像概念
基于CNN项目的讲解需要首先引入图像概念方面的知识,在计算机视觉方面图像大致分为四种分类。
- 二值图像 :只有0/1 通道为1
- 灰度图像:数值范围为0-255,通道数为1
- 索引图象:存储索引,索引对应二维矩阵行下标->RGB 通道为1
- RGB 图像:数值为0-255 通道为3
图像的格式为(H W C)格式对应的为图像的长宽和通道数,但是在卷积神经网络中为了优化网络的运算过程,需要将原有的 (H W C)格式转化为(C H W)格式进行输入。图像是通过1个二维矩阵或3个二维矩阵表示的,常用的操作在于图像的读取imread(),输出imshow(),保存imsave(),图像中的矩阵值就是图像的像素点也是网络中所需要的特征值。
卷积层
卷积层是卷积神经网络的鲜明特点,它的主要错用是提取图像中的特征,这也是神经网络与传统机器学习算法的不同,不需要再进行人工的筛检和手动的输入特征值。
卷积核
卷积核(Convolution Kernel) 是卷积神经网络中的权重矩阵,用于在输入数据上滑动执行卷积运算,以提取特征。卷积核带有共享参数的神经元,有多少卷积核就是有多少个神经元。
卷积的基本运算
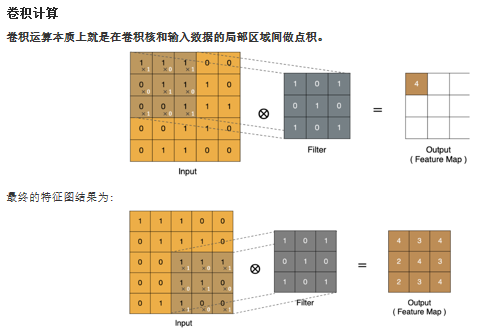
卷积的运算过程就是,在特征图上获取一个与卷积核大小相同的窗口矩阵,然后将窗口矩阵内的数值与卷积核进行点乘运算,最后将结果相加进行输出,计算完成后将区域按照步长进行移动,依次进行运算。这种运算过程中会使得特征图的变小,且处于特征图边缘的特征图上的数值获取的次数较少,容易造成特征值的丢失,所以引入了padding,对特征图进行填充,在特征图的边缘填充上了全0的数值,使得卷积过后的新特征图与原特征图形状保持一致。
多通道的卷积计算
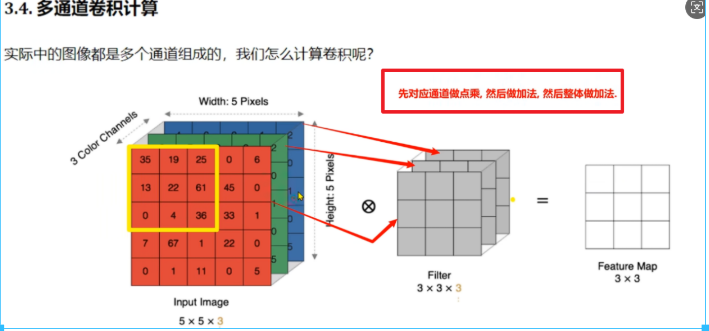
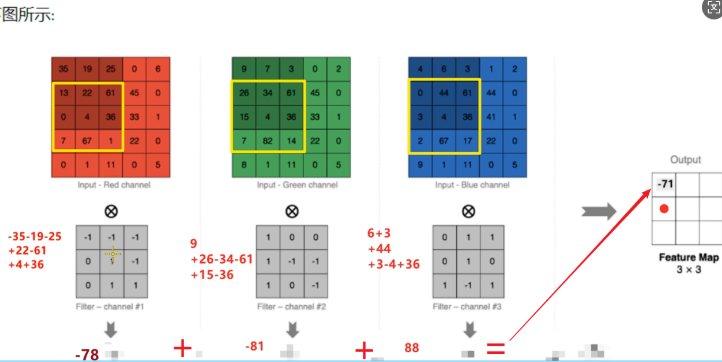
我们进行计算机视觉项目的时候,常常使用的是彩色图像,也是通常说的RGB图像,它有三个通道,所以在进行卷积计算的时候,它所对应的卷积核也有三个通道,每个通道与对应的卷积核进行点乘结果,然后将结果进行求和,输出到新的特征图上,也是将通道数进行了压缩,从原有的三通道变为了1通道。
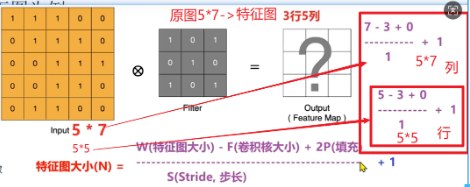
计算特征图的大小 特征图的大小 N=floor((W-F+2P)//S+1)
W:原特征图大小 , F:卷积核大小,P:补零圈数,S:步长
卷积层参数计算
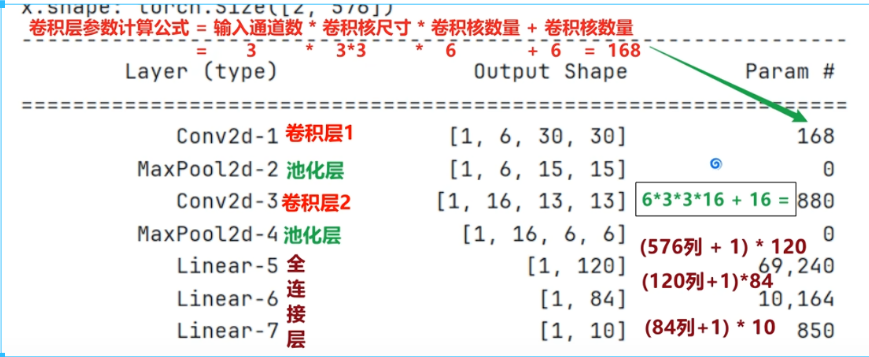
1#这个代码是main函数中的代码 2#获取数据 3train_dataset, valid_dataset, test_dataset= create_dataset() 4 5# 2.搭建神经网络 6 model = ImageModelCNN() 7 model.to(device) 8 summary(model, (3,32,32))
从上图的输出中可以看出在池化层是没有参数的,这里的参数不是指没有参数传递或者填入,这里的参数指的是权重和偏执这些参数,在池化层中的池化核以及步长是确定的,且池化层的池化操作进对于特征图上的数值进行操作,对于权重W与偏置b是没有影响的,所以在池化层是没有偏置的。
池化层
池化层是卷积神经网络中常用的一种下采样操作,它的核心目标是在保留重要特征的同时,减少特征图的空间尺寸(宽度和高度),从而降低计算量、控制过拟合,并赋予网络一定的平移不变性。
一、核心目的与作用
- 降维与减少计算量:通过缩小特征图尺寸,大幅减少后续层的参数和计算复杂度。
- 平移不变性:对输入特征图的微小平移(比如图像中物体移动了几个像素)变得不敏感,因为池化会选取局部区域的概括性特征(如最大值),从而使模型更关注是否存在某个特征,而非其精确位置。
- 防止过拟合:通过降低特征的维度和网络参数,有助于避免模型过度拟合训练数据。
- 扩大感受野:让后续的卷积层能“看到”更广阔的原图区域信息,有助于整合上下文。
二、主要类型
最常见的池化操作有:
1. 最大池化
- 工作原理:在特征图的滑动窗口内取最大值作为输出。
- 优点:能很好地保留纹理特征,在实践中最常用。
- 直观理解:它告诉网络“这个区域里最重要的特征(激活值最强)是这个”。
2. 平均池化
- 工作原理:在特征图的滑动窗口内计算平均值作为输出。
- 优点:能保留数据的整体背景信息,减少极端值带来的噪声。
- 直观理解:它告诉网络“这个区域的平均激活水平是这样”。
3. 全局池化
- 工作原理:对整个特征图(全局)进行池化,通常得到一个单一的值。
- 全局平均池化:计算整个特征图所有元素的平均值。
- 全局最大池化:取整个特征图的最大值。
- 作用:常用于网络的最后一层,用于替代全连接层,直接将特征图转换为分类向量。可以大大减少参数,防止过拟合,并使网络能接受不同尺寸的输入。
- 例如:一个 10x10x256 的特征图,经过全局平均池化,会得到一个 1x1x256 的向量,这个256维向量就可以送到分类器。
三、关键参数
池化操作通常由两个参数定义:
- 池化窗口大小:例如
2x2,3x3。这是进行池化的局部区域。 - 步幅:窗口每次滑动的像素数。通常步幅等于窗口大小,以确保不重叠。例如,
2x2池化通常配步幅=2,这样输出尺寸会减半。
1输入特征图 (4x4): 2[ 3 [ 1, 2, 5, 6 ], 4 [ 4, 3, 7, 8 ], 5 [ 9, 10, 14, 13 ], 6 [ 12, 11, 15, 16 ] 7] 8 9第一步:对左上角2x2区域 [1, 2; 4, 3] 取最大值 -> 4 10第二步:对右上角2x2区域 [5, 6; 7, 8] 取最大值 -> 8 11第三步:对左下角2x2区域 [9, 10; 12, 11] 取最大值 -> 12 12第四步:对右下角2x2区域 [14, 13; 15, 16] 取最大值 -> 16 13 14输出特征图 (2x2): 15[ 16 [ 4, 8 ], 17 [ 12, 16 ] 18]
池化层是CNN中一个简洁而有效的组件。它就像一个信息浓缩器,在卷积层提取了丰富的局部特征后,池化层负责筛选出最重要的信息,并压缩数据量,为后续的深度处理奠定基础。虽然其形式简单,但对于构建高效、强鲁棒性的视觉模型至关重要。
卷积层VS池化层
| 特性 | 卷积层 | 池化层 |
|---|---|---|
| 目的 | 特征提取(通过滤波器学习) | 下采样/特征压缩(通过固定规则) |
| 参数 | 有可学习参数(权重和偏置) | 无参数,操作是固定的 |
| 输出 | 深度可能增加(多个滤波器) | 深度不变,仅改变宽高 |
| 连接方式 | 局部连接 + 参数共享 | 局部连接 + 固定函数 |


