细胞增殖


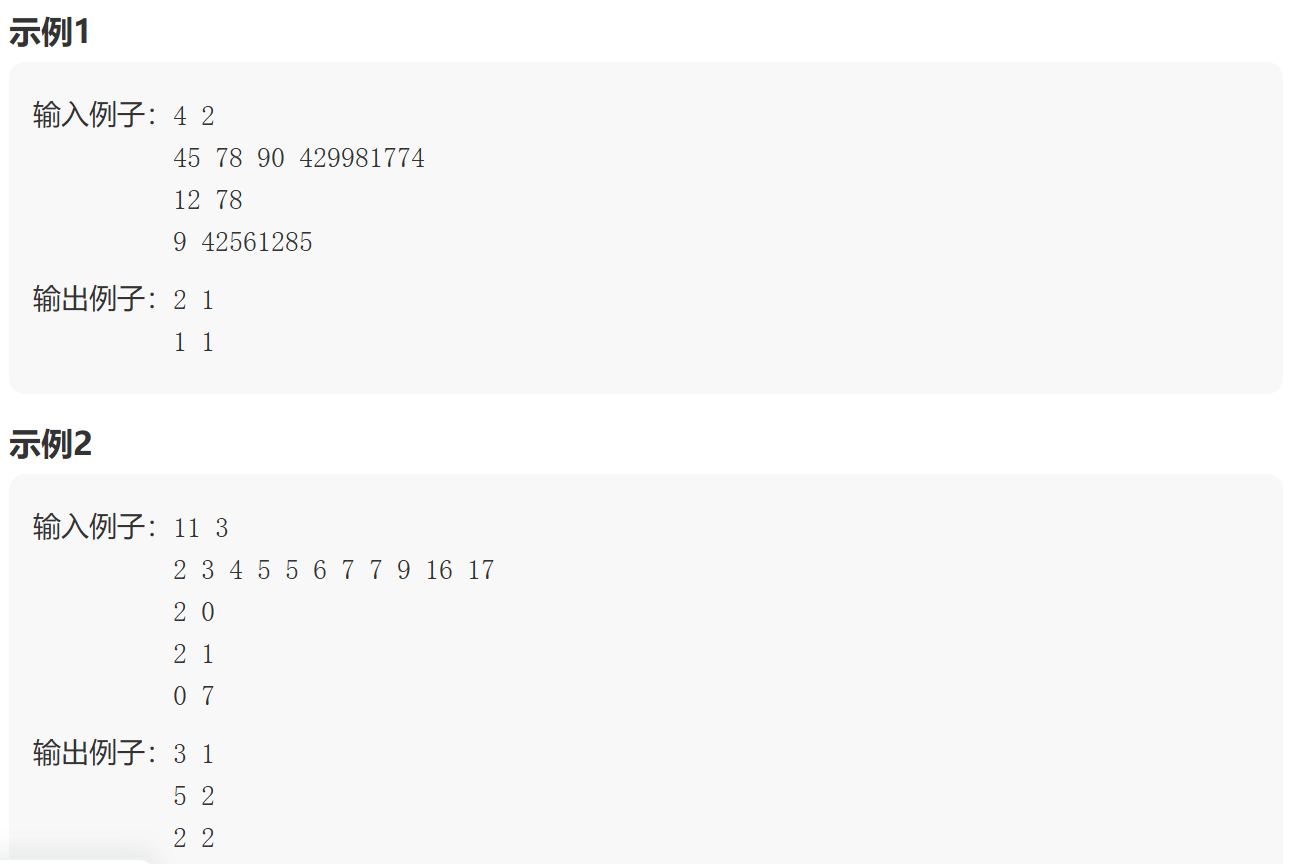
1import java.util.HashMap; 2import java.util.Map; 3import java.util.Scanner; 4 5public class Main { 6 public static void main(String[] args) { 7 Scanner scanner = new Scanner(System.in); 8 long n = scanner.nextLong();//n个观测值 9 long m = scanner.nextLong();//m组<增值基数,稳定基数> 10 Map<Long, Long> freqMap = new HashMap<>((int) n);//存储观测值以及他对应出现的频率 11 long maxObservation = 0;//记录最大的观测值 12 //1.将输入的观测值存储到哈希表中,并找出最大的观测值 13 for (int i = 0; i < n; i++) { 14 long observation = scanner.nextLong(); 15 freqMap.put(observation, freqMap.getOrDefault(observation, 0L) + 1); 16 maxObservation = Math.max(maxObservation, observation); 17 } 18 //2.对于每个B和S求出符合的总观测记录总数,该假说模式下的增值峰值 19 for (long i = 0; i < m; i++) { 20 long b = scanner.nextLong(); 21 long s = scanner.nextLong(); 22 23 long count = 0;//记录总观测记录数 24 long maxPeak = 0;//记录最大峰值 25 26 //2.1如果b是0,那么预测值只能是S 27 if (b == 0) { 28 if (freqMap.containsKey(s)) { 29 long freq = freqMap.get(s); 30 count += freq; 31 maxPeak = Math.max(maxPeak, freq); 32 } 33 } else if (b == 1) { 34 //2.2如果b是1,那么预测值只能是1+s 35 if (freqMap.containsKey(s + 1)) { 36 long freq = freqMap.get(s + 1); 37 count += freq; 38 maxPeak = Math.max(maxPeak, freq); 39 } 40 } else { 41 //2.3当b是大于1的,那么预测值会不断增大到超过最大观测值 42 long bTemp = b; 43 for (long c = b + s; c <= maxObservation; c = (b *= bTemp) + s) { 44 if (freqMap.containsKey(c)) { 45 Long freq = freqMap.get(c); 46 count += freq; 47 maxPeak = Math.max(maxPeak, freq); 48 } 49 } 50 } 51 //3.输出结果 52 System.out.println(count + " " + maxPeak); 53 } 54 scanner.close(); 55 } 56}
小店的经营分析


你想要解决的是统计咖啡店连续经营周期中总利润落在指定区间 [L, R] 内的数量问题,核心是利用前缀和结合二分查找来高效计算符合条件的连续子数组个数。
解题思路
- 前缀和转换:设前缀和数组
S,其中S[0] = 0,S[k]表示前k天的利润总和。那么从第i天到第j天的利润和为S[j+1] - S[i]。 - 问题转化:要求
L ≤ S[j+1] - S[i] ≤ R,等价于S[j+1]-R ≤ S[i] ≤ S[j+1]-L。
1import java.util.Scanner; 2import java.util.TreeMap; 3 4public class Main { 5 public static void main(String[] args) { 6 //1.初始化输入 7 Scanner scanner = new Scanner(System.in); 8 int N = scanner.nextInt(); 9 int[] P = new int[N]; 10 for (int i = 0; i < N; i++) { 11 P[i] = scanner.nextInt(); 12 } 13 int L = scanner.nextInt(), R = scanner.nextInt(); 14 //2.前缀和求解 15 int result = 0; 16 int currentSum = 0; 17 TreeMap<Integer, Integer> countMap = new TreeMap<>(); 18 countMap.put(0, 1); 19 for (int i = 0; i < P.length; i++) { 20 currentSum += P[i]; 21 result += countMap.subMap(currentSum - R, true, currentSum - L, true) 22 .values().stream().mapToInt(Integer::intValue).sum(); 23 countMap.put(currentSum, countMap.getOrDefault(currentSum, 0) + 1); 24 } 25 System.out.println(result); 26 scanner.close(); 27 } 28}
整理科研数据文件


解题思路
- 分段处理:将每个文件名分割成 “连续非数字段” 和 “连续数字段” 的列表(比如
ts010tc12→["ts","010","tc","12"]); - 逐段比较:按规则比较两个文件名的分段列表,直到找到差异:
- 非数字段:按区分大小写的字典序比较;
- 数字段:转成数值比较大小;
- 不同类型段:数字段排在前面;
- 前缀优先:若一个是另一个的前缀,短的排前面;
- 稳定性保证:若两个文件名完全等价,保持它们在输入中的原始顺序
1import java.util.*; 2import java.util.regex.Matcher; 3import java.util.regex.Pattern; 4 5public class Main { 6 private static final Pattern PATTERN = Pattern.compile("\\d+|\\D+"); 7 8 private static class FileComaprator implements Comparator<String> { 9 @Override 10 public int compare(String file1, String file2) { 11 //1.将两个文件名字按照数字和非数字组进行拆分,收集成链表 12 List<String> segments1 = splitTosegments(file1); 13 List<String> segments2 = splitTosegments(file2); 14 //2.逐个比较 15 int minSize = Math.min(segments1.size(), segments2.size()); 16 for (int i = 0; i < minSize; i++) { 17 int cmp = 0; 18 String seg1 = segments1.get(i); 19 boolean seg1isDigit = isDigitSegment(seg1); 20 String seg2 = segments2.get(i); 21 boolean seg2isDigit = isDigitSegment(seg2); 22 //2.1如果两个分割片段都是数字,那么谁小谁在前面 23 if (seg1isDigit && seg2isDigit) { 24 cmp = Integer.compare(Integer.parseInt(seg1), Integer.parseInt(seg2)); 25 } else if (!seg1isDigit && !seg2isDigit) { 26 //2.2两个都是字符串直接字符串比较 27 cmp = seg1.compareTo(seg2); 28 } else { 29 //2.3一个数字一个字符,非数字串大 30 cmp = seg1isDigit ? -1 : 1; 31 } 32 //3.如果比较出了结果,直接返回 33 if (cmp != 0) { 34 return cmp; 35 } 36 } 37 //3.逐个比较失败,说明前minSize个二者是一样的,那么选择长度最短的优先 38 if (segments1.size() != segments2.size()) { 39 return segments1.size() > segments2.size() ? 1 : -1; 40 } 41 //4.如果完全相同那么按照原顺序保持不变 42 return 0; 43 } 44 } 45 46 private static List<String> splitTosegments(String s) { 47 List<String> segments = new ArrayList<>(); 48 Matcher matcher = PATTERN.matcher(s); 49 while (matcher.find()) { 50 segments.add(matcher.group()); 51 } 52 return segments; 53 } 54 55 private static boolean isDigitSegment(String s) { 56 return Character.isDigit(s.charAt(0)); 57 } 58 59 public static void main(String[] args) { 60 Scanner scanner = new Scanner(System.in); 61 int n = scanner.nextInt(); 62 scanner.nextLine(); 63 List<String> fileList = new ArrayList<>(n); 64 for (int i = 0; i < n; i++) { 65 String file = scanner.nextLine().trim(); 66 fileList.add(file); 67 } 68 Collections.sort(fileList, new FileComaprator()); 69 for (String file : fileList) { 70 System.out.println(file); 71 } 72 scanner.close(); 73 } 74}
《2025.12.17华为软开》 是转载文章,点击查看原文。
