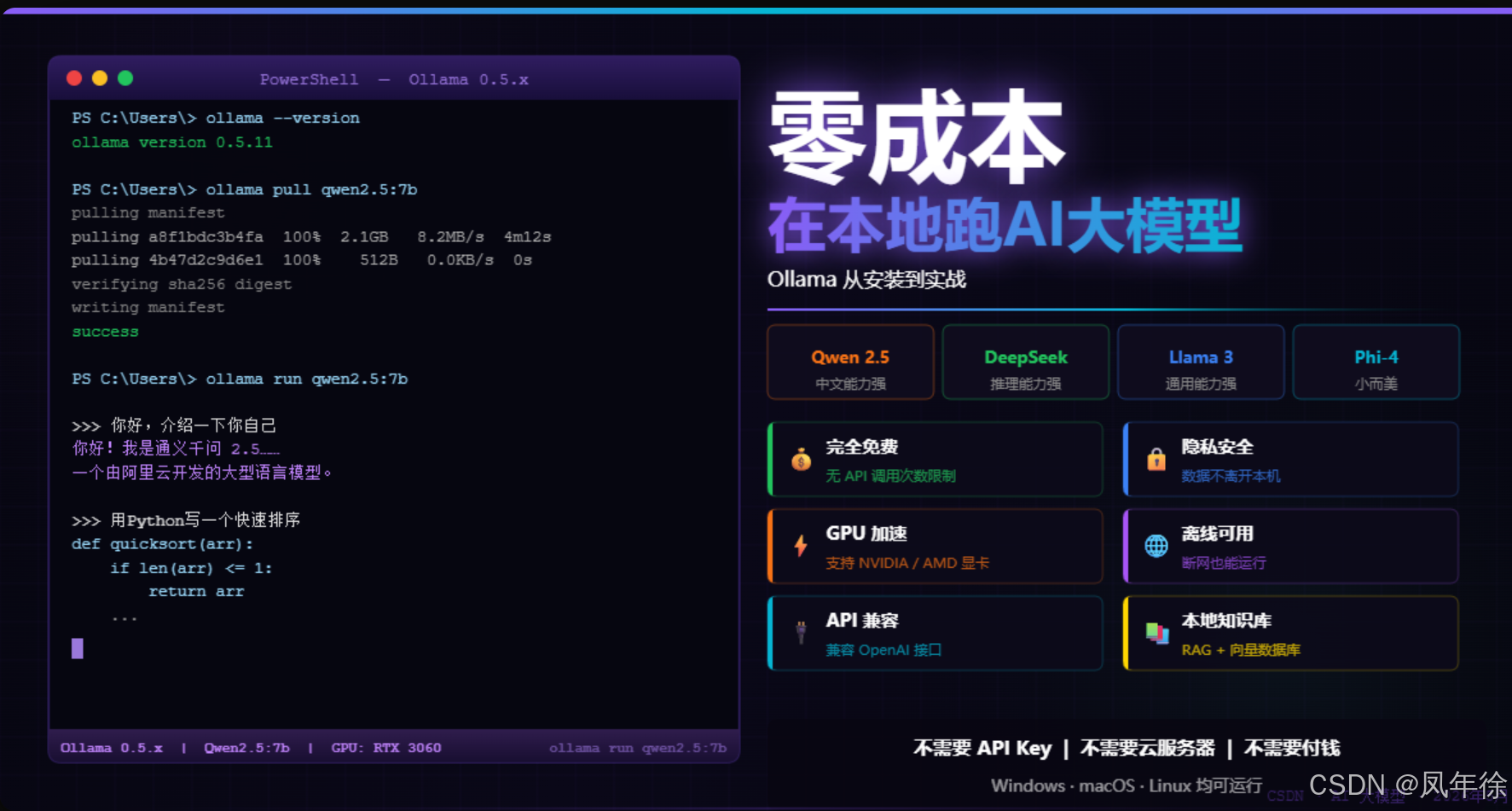
保姆级教程:零成本在本地跑 AI 大模型——Ollama 从安装到实战
手把手教你,用自己的电脑跑起来满血版 Qwen/DeepSeek/Llama,不需要 API Key,不需要云服务器
预计完成时间: 2-3 小时
所需技能: 会用命令行(3条命令够了)
适合人群: 想玩 AI 大模型但不想花钱、担心隐私泄露、喜欢折腾的同学
前言:为什么要在本地跑大模型?
用过 ChatGPT、DeepSeek 的同学应该知道,每次调用都是要花钱的——DeepSeek-V3 每次 API 调用虽然便宜,但日积月累也不是小数目。
更重要的是,你的数据安全吗? 把公司代码、隐私文档发给第三方 API,谁也说不准数据会不会被拿去训练。
而 Ollama 解决了这三个问题:
- 💰 完全免费:模型跑在你自己的电脑上,没有调用次数限制
- 🔒 隐私安全:数据不离开本机,代码文档随便扔给 AI
- ⚡ 离线可用:断网也能跑大模型(只要硬件够用)
- 🔧 可定制:想微调、想接 API、想集成到自己的软件里,都可以
一句话:Ollama 就是 AI 时代的"本地版 Python"——装一个工具,跑各种模型。
一、先搞懂:Ollama 到底是什么?
1.1 不用术语,用大白话
Ollama 是一个帮你管理 AI 大模型的工具。
你可以把它理解成:
- 像 Docker 一样,你不需要手动下载模型文件、配置环境,Ollama 一条命令帮你搞定
- 像 pip 一样,你不需要关心模型在哪,一条命令就能"安装"模型
安装 Ollama 之后,你就拥有了一个本地 AI 大模型仓库:
1# 安装一个模型(跟安装软件一样简单) 2ollama pull qwen2.5:7b # 约5GB,7B参数模型,中文能力不错 3ollama pull deepseek-r1:7b # 约4.5GB,推理能力强 4ollama pull llama3:8b # 约4.7GB,英文为主 5
1.2 Ollama 能做什么?
| 功能 | 说明 |
|---|---|
| 直接对话 | 终端里跟 AI 聊,像 ChatGPT 一样 |
| API 服务 | 启动一个本地 API 服务,代码里调用 |
| 模型管理 | 一台电脑装多个模型,随时切换 |
| 定制模型 | 上传自己的数据,创建专属问答模型 |
| GPU 加速 | 自动用你的 NVIDIA/AMD 显卡加速推理 |
1.3 硬件要求
最低配置(能跑 7B 模型):
- CPU:4核以上(建议 8核)
- 内存:8GB(推荐 16GB)
- 显卡:非必须,但有 NVIDIA 显卡会快很多
流畅配置(跑 14B+ 模型):
- 内存:16GB+
- 显卡:NVIDIA 6GB 显存以上(如 RTX 3060)
- 硬盘:至少 20GB 可用空间
💡 没有显卡? 可以跑!只是慢一点——CPU 推理也能用,只是生成速度比 GPU 慢 5-10 倍。
第一阶段:安装 Ollama(10 分钟)
第 1 步:下载 Ollama
Windows(推荐):
打开官网:https://ollama.com
点击"Download" → 选择 Windows → 下载安装包(约 200MB)
下载完双击运行,安装过程一路点"下一步"即可。
macOS:
1# 方法1:官网下载 dmg 文件 2# 方法2:用 Homebrew 安装 3brew install ollama 4
Linux(WSL 或实体机):
1curl -fsSL https://ollama.com/install.sh | sh 2
⚠️ WSL 环境下如果有 NVIDIA 显卡,需要安装 WSL 专用驱动才能用 GPU 加速。
验证安装成功:
打开一个新的终端(PowerShell / CMD / 终端),输入:
1ollama --version 2
看到类似 ollama version 0.5.x 就说明装好了。
第 2 步:目录结构
1# 创建工作目录 2mkdir -p ollama-workspace 3cd ollama-workspace 4 5# 创建子目录 6mkdir -p models # 存放下载的模型 7mkdir -p projects # 存放你的项目代码 8mkdir -p data # 存放知识库文件 9 10# 进入工作目录 11cd ollama-workspace 12
第 3 步:配置环境变量(可选)
如果你的模型下载到默认目录,想换一个位置:
Windows(PowerShell):
1# 临时设置(只对当前窗口有效) 2$env:OLLAMA_MODELS = "D:\ollama-models" 3
永久设置——Windows:
- 按
Win + R,输入sysdm.cpl,回车 - 点击"高级" → “环境变量”
- 在用户变量里新建:
- 变量名:
OLLAMA_MODELS - 变量值:
D:\ollama-models(换成你的目标路径)
- 变量名:
macOS / Linux:
1# 编辑配置文件 2nano ~/.bashrc # 或 ~/.zshrc 3 4# 在最后添加一行 5export OLLAMA_MODELS=/你的路径/ollama-models 6 7# 保存后刷新 8source ~/.bashrc 9
第二阶段:下载和运行模型(15 分钟)
第 4 步:拉取第一个模型
Ollama 的模型从哪里来?答案是 Ollama Library——官方模型市场,里面有几百个模型。
先来下载一个最适合中文的轻量模型练练手:
1ollama pull qwen2.5:3b 2
这会下载一个约 2GB 的模型文件,下载速度取决于你的网络,通常 5-10 分钟。
💡 后缀数字是什么意思?
qwen2.5:3b→ 3B = 30亿参数,模型大小约 2GB,内存 6GB 够跑qwen2.5:7b→ 7B = 70亿参数,模型大小约 5GB,内存 8GB 够跑qwen2.5:14b→ 14B = 140亿参数,模型大小约 10GB,内存 16GB 够跑参数越多越聪明,但越慢、越吃硬件。7B 是性价比最高的选择。
第 5 步:查看已安装的模型
1ollama list 2
你会看到类似这样的输出:
1NAME ID SIZE MODIFIED 2qwen2.5:3b a8f1bdc3b4fa 1.8GB 3 minutes ago 3
第 6 步:直接对话测试
输入一条命令,Ollama 会直接启动对话:
1ollama run qwen2.5:3b 2
你会看到类似这样的输出:
1>>> 你好,介绍一下你自己 2你好!我是通义千问 2.5,一个由阿里云开发的大型语言模型。…… 3
直接在终端里输入你的问题,按回车,AI 就会回复。按 Ctrl + D 退出对话。
测试几个问题:
1# 测试中文能力 2>>> 用简单的语言解释什么是大语言模型 3 4# 测试代码能力 5>>> 用 Python 写一个快速排序 6 7# 测试知识 8>>> 秦始皇统一六国是在哪一年 9
💡 如果你的电脑没有显卡,Ollama 会自动用 CPU 运行,速度会慢一些,但结果是正确的。
第 7 步:下载更多常用模型
以下是我推荐的几个模型,全部在 Ollama Library 中有:
1# 强烈推荐:DeepSeek R1(推理能力强,中文好) 2ollama pull deepseek-r1:7b 3 4# 推荐:通义千问 2.5 7B(中文能力强,性价比高) 5ollama pull qwen2.5:7b 6 7# 英文为主:Llama 3(Meta出品,通用能力强) 8ollama pull llama3:8b 9 10# 内存不够时的选择:1.5B 超轻量版 11ollama pull qwen2.5:1.5b 12
📌 建议先下
qwen2.5:3b练手,熟悉了再下载大模型。
第三阶段:启动本地 API 服务(10 分钟)
第 8 步:为什么需要 API?
前面 ollama run 是直接在终端里对话,但如果你想把 AI 接入到自己的程序里(Python 脚本、网站、App),就需要 API 服务了。
Ollama 内置了一个兼容 OpenAI 格式的 API 服务,启动它:
启动 API 服务:
1ollama serve 2
你会看到类似输出:
1🚀 Ollama API server running at http://127.0.0.1:11434 2
保持这个窗口开着,然后打开另一个终端窗口继续操作。
第 9 步:用 Python 调用 Ollama API
新建一个 Python 文件 test_ollama.py:
1""" 2Ollama API 调用示例 3兼容 OpenAI 格式,用 Python 轻松调用本地大模型 4""" 5 6from openai import OpenAI 7 8# 连接到本地 Ollama 服务 9client = OpenAI( 10 base_url="http://127.0.0.1:11434/v1", 11 api_key="ollama" # 本地服务不需要真实 API Key,随便填 12) 13 14# 发送对话请求 15response = client.chat.completions.create( 16 model="qwen2.5:3b", # 使用刚才下载的模型 17 messages=[ 18 {"role": "system", "content": "你是一个有帮助的助手,用简洁的语言回答。"}, 19 {"role": "user", "content": "用一句话解释为什么天空是蓝色的。"} 20 ], 21 temperature=0.7, 22 max_tokens=200 23) 24 25# 打印回复 26print("AI 回复:") 27print(response.choices[0].message.content) 28
运行:
1pip install openai # 如果还没安装 openai 库 2python test_ollama.py 3
输出:
1AI 回复: 2天空呈现蓝色是因为大气层中的气体分子对阳光进行散射…… 3
第 10 步:实现流式输出
上面的代码会等 AI 全部生成完再返回,有时候模型思考时间长,体验不好。改成流式输出,边想边显示:
1""" 2流式输出示例:AI 回答像打字机一样逐字显示 3""" 4 5from openai import OpenAI 6import sys 7 8client = OpenAI( 9 base_url="http://127.0.0.1:11434/v1", 10 api_key="ollama" 11) 12 13print("AI 回复:", end="", flush=True) 14 15stream = client.chat.completions.create( 16 model="qwen2.5:3b", 17 messages=[ 18 {"role": "user", "content": "写一个 Python 快速排序函数,并解释每一行代码"} 19 ], 20 stream=True # 开启流式输出 21) 22 23# 逐字打印,像打字机效果 24for chunk in stream: 25 if chunk.choices[0].delta.content: 26 print(chunk.choices[0].delta.content, end="", flush=True) 27 28print() # 换行 29
第四阶段:构建本地 AI 知识库助手(30 分钟)
第 11 步:知识库是什么?
普通 AI 只知道训练数据里的知识,你的私有文档(公司文档、个人笔记、技术文档)它不知道。
知识库的作用就是:让 AI 能够回答关于你自己文档的问题。
工作原理:
1你的文档 → 切分成小块 → 转换成向量 → 存入向量数据库 2 ↓ 3用户提问 → 查向量数据库 → 找到相关片段 → 一起发给 AI → 生成回答 4
第 12 步:安装依赖
1pip install langchain langchain-community \ 2 sentence-transformers qdrant-client \ 3 openai python-dotenv tqdm 4
第 13 步:创建知识库脚本
新建 knowledge_base.py:
1""" 2本地知识库问答系统 3基于 Ollama + LangChain + Qdrant 4""" 5 6import os 7from langchain_community.document_loaders import TextLoader 8from langchain.text_splitter import RecursiveCharacterTextSplitter 9from langchain_community.embeddings import OllamaEmbeddings 10from langchain_community.vectorstores import Qdrant 11from langchain_community.chat_models import ChatOllama 12from langchain.chains import RetrievalQA 13 14# ── 配置 ────────────────────────────────────────────────────── 15OLLAMA_BASE_URL = "http://127.0.0.1:11434" 16EMBEDDING_MODEL = "nomic-embed-text" # 专门做向量化的模型 17LLM_MODEL = "qwen2.5:7b" # 做回答的大模型 18COLLECTION_NAME = "my_knowledge_base" 19QDRANT_PATH = "./qdrant_storage" 20 21# ── 步骤1:加载文档 ────────────────────────────────────────── 22print("📂 加载文档...") 23 24# 自动加载 data/ 目录下的所有 .txt 文件 25documents = [] 26for filename in os.listdir("data"): 27 if filename.endswith(".txt"): 28 loader = TextLoader(f"data/{filename}", encoding="utf-8") 29 documents.extend(loader.load()) 30 print(f" ✅ 加载:{filename}") 31 32if not documents: 33 print("⚠️ data/ 目录下没有 .txt 文件,先放入一些文档试试!") 34 print(" 示例:把一些技术笔记、公司文档复制到 data/ 目录") 35 exit() 36 37# ── 步骤2:切分文档 ────────────────────────────────────────── 38print("\n✂️ 切分文档...") 39splitter = RecursiveCharacterTextSplitter( 40 chunk_size=500, # 每段最多500字符 41 chunk_overlap=50 # 段之间重叠50字符,保持上下文连贯 42) 43chunks = splitter.split_documents(documents) 44print(f" ✅ 切分完成,共 {len(chunks)} 个片段") 45 46# ── 步骤3:向量化并存储 ─────────────────────────────────────── 47print(f"\n🔢 生成向量(使用 {EMBEDDING_MODEL})...") 48 49# 先下载 embedding 模型 50os.system(f"ollama pull {EMBEDDING_MODEL}") 51 52embeddings = OllamaEmbeddings( 53 model=EMBEDDING_MODEL, 54 base_url=OLLAMA_BASE_URL 55) 56 57# 存入本地 Qdrant 向量数据库 58vectorstore = Qdrant.from_documents( 59 documents=chunks, 60 embedding=embeddings, 61 path=QDRANT_PATH, 62 collection_name=COLLECTION_NAME 63) 64print(" ✅ 向量入库完成") 65 66# ── 步骤4:构建问答 Chain ───────────────────────────────────── 67print(f"\n🤖 启动 AI 助手(使用 {LLM_MODEL})...") 68 69llm = ChatOllama( 70 model=LLM_MODEL, 71 base_url=OLLAMA_BASE_URL, 72 temperature=0.3 # 低温度=更准确的回答 73) 74 75qa_chain = RetrievalQA.from_chain_type( 76 llm=llm, 77 chain_type="stuff", # 把相关片段塞进一个 Prompt 78 retriever=vectorstore.as_retriever(search_kwargs={"k": 3}) 79) 80 81# ── 步骤5:开始问答 ─────────────────────────────────────────── 82print("\n" + "=" * 50) 83print("📚 知识库问答助手已就绪!") 84print("=" * 50) 85print("输入问题,AI 会基于 data/ 目录下的文档回答") 86print("输入 'quit' 退出\n") 87 88while True: 89 try: 90 question = input("你:").strip() 91 if not question: 92 continue 93 if question.lower() in ["quit", "exit", "q"]: 94 print("👋 再见!") 95 break 96 97 print("🤖 AI:", end="", flush=True) 98 result = qa_chain.invoke({"query": question}) 99 print(result["result"]) 100 print() 101 102 except (KeyboardInterrupt, EOFError): 103 print("\n👋 再见!") 104 break 105 except Exception as e: 106 print(f"\n⚠️ 出错了:{e}") 107
第 14 步:准备测试文档
1mkdir -p data 2 3# 创建一个测试文档 4cat > data/技术笔记.txt << 'EOF' 5Python Web 框架选型指南: 6 71. Django:全功能框架,适合企业级项目。 8 内置 ORM、管理后台、认证系统。 9 适合:后台管理系统、电商平台、数据平台。 10 112. FastAPI:现代异步框架,适合 API 开发。 12 自动生成 OpenAPI 文档,支持类型提示。 13 适合:微服务、AI 后端、高并发 API。 14 153. Flask:轻量级框架,灵活度高。 16 需要手动安装扩展来增加功能。 17 适合:小型项目、原型开发、学习目的。 18 19数据库推荐: 20- PostgreSQL:功能最全,生产首选 21- MySQL:生态成熟,稳定可靠 22- SQLite:零配置,嵌入式/轻量场景 23EOF 24 25echo "✅ 测试文档已创建到 data/技术笔记.txt" 26
第 15 步:运行知识库
1python knowledge_base.py 2
效果:
1📂 加载文档... 2 ✅ 加载:技术笔记.txt 3 4✂️ 切分文档... 5 ✅ 切分完成,共 8 个片段 6 7🔢 生成向量... 8 ✅ 向量入库完成 9 10🤖 启动 AI 助手... 11================================================== 12📚 知识库问答助手已就绪! 13================================================== 14 15你:FastAPI 适合什么场景? 16 17🤖 AI:FastAPI 是一个现代异步 Python Web 框架,特别适合以下场景: 181. 微服务架构 192. AI 应用后端(因为异步处理高并发) 203. 需要高并发处理的 RESTful API 214. 需要自动生成 OpenAPI 文档的项目 22 23根据文档,FastAPI 的主要特点是支持类型提示和自动生成 API 文档。 24
第五阶段:Ollama + Cherry Studio 可视化界面(10 分钟)
第 16 步:为什么需要图形界面?
命令行对话没问题,但用久了你肯定想要一个更好看的界面。
Cherry Studio 是一个免费开源的 Ollama 图形客户端,功能类似 ChatGPT,但完全本地运行。
下载: https://github.com/kangmove/cherry-studio/releases
Windows 用户下载 .exe 安装包,macOS 用户下载 .dmg,安装后:
Step 1:配置 Ollama 连接
- 打开 Cherry Studio
- 设置 → 模型服务 → Ollama
- 地址填:
http://127.0.0.1:11434
Step 2:下载模型到 Cherry Studio
- 模型管理 → 下载模型
- 搜索
qwen2.5:7b→ 下载
Step 3:开始对话
- 新建对话 → 选择模型 → 开始聊天
Cherry Studio 的优点:
- ✅ 对话历史自动保存
- ✅ 支持多模型切换对比
- ✅ 内置提示词模板
- ✅ 支持知识库功能(比命令行更简单)
第六阶段:进阶技巧(15 分钟)
第 17 步:自定义模型参数
每次 ollama run 可以加参数,控制 AI 的行为:
1# temperature:控制创造性(0=保守准确,1=有创意) 2# 0.3=适合编程和回答问题 3# 0.8=适合写小说和创意内容 4ollama run qwen2.5:7b --temperature 0.3 5 6# num_ctx:上下文窗口大小(越大能记住越多内容) 7# 7B 模型默认 4096 tokens(约3000汉字) 8# 增加到 8192 可以处理更长的文档 9ollama run qwen2.5:7b --num_ctx 8192 10 11# top_p 和 top_k:控制输出的多样性 12ollama run qwen2.5:7b --top_k 20 --top_p 0.9 13
第 18 步:创建自定义模型(医学问答示例)
Ollama 支持用 Modelfile 定制专属模型:
Step 1:创建配置文件
1mkdir -p projects/medical-bot 2cd projects/medical-bot 3 4cat > Modelfile << 'EOF' 5FROM qwen2.5:7b 6 7# 设置系统提示词 8SYSTEM """ 9你是一个专业的医学科普助手。你的职责是: 101. 用通俗易懂的语言解释医学概念 112. 不确定的问题要明确说明并建议就医 123. 不提供具体的医疗诊断或用药建议 134. 所有建议仅供参考,以医生诊断为准 14 15回答格式: 16- 先给出简要回答 17- 再提供详细解释 18- 最后加上"温馨提示:本回答仅供参考" 19""" 20 21# 设置默认参数 22PARAMETER temperature 0.3 23PARAMETER num_ctx 4096 24EOF 25
Step 2:创建模型
1ollama create medical-assistant -f Modelfile 2
Step 3:使用自定义模型
1ollama run medical-assistant 2 3>>> 感冒了怎么办 4你好!根据你的情况,以下是一些建议: 5 6【简要回答】 7普通感冒通常一周左右可以自愈,多休息、多喝水是关键…… 8 9【温馨提示:本回答仅供参考,如有严重症状请及时就医】 10
第 19 步:Ollama 作为 DeepSeek API 的替代
如果你的代码原本用的是 DeepSeek 或 OpenAI 的 API,可以无缝切换到 Ollama:
1""" 2将 OpenAI/DeepSeek API 调用改为 Ollama 3只需要改 base_url 和 api_key,其他代码不变 4""" 5 6from openai import OpenAI 7 8# ── 原来的 DeepSeek API 调用 ────────────────────────────────── 9# client = OpenAI( 10# api_key="sk-xxxx", # 付费 API Key 11# base_url="https://api.deepseek.com" # 官方服务器 12# ) 13 14# ── 改成 Ollama(完全免费) ────────────────────────────────── 15client = OpenAI( 16 api_key="ollama", # 随便填,本地不需要真实 Key 17 base_url="http://127.0.0.1:11434/v1" # Ollama 本地服务 18) 19 20# ── 其他代码完全不变! ───────────────────────────────────────── 21response = client.chat.completions.create( 22 model="qwen2.5:7b", # 改成你的本地模型名 23 messages=[ 24 {"role": "system", "content": "你是助手"}, 25 {"role": "user", "content": "写一个快速排序"} 26 ], 27 temperature=0.3, 28 max_tokens=500 29) 30 31print(response.choices[0].message.content) 32
第 20 步:多模型对比
一个模型回答不满意?同时问几个模型,对比答案:
1""" 2多模型对比:同时问 Qwen 和 Llama,看谁答得好 3""" 4 5from openai import OpenAI 6 7client = OpenAI( 8 api_key="ollama", 9 base_url="http://127.0.0.1:11434/v1" 10) 11 12models = ["qwen2.5:7b", "deepseek-r1:7b", "llama3:8b"] 13question = "用Python写一个装饰器,测量函数执行时间" 14 15for model in models: 16 print(f"\n{'='*50}") 17 print(f"🤖 模型:{model}") 18 print('='*50) 19 20 response = client.chat.completions.create( 21 model=model, 22 messages=[{"role": "user", "content": question}], 23 temperature=0.3 24 ) 25 print(response.choices[0].message.content) 26
第七阶段:常见问题与排错
Q:模型下载很慢怎么办?
1# Ollama 默认从官方 CDN 下载,国内可能较慢 2# 解决方案:使用镜像站或挂代理 3 4# 方式1:设置代理 5export HTTP_PROXY=http://127.0.0.1:7890 6export HTTPS_PROXY=http://127.0.0.1:7890 7ollama pull qwen2.5:7b 8 9# 方式2:直接从 ModelScope 手动下载 10# 访问 https://modelscope.cn/models 搜索对应模型 11
Q:内存不够用,OOM 了怎么办?
1# 1. 换更小的模型 2ollama pull qwen2.5:1.5b # 1.5B 版本,4GB 内存即可 3 4# 2. 减少同时加载的模型数量 5# 先把之前的模型卸载 6ollama rm qwen2.5:7b 7ollama list # 确认只剩需要的模型 8 9# 3. 设置最大内存使用 10# Windows:OLLAMA_MAX_LOADED_MODELS=1 11# Linux/macOS:export OLLAMA_MAX_LOADED_MODELS=1 12
Q:Ollama serve 启动了但连不上?
1# 1. 检查服务是否在运行 2curl http://127.0.0.1:11434/api/tags 3 4# 2. 检查端口是否被占用 5netstat -ano | findstr 11434 # Windows 6lsof -i :11434 # macOS/Linux 7 8# 3. 指定特定 IP 监听(允许局域网其他设备访问) 9OLLAMA_HOST=0.0.0.0 ollama serve 10
Q:GPU 没有被用上,还是 CPU 在跑?
1# 1. 确认有 NVIDIA 显卡 2nvidia-smi 3 4# 2. 确认安装了 CUDA 驱动 5# 下载:https://developer.nvidia.com/cuda-downloads 6 7# 3. 确认 Ollama 能检测到显卡 8ollama show qwen2.5:7b 9 10# 如果显示 "Name: NVIDIA GeForce RTX 3060" 说明 GPU 加速正常 11
Q:模型回答很慢,生成一个句子要等很久?
1# 1. 如果有 NVIDIA 显卡,确认正在使用 GPU 加速 2# GPU 推理速度通常比 CPU 快 10-20 倍 3 4# 2. 减少上下文长度(能提升速度但减少记忆) 5ollama run qwen2.5:7b --num_ctx 2048 6 7# 3. 使用量化模型(牺牲少量精度换取速度) 8# 4bit 量化版比原版快 30%,体积小 75% 9ollama pull qwen2.5:7b-instruct-q4_K_M 10
完整代码结构
1ollama-workspace/ 2├── data/ 3│ └── 技术笔记.txt ← 你的知识库文档 4├── models/ ← 存放下载的模型(可选路径) 5├── projects/ 6│ └── medical-bot/ 7│ └── Modelfile ← 自定义模型配置 8├── qdrant_storage/ ← 向量数据库存储 9├── test_ollama.py ← API 调用测试 10├── stream_test.py ← 流式输出测试 11├── knowledge_base.py ← 本地知识库问答 12├── multi_model_compare.py ← 多模型对比 13└── .env ← 环境变量(可选) 14
总结:你学到了什么?
| 知识点 | 掌握程度 |
|---|---|
| Ollama 安装与基本使用 | ✅ |
| 下载和管理多个模型 | ✅ |
| 启动本地 API 服务 | ✅ |
| Python 代码调用 Ollama | ✅ |
| 流式输出(打字机效果) | ✅ |
| 构建本地知识库问答系统 | ✅ |
| Cherry Studio 图形界面 | ✅ |
| 自定义模型(Modelfile) | ✅ |
| 多模型对比 | ✅ |
| API 兼容(替换 DeepSeek) | ✅ |
下一步探索
学会 Ollama 之后,可以继续探索:
- 🔗 Ollama + Dify:用 Dify 可视化编排 AI 工作流(下一篇教程预告)
- 🔗 Ollama + AnythingLLM:更强大的本地知识库工具
- 🔗 Ollama + Continue:VS Code 插件,AI 帮你写代码
- 🔗 Ollama + RAG:高级检索增强生成,结合向量数据库做精准问答
- 🔗 模型微调:用自己数据微调模型,打造专属 AI
💬 看完有收获?点个赞收藏一下吧!有问题欢迎评论区交流~
🔖 相关教程:
- 《保姆级教程:从零手写一个 RAG 系统》
- 《保姆级教程:从零搭建你的第一个 AI Agent》
- 《保姆级教程:从零搭建 AI 系统权限控制系统》
《保姆级教程:零成本在本地跑AI大模型_Ollama》 是转载文章,点击查看原文。