文章目录
- 台阶问题
- 最大子段和
- 传球游戏
- 乌龟棋
线性dp 是动态规划问题中最基础、最常⻅的⼀类问题。它的特点是状态转移只依赖于前⼀个或前⼏个状态,状态之间的关系是线性的,通常可以⽤⼀维或者⼆维数组来存储状态。 我们在⼊⻔阶段解决的《下楼梯》以及《数字三⻆形》其实都是线性dp,⼀个是⼀维的,另⼀个是⼆ 维的。
台阶问题
题目描述
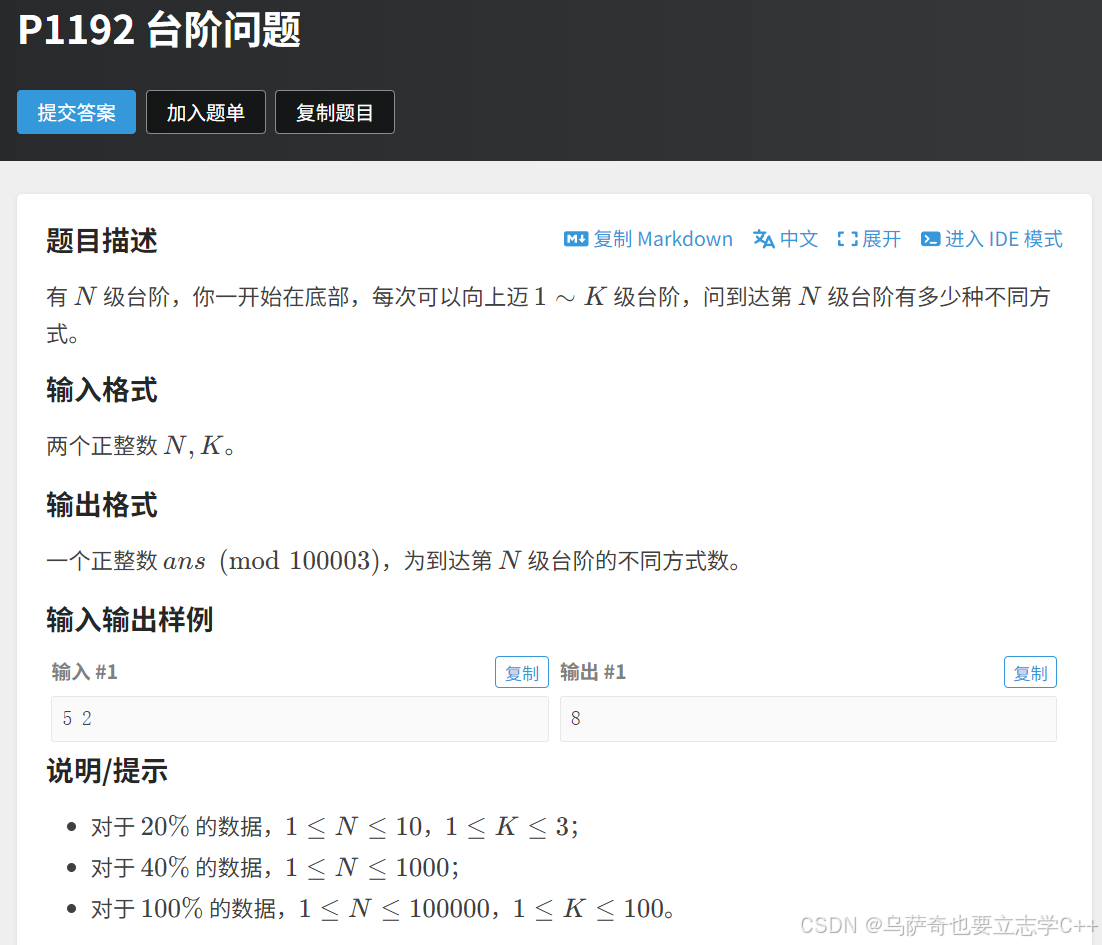
题目解析
本题就是上一节下楼梯的问题的加强版,总体思路不变,下面我们还是按照动规5板斧来分析一下这道题。
1、状态表示
dp[i]表示走到第i个台阶的所有方案数
2、状态转移方程
第i个台阶的方案数等于从i-1阶到i-k阶的所有方案数之和,因为本题数据比较大,用long long都无法保证数据不越界,所以题目规定方案数还需要模100003,第i个台阶的方案数等于从i-1阶到i-k阶的所有方案数之和再模上100003,所以但是注意是可能越界访问的,比如i为3,k为10,i-k是可能访问到数组负下标的,所以访问台阶时需要保证i-k始终大于等于0。
dp[i] = (dp[i] + dp[i - j])% 100003(j从1到k)。
3、初始化
本题大家可能会首先想到先将数组前k个数据初始化,但是这样操作比较麻烦,小编介绍一个新方法,直接将dp[0]置为1即完成初始化操作,然后从dp[1]开始往后循环计算方案数。
4、填表顺序
从左往后
5、输出结果
f[n]即为结果
代码
1#include <iostream> 2using namespace std; 3 4typedef long long LL; 5 6const int N = 1e5 + 10, MOD = 1e5 + 3; 7 8int n, k; 9LL dp[N]; 10 11int main() 12{ 13 cin >> n >> k; 14 //初始化 15 dp[0] = 1; 16 //循环填表 17 for (int i = 1; i <= n; i++) 18 { 19 for (int j = 1; j <= k; j++) 20 { 21 //保证不越界访问 22 if (i - j < 0) 23 break; 24 dp[i] = (dp[i] + dp[i - j]) % MOD; 25 } 26 } 27 //输出结果 28 cout << dp[n] << endl; 29 return 0; 30} 31
最大子段和
题目描述
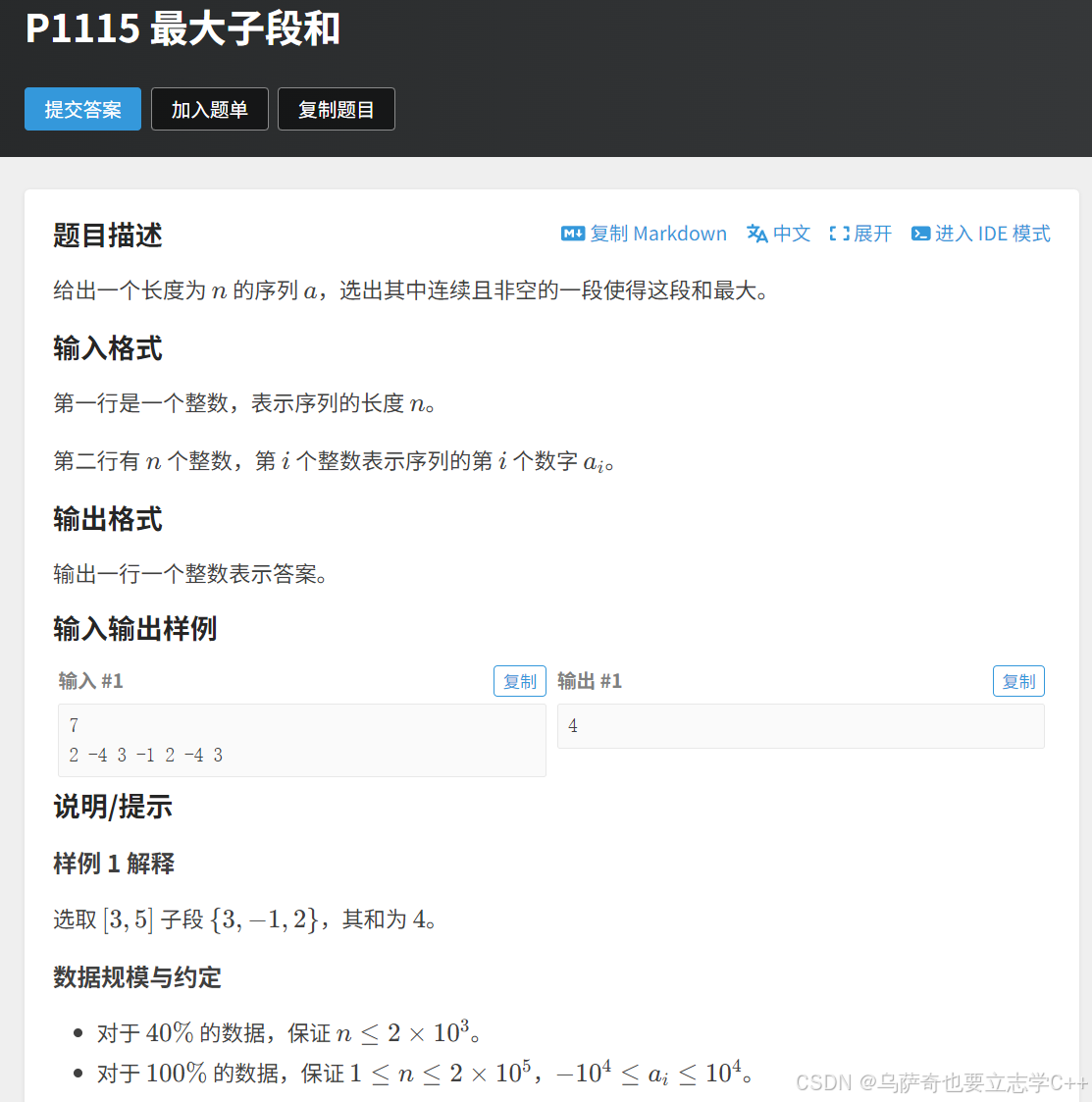
题目解析
本题小编介绍一种在面对子序列和子数组问题时定义状态表示的技巧。
1、状态表示
以某个位置为结尾,结合题意来定义状态表示。
以本题为例,f[i]表示以i位置为结尾的所有子数组中,最大和是多少。

2、状态转移方程
推导状态转移方程我们还是根据最后一步来划分情况。
首先明确本题数据是从数组下标1开始存储的,那么如果n为1,也就是只有一个数据,那么最大子段就是它本身,所以f[i] = a[i]。
如果n大于1,第i个格子的最大子段和有两种可能:
第一最大子段和是它本身a[i],因为第i个格子之前的最大子段和可能是负数。
f[i] = a[i]
第二最大子段和是第i个格子之前的所有子段中的最大子段加上第i个格子的数据,第i个格子之前的所有子段中的最大子段加就是下图中红框中左右子段的最大值,红框中每一行表示一个子段。
f[i] = f[i - 1] + a[i]
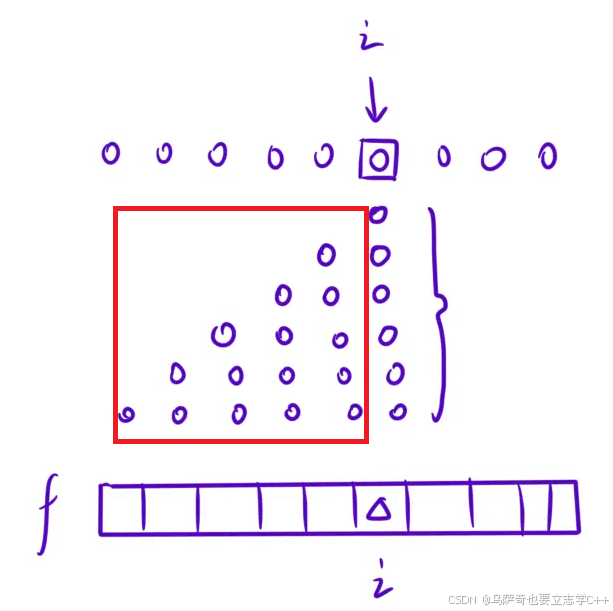
那么总的来说第i个格子的最大子段和就是两种可能中取较大值:
f[i] = max(a[i], f[i - 1] + a[i]) 3、初始化
当填第一个格子f[1]时,根据状态转移方程:f[1] = max(a[1], f[0] + a[1]),而根据我们之前的分析,第一个格子的值就是它本身:f[i] = a[i],所以只要我们把f[0]初始化为0,即可满足要求。
4、填表顺序
从左往右
5、输出结果
结果为f数组中的最大值
代码
1#include <iostream> 2#include <algorithm> 3using namespace std; 4 5const int N = 2e5 + 10; 6 7int n; 8int a[N], f[N]; 9 10int main() 11{ 12 //处理输入 13 cin >> n; 14 for (int i = 1; i <= n; i++) 15 { 16 cin >> a[i]; 17 } 18 //初始化 19 f[0] = 0; 20 //按序填表 21 for (int i = 1; i <= n; i++) 22 { 23 f[i] = max(a[i], a[i] + f[i - 1]); 24 } 25 //输出结果 26 int ret = -0x3f3f3f3f; 27 for (int i = 1; i <= n; i++) 28 { 29 ret = max(ret, f[i]); 30 } 31 cout << ret << endl; 32 return 0; 33} 34
1//优化版(无a数组) 2#include <iostream> 3#include <algorithm> 4using namespace std; 5 6const int N = 2e5 + 10; 7 8int n; 9int f[N]; 10 11int main() 12{ 13 //处理输入 14 cin >> n; 15 //初始化 16 f[0] = 0; 17 //按序填表+更新ret 18 int ret = -0x3f3f3f3f; 19 for (int i = 1; i <= n; i++) 20 { 21 int x; 22 cin >> x; 23 f[i] = max(x, x + f[i - 1]); 24 ret = max(ret, f[i]); 25 } 26 //输出结果 27 cout << ret << endl; 28 return 0; 29} 30
传球游戏
题目描述
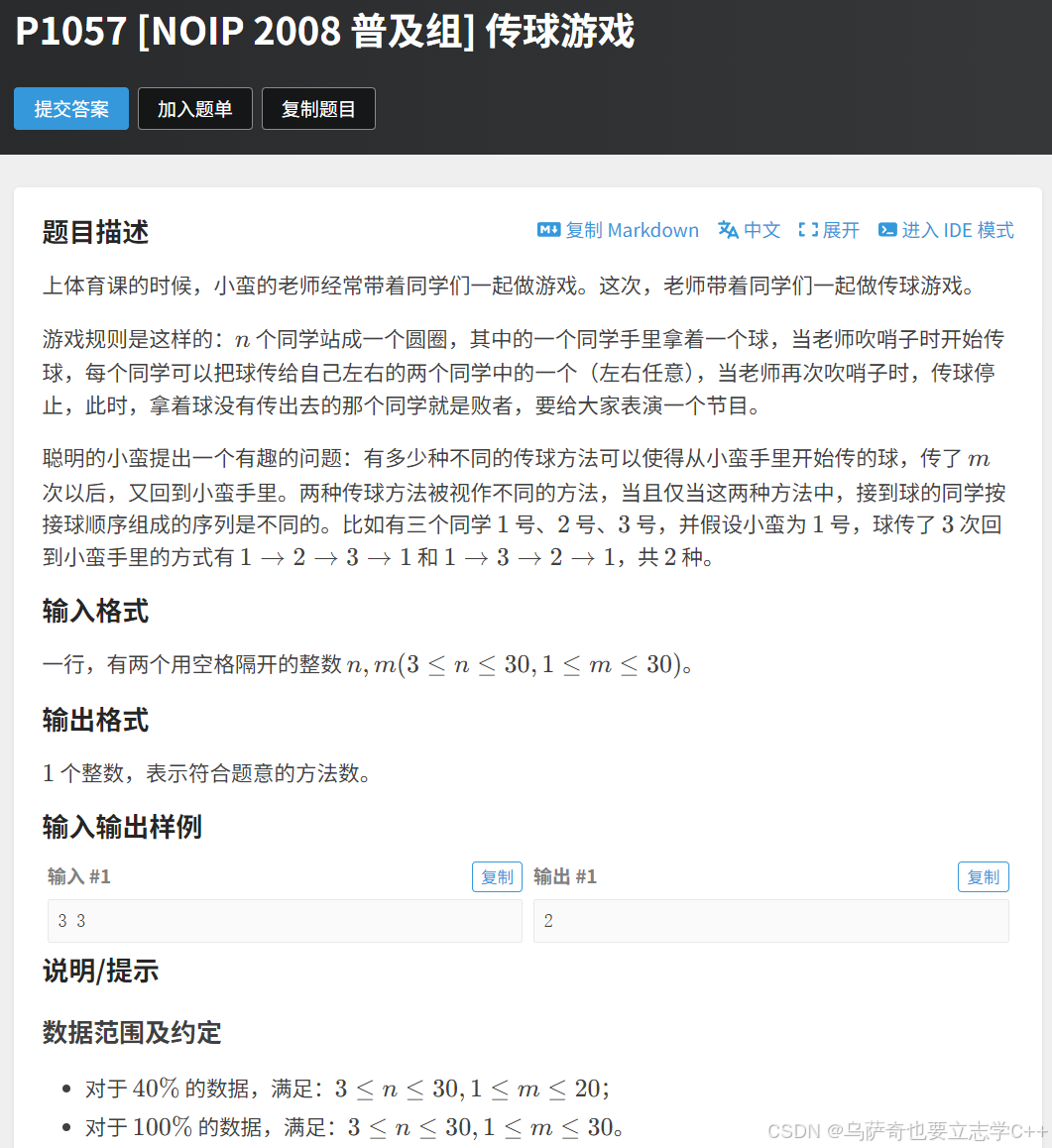
题目解析
1、状态表示
首先我们要知道某个格子中的信息是从第一个格子开始到该格子一共有多少种方案。
然后分析该格子应该包含哪些信息,因为题目规定所有同学站成一个圆圈,所以球可能从左边格子来也可能从右边格子来,要传递球所以必然需要知道该格子编号和左边、右边格子的编号,所以格子应该包含编号信息。然后本题还有一个条件:传球次数,也就说我还需要知道球传递了多少次后落在了谁手里,所以还应该包含传球次数信息。所以我们这里用一个一维数组是存不下两个信息的,所以我们可以用一个二维数组f[i][j]。
f[i][j]表示球传递了i次之后,最终落在了j同学手里一共有多少种方案。
2、状态转移方程
本题推导状态转移方程需要分类讨论,因为题目规定同学围成一个圈,但是我们要用二维线性数组存储数据,所以需要分三种情况:
第一种是接受球的是编号为1的同学,此时传递球的同学编号可能是2和n,所以编号为1的同学的传球方案数就是2和n同学的方案数之和:
dp[i][1] = dp[i - 1][2] + dp[i - 1][n]
第二种是接受球的是编号为从2到n - 1的同学,假设为j,此时传递球的同学编号可能是j - 1和j + 1,所以编号为1的同学的传球方案数就是j - 1和j + 1同学的方案数之和:
dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j + 1]
第三种是接受球的是编号为n的同学,此时传递球的同学编号可能是1和n - 1,所以编号为n的同学的传球方案数就是1和n - 1同学的方案数之和:
dp[i][n] = dp[i - 1][1] + dp[i - 1][n - 1]

小编再补充解释一下本题的代码实现和二维数组填表顺序,总的来说是是从上往下按顺序一行一行的填,行表示传球次数,列表示同学编号,因为同学编号是从1开始的,所以第0列没有意义,第一行表示传球次数为0,此时根据题目规定球在一号同学手里,dp[0][1]就表示球传递了0次最后落在1号同学手里一共有多少种方案,所以dp[0][1]是一个合法格子,那么第一行除了一号同学其他同学的格子就没有意义了,这时我们需要思考把第一行一号同学初始化为0还是1,根据我们前面分析的状态转移方程,填格子都需要累加上一行两个格子的方案数,如果我们把dp[0][1]初试化为0,那么后面所有格子累加的结果都为0,所以我们要把dp[0][1]初始化为1,这里我们可以总结一下,对于这类求方案数的情况,因为一般情况状态转移方程都是累加的,所以一般会将初试情况初始化为1。
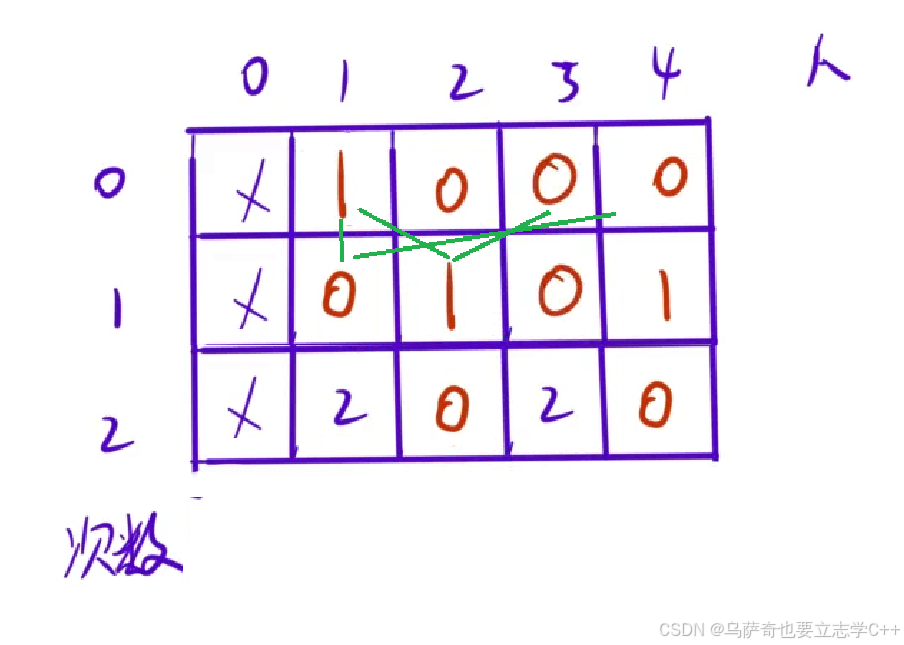
3、初始化
f[0][1] = 1
4、填表顺序
从上往下依次填每一行
5、输出结果
f[m][1]
代码
1#include <iostream> 2using namespace std; 3 4const int N = 40; 5 6int n, m; //n个同学,传递m次 7int dp[N][N]; //次数,同学编号 8 9int main() 10{ 11 cin >> n >> m; 12 //初始化 13 dp[0][1] = 1; 14 //按序填表 15 //从1开始枚举传递次数(枚举行) 16 for (int i = 1; i <= m; i++) 17 { 18 //填第1个同学 19 dp[i][1] = dp[i - 1][2] + dp[i - 1][n]; 20 21 //填第2到n-1个同学 22 //从2开始枚举同学编号(枚举列) 23 for (int j = 2; j < n; j++) 24 { 25 dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j + 1]; 26 } 27 28 //填第n个同学 29 dp[i][n] = dp[i - 1][1] + dp[i - 1][n - 1]; 30 } 31 //输出结果 32 cout << dp[m][1] << endl; 33 return 0; 34} 35
乌龟棋
题目描述

题目解析
先分析一下题意,本题有点类似我们玩过的飞行棋,投骰子决定走多少步,一共有6种情况(1-6步),本题是抽卡片决定走多少步,一共有4种情况(1-4步),并且本题格子是一维的,走到某个格子即可得到该格子的分数,题目要求我们找出从起点走到终点格子的最大分数。
1、状态表示
本题dp数组每个格子要存储六个信息:走到x格子时,用1卡片i张、用2卡片j张、用3卡片k张、用4卡片z张的情况下的最大分数,所以我们需要一个五维数组dp存储,但其实一维数组下标x可以通过另外4个变量计算出来,因为走到x格子本质是从下标1开始,用了i张1卡片、j张2卡片、k张3卡片、z张4卡片后走到的位置:
x = 1 + i + 2 * j + 3 * k + 4 * z
所以我们用一个四维dp数组存储,需要用到x时通过另外4个变量计算得到。
2、状态转移方程
推导状态转移方程本质就是推导dp[i][j][k][z],根据我们前面的分析,dp[i][j][k][z]对应的一维数组下标是x,那么走到x一共有四种可能:分别是从x-1到x、x-2到x、x-3到x、x-4到x,对于x-1来说,它对于的dp数组是dp[i - 1][j][k][z],同理对于x-2来说,dp数组是dp[i][j - 1][k][z]… 下面示意图是以从x-3走到x为例。
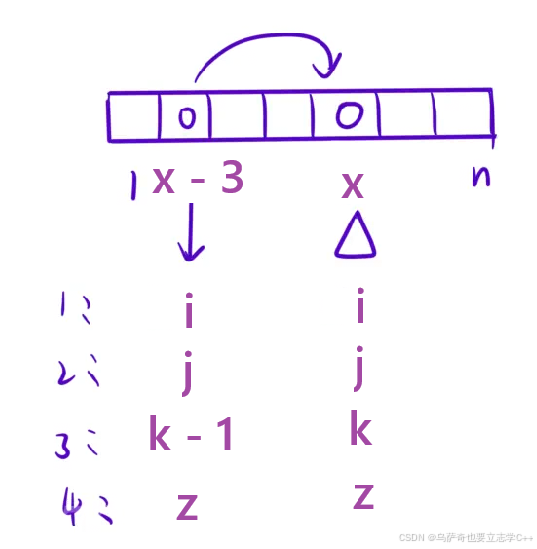
但是这里有个细节,需要处理边界情况,对于变量i j k z来说,它们表示抽取各自卡的张数,对i来说,取值范围是从0到cnt[1](cnt数组中cnt[1] cnt[2] cnt[3] cnt[4]有意义,各自表示1卡片的张数、2卡片的张数、3卡片的张数、4卡片的张数),对于j来说,取值范围是从0到cnt[2],k z同理,所以i j k z取值是非负的,所以要访问dp[i - 1][j][k][z]时需要保证i大于0,要访问dp[i][j - 1][k][z]时需要保证j大于0,k、z同理。
所以状态转移方程如下所示,本质我们上面的推导是基于最后一步分析的:

在代码实现中会用4个for循环依次枚举i j k z的所有取值,枚举一种i j k z的取值情况就会将四种可能的状态庄毅方程作比较:dp[i - 1][j][k][z]、dp[i][j - 1][k][z]、dp[i][j][k - 1][z]、dp[i][j][k][z - 1],取出最大值作为dp[i][j][k][z]的取值。
4、初始化
题目规定乌龟棋子自动获得起点格子的分数,所以dp[0][0][0][0] = a[1]
5、输出结果
dp[cnt[1]][cnt[2]][cnt[3]][cnt[4]]
代码
1#include <iostream> 2#include <algorithm> 3using namespace std; 4 5const int N = 360; 6const int M = 50; 7 8int n, m; 9//存储棋盘 存储四张卡片各自数目 dp数组 10int a[N], cnt[5], dp[M][M][M][M]; 11 12int main() 13{ 14 //处理输入 15 cin >> n >> m; 16 for (int i = 1; i <= n; i++) 17 { 18 cin >> a[i]; 19 } 20 while (m--) 21 { 22 int x = 0; 23 cin >> x; 24 cnt[x]++; 25 } 26 //初始化 27 dp[0][0][0][0] = a[1]; 28 //按顺序填表 29 for (int i = 0; i <= cnt[1]; i++) 30 { 31 for (int j = 0; j <= cnt[2]; j++) 32 { 33 for (int k = 0; k <= cnt[3]; k++) 34 { 35 for (int z = 0; z <= cnt[4]; z++) 36 { 37 //x为当前访问格子下标(数组a下标) 38 int x = 1 + i + 2 * j + 3 * k + 4 * z; 39 int& t = dp[i][j][k][z]; 40 if(i > 0) 41 t = max(t, dp[i - 1][j][k][z] + a[x]); 42 if (j > 0) 43 t = max(t, dp[i][j - 1][k][z] + a[x]); 44 if (k > 0) 45 t = max(t, dp[i][j][k - 1][z] + a[x]); 46 if (z > 0) 47 t = max(t, dp[i][j][k][z - 1] + a[x]); 48 } 49 } 50 } 51 } 52 //输出结果 53 cout << dp[cnt[1]][cnt[2]][cnt[3]][cnt[4]] << endl; 54 return 0; 55} 56
以上就是小编分享的全部内容了,如果觉得不错还请留下免费的赞和收藏
如果有建议欢迎通过评论区或私信留言,感谢您的大力支持。
一键三连好运连连哦~~

《动态规划 线性 DP 经典四题一遍吃透》 是转载文章,点击查看原文。
