**一、流量作弊:程序化广告的隐形黑洞
程序化广告已成为数字营销的主流投放方式,但伴随着海量流量而来的,是日益猖獗的虚假流量产业链。根据中国互联网络信息中心发布的数据,截至2025年6月,我国网民规模已达11.23亿人,互联网普及率达79.7%。庞大的用户基数为黑灰产提供了可乘之机。
在程序化广告交易中,虚假流量问题尤为突出。据行业实测数据显示,某DSP平台日均处理超过50亿次广告竞价请求,其中约****30%的流量来自数据中心IP或代理IP**,这些流量中真正产生转化的不足0.5%,却消耗了平台近四分之一的竞价预算。广告主投入大量预算却收获甚微,根本原因在于无法快速判断广告请求IP是真实用户还是机房流量。
**二、识破伪装:机房流量与代理流量的技术特征
虚假流量主要来自两类技术手段,通过IP归属地和运营商数据可以精准识别:
| 虚假流量类型 | 技术特征 | 识别依据(IP归属地查询) |
|---|---|---|
| **机房流量 | 请求发自云服务器/VPS,IP归属于数据中心运营商 | net_type = 数据中心 |
| **代理流量 | 经过HTTP/SOCKS代理转发,IP归属地与用户位置不匹配 | threat_tags含“代理”,is_proxy = true |
这两类流量的共同问题是:IP类型不是真实的住宅宽带。通过专业的IP归属地查询平台,获取IP的网络类型(net_type),可以快速区分真实用户与虚假流量。更精细的检测则需要分析多维风险指标,包括IP是否被标记为代理、VPN、恶意节点等。
**实际案例:某DSP平台在部署IP归属地识别方案后,将无效流量占比从30%降至8%,广告主ROI平均提升22%。这不仅证明了IP归属地识别技术的有效性,也说明精准识别机房流量和代理流量是提升广告投放ROI的关键突破口。
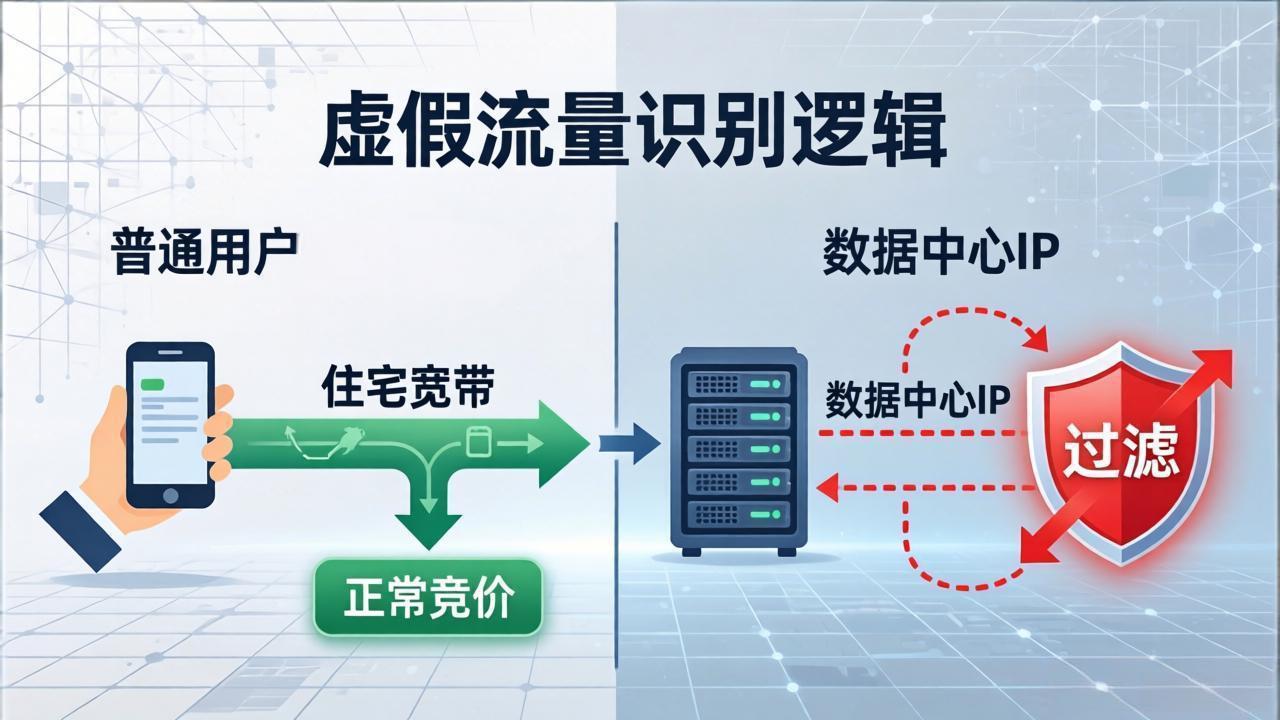
机房流量与住宅流量识别对比示意图
**三、代码实操:接入IP归属地API实现实时识别
以下展示如何在广告竞价系统中接入IP归属地API,实时识别并过滤虚假流量。
**3.1 Python脚本:批量验证IP归属地及网络类型
1# -*- coding: utf-8 -*- 2import requests 3 4# 初始化API(注册获取API密钥) 5API_KEY = "your_api_key" 6API_URL = "https://api.ipdatacloud.com/v2/query" 7 8def check_ip_risk(ip: str): 9 """ 10 查询IP归属地、网络类型及风险评分 11 返回字段包含:国家、城市、运营商(isp)、网络类型(net_type)、风险评分(risk_score) 12 注意:实际字段名请根据API返回格式调整 13 """ 14 params = {"ip": ip, "key": API_KEY} 15 try: 16 response = requests.get(API_URL, params=params, timeout=2) 17 if response.status_code != 200: 18 return {"ip": ip, "error": f"HTTP {response.status_code}"} 19 data = response.json() 20 return { 21 "ip": ip, 22 "country": data.get("country", ""), 23 "city": data.get("city", ""), 24 "isp": data.get("isp", ""), 25 "net_type": data.get("net_type", ""), # 关键字段:数据中心/住宅/移动 26 "risk_score": data.get("risk_score", 0) # 0-100分,越高越可疑 27 } 28 except Exception as e: 29 return {"ip": ip, "error": str(e)} 30 31def batch_check_ips(ip_list: list): 32 """批量检查IP列表,返回过滤判定结果""" 33 results = [] 34 for ip in ip_list: 35 result = check_ip_risk(ip) 36 # 过滤规则:数据中心IP或风险评分>70直接标记为作弊 37 if result.get("net_type") == "数据中心" or result.get("risk_score", 0) > 70: 38 result["verdict"] = "拦截_虚假流量" 39 else: 40 result["verdict"] = "通过_真实用户" 41 results.append(result) 42 return results 43 44# 示例:处理广告点击日志中的IP 45if __name__ == "__main__": 46 sample_ips = ["203.0.113.5", "114.114.114.114", "47.88.32.156"] 47 for r in batch_check_ips(sample_ips): 48 print(f"IP: {r['ip']}, 归属运营商: {r.get('isp')}, 网络类型: {r.get('net_type')}, 判定: {r.get('verdict')}")
**3.2 高并发场景:离线库部署方案(C语言实现)
对于日均请求量超过千万的广告平台,每次调用在线API会带来网络延迟和成本压力。更优的方案是部署离线IP数据库——将IP归属地数据加载到本地内存,实现毫秒级查询。
1#include <stdint.h> 2#include <stdlib.h> 3 4// IP记录结构体 5typedef struct { 6 uint32_t start_ip; // IP段起始(网络字节序转主机序后的整数值) 7 uint32_t end_ip; // IP段结束 8 uint16_t geo_id; // 地理位置ID 9 uint16_t risk_score; // 风险评分:0-100 10 uint8_t net_type; // 网络类型:0-住宅,1-数据中心,2-移动 11} ip_record_t; 12 13/** 14 * 二分查找IP对应的风险评分 15 * @param ip 待查询的IP(已转换为主机序的32位整数) 16 * @param records IP记录数组(需按start_ip升序排列) 17 * @param count 数组长度 18 * @return 风险评分,未命中返回0 19 */ 20uint16_t lookup_risk_score(uint32_t ip, ip_record_t* records, int count) { 21 // 防御性检查:空指针或空数组 22 if (records == NULL || count <= 0) { 23 return 0; 24 } 25 26 int left = 0, right = count - 1; 27 while (left <= right) { 28 // 使用位运算防止整数溢出,等价于 (left + right) / 2 29 int mid = left + ((right - left) >> 1); 30 if (ip < records[mid].start_ip) { 31 right = mid - 1; 32 } else if (ip > records[mid].end_ip) { 33 left = mid + 1; 34 } else { 35 return records[mid].risk_score; 36 } 37 } 38 return 0; // 默认低风险 39}
该方案使用内存映射(mmap)加载IP离线库,多个工作进程共享同一份物理内存,查询时无需加锁。实际压测显示,单机****QPS可达12.5万**,平均耗时0.08毫秒,比在线API调用快数百倍。
**四、决策策略:分级处置虚假流量
基于IP归属地和风险评分的分级过滤策略,可以有效平衡广告收益与风险:
| 风险等级 | 判定条件 | 处置方式 |
|---|---|---|
| **高危 | 数据中心IP + risk_score > 80 | 直接拦截,不参与竞价 |
| **中危 | 代理IP 或 risk_score 60-80 | 降价参与,设置低出价 |
| **低危 | 住宅IP + risk_score < 60 | 正常竞价 |
这种分级策略既过滤了最差的虚假流量,又保留了一部分边缘流量(可能是使用VPN办公的真实用户),实现了收益与风险的最优平衡。
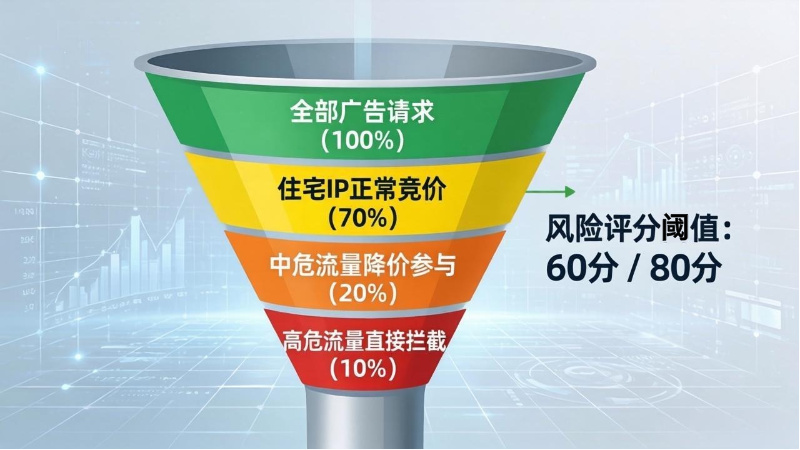
虚假流量分级过滤漏斗图展示拦截比例
**五、总结与建议
利用IP归属地和运营商数据进行虚假流量识别,是程序化广告反作弊中成本最低、响应最快的基础手段。企业在建设流量反欺诈体系时,建议遵循以下路径:
- **接入IP归属地API:快速验证方案可行性,识别机房IP和代理IP
- **部署离线IP数据库:针对高并发场景,将查询延迟降至毫秒级
- **建立分级决策策略:根据风险评分动态调整出价,而非一刀切拦截
**数据来源
- ****中国互联网络信息中心(CNNIC)**: 第56次《中国互联网络发展状况统计报告》,2025年7月
- **Statista: Global Digital Advertising Fraud Report 2025(程序化广告虚假流量占比及损失估算)
- **国家统计局: 互联网和相关服务业统计监测数据(2026年第一季度)
《营销数据分析:如何利用IP归属地识别和规避虚假流量》 是转载文章,点击查看原文。

