大家好我是小帅,今天学习mongodb的简单认识和基本命令。
本章内容:
- 理解MongoDB的业务场景、熟悉MongoDB的简介、特点和体系结构、数据类型等。
- 能够在Windows和Linux下安装和启动MongoDB、图形化管理界面Compass的安装使用
- 掌握MongoDB基本常用命令实现数据的CRUD 掌握MongoDB的索引类型、索引管理、执行计划。
- 使用Spring DataMongoDB完成文章评论业务的开发
文章目录
- 1. MongoDB认识
-
- 1.1 业务场景
- 1.2 结构体系
- 1.3 数据模型
- 1.4 MongoDB的特点
- 2. 基本常用命令
-
- 2.1 数据库操作
-
- 2.1.1选择和创建数据库
- 2.1.2 查看有权限查看的所有的数据库命令
- 2.1.3 查看当前正在使用的数据库命令
- 2.1.4 数据库的删除
- 2.1.1选择和创建数据库
- 2.2 集合操作
-
- 2.2.1 集合的显式创建(了解)
- 2.2.2查看当前库中的集合
- 2.2.3 集合的隐式创建
- 2.2.4 集合的删除
- 2.2.1 集合的显式创建(了解)
- 3. 文档基本CRUD
-
- 3.1 文档的插入
- 3.2文档的基本查询
-
- 3.2.1 查询所有
- 3.2.2投影查询(Projection Query)
- 3.2.1 查询所有
- 3.3 文档的更新
-
- 3.3.1 更新单个文档
- 3.3.2 更新多个文档
- 3.3.3 常用更新操作符
- 3.3.4 删除文档
- 3.3.1 更新单个文档
- 3.4 文档的分页查询
-
- 3.4.1 统计查询
- 3.4.2 分页列表查询
- 3.4.3 排序查询
- 3.4.1 统计查询
- 3.5 文档的更多查询
-
- 3.5.1 正则的复杂条件查询
- 3.5.2 比较查询
- 3.5.3 包含查询($in)
- 3.5.4 条件连接查询
- 3.5.1 正则的复杂条件查询
- 3.6 常用命令小结
- 4 索引-Index
-
- 4.1 索引的管理操作
-
- 4.1.1 索引的查看
- 4.1.2 索引的创建
- 4.1.3 索引的移除
- 4.1.1 索引的查看
- 4.2 索引的使用
- 4.3涵盖的查询(含索引的查询)
- 5. spring连接和使用
-
- 5.1 文章评论的基本增删改查
- 5.2 根据上级ID查询文章评论的分页列表
- 5.3 MongoTemplate实现评论点赞
1. MongoDB认识
1.1 业务场景
传统的关系型数据库(如MySQL),在数据操作的“三高”需求以及应对Web2.0的网站需求面前,显得力不从心。
解释:“三高”需求:
- 对数据库高并发读写的需求。
- 对海量数据的高效率存储和访问的需求。
- 对数据库的高可扩展性和高可用性的需求。
而MongoDB可应对“三高”需求。
具体的应用场景如:
1)社交场景,使用 MongoDB 存储存储用户信息,以及用户发表的朋友圈信息,通过地理位置索引实现附近的人、地点等功能。
2)游戏场景,使用 MongoDB 存储游戏用户信息,用户的装备、积分等直接以内嵌文档的形式存储,方便查询、高效率存储和访问。
3)物流场景,使用 MongoDB 存储订单信息,订单状态在运送过程中会不断更新,以 MongoDB 内嵌数组的形式来存储,一次查询就能将
订单所有的变更读取出来。
4)物联网场景,使用 MongoDB 存储所有接入的智能设备信息,以及设备汇报的日志信息,并对这些信息进行多维度的分析。
5)视频直播,使用 MongoDB 存储用户信息、点赞互动信息等。
这些应用场景中,数据操作方面的共同特点是:
- 数据量大
- 写入操作频繁(读写都很频繁)
- 价值较低的数据,对事务性要求不高
对于这样的数据,我们更适合使用MongoDB来实现数据的存储。
1.2 结构体系
MySQL和MongoDB对比
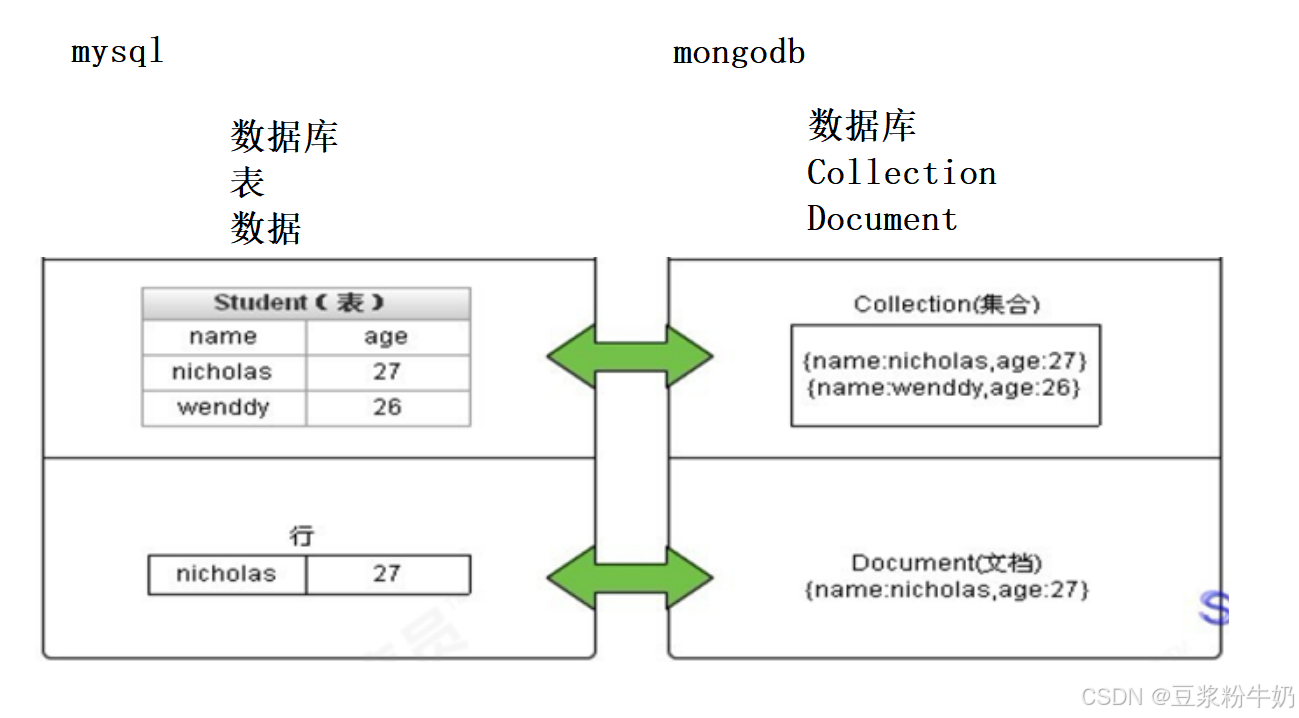
| SQL术语/概念 | MongoDB术语/概念 | 解释/说明 |
|---|---|---|
| database | database | 数据库 |
| table | collection | 数据库表/集合 |
| row | document | 数据记录行/文档 |
| column | field | 数据字段/域 |
| index | index | 索引 |
| table joins | 表连接,MongoDB不支持 | |
| 嵌入文档 | MongoDB通过嵌入式文档来替代多表连接 | |
| primary key | primary key | 主键,MongoDB自动将_id字段设置为主键 |
1.3 数据模型
- MongoDB的最小存储单位就是文档(document)对象。文档(document)对象对应于关系型数据库的行。数据在MongoDB中以BSON(Binary-JSON)文档的格式存储在磁盘上。
- BSON(Binary Serialized Document Format)是一种类json的一种二进制形式的存储格式,简称Binary JSON。BSON和JSON一样,支持内嵌的文档对象和数组对象,但是BSON有JSON没有的一些数据类型,如Date和BinData类型。
- BSON采用了类似于 C 语言结构体的名称、对表示方法,支持内嵌的文档对象和数组对象,具有轻量性、可遍历性、高效性的三个特点,可以有效描述非结构化数据和结构化数据。这种格式的优点是灵活性高,但它的缺点是空间利用率不是很理想。
- date,object id,binary data,regular expression 和code。每一个驱动都以特定语言的方式实现了这些类型,查看你的驱动的文档来获取详细信息。
BSON数据类型参考:
MongoDB的数据类型 一共包含哪些部分?使用场景是什么?底层原理是什么?
1.4 MongoDB的特点
MongoDB主要有如下特点:
- 高性能:
MongoDB提供高性能的数据持久性。特别是,对嵌入式数据模型的支持减少了数据库系统上的I/O活动。
索引支持更快的查询,并且可以包含来自嵌入式文档和数组的键。(文本索引解决搜索的需求、TTL索引解决历史数据自动过期的需求、地理位置索引可用于构建各种 O2O 应用)Gridfs解决文件存储的需求。 - 高可用性:
MongoDB的复制工具称为副本集(replica set),它可提供自动故障转移和数据冗余。 - 高扩展性:
MongoDB提供了水平可扩展性作为其核心功能的一部分。
分片将数据分布在一组集群的机器上。(海量数据存储,服务能力水平扩展)从3.4开始,MongoDB支持基于片键创建数据区域。在一个平衡的集群中,MongoDB将一个区域所覆盖的读写只定向到该区域内的那些片。 - 丰富的查询支持:
MongoDB支持丰富的查询语言,支持读和写操作(CRUD),比如数据聚合、文本搜索和地理空间查询等。
2. 基本常用命令
2.1 数据库操作
2.1.1选择和创建数据库
语法:
1use 数据库名 2
如果数据库不存在则自动创建,例如,以下语句创建 articledb数据库:
示例:
1use articledb 2
2.1.2 查看有权限查看的所有的数据库命令
语法:
1show dbs 2或 3show databases 4
注意: 在 MongoDB 中,集合只有在内容插入后才会创建! 就是说,创建集合(数据表)后要再插入一个文档(记录),集合才会真正创建。
2.1.3 查看当前正在使用的数据库命令
语法:
1db 2
MongoDB 中默认的数据库为 test,如果你没有选择数据库,集合将存放在 test 数据库中。
数据库名可以是满足以下条件的任意UTF-8字符串。
- 不能是空字符串(“”)。
- 不得含有’ '(空格)、.、$、/、\和\0 (空字符)。
- 应全部小写。
- 最多64字节。
有一些数据库名是保留的,可以直接访问这些有特殊作用的数据库。
- admin: 从权限的角度来看,这是"root"数据库。要是将一个用户添加到这个数据库,这个用户自动继承所有数据库的权限。一些特定的服务器端命令也只能从这个数据库运行,比如列出所有的数据库或者关闭服务器。
- local: 这个数据永远不会被复制,可以用来存储限于本地单台服务器的任意集合。
- config: 当Mongo用于分片设置时,config数据库在内部使用,用于保存分片的相关信息。
2.1.4 数据库的删除
MongoDB 删除数据库的语法格式如下:
1db.dropDatabase() 2
2.2 集合操作
集合,类似关系型数据库中的表。
可以显示的创建,也可以隐式的创建。
2.2.1 集合的显式创建(了解)
语法:
1db.createCollection(name) # name: 要创建的集合名称 2
示例:
1> db.createCollection("mycollection") 2< { ok: 1 } 3> show collections 4< mycollection 5
2.2.2查看当前库中的集合
1show collections 2或 3show tables 4
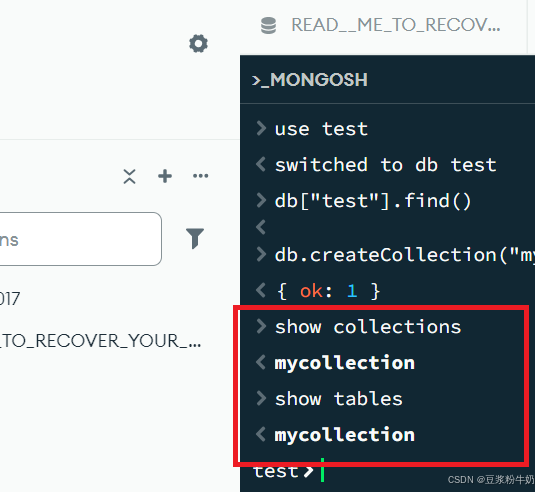
集合的命名规范:
- 集合名不能是空字符串""。
- 集合名不能含有\0字符(空字符),这个字符表示集合名的结尾。
- 集合名不能以"system."开头,这是为系统集合保留的前缀。
- 用户创建的集合名字不能含有保留字符。有些驱动程序的确支持在集合名里面包含,这是因为某些系统生成的集合中包含该字符。除非你要访问这种系统创建的集合,否则千万不要在名字里出现$。
2.2.3 集合的隐式创建
当向一个集合中插入一个文档的时候,如果集合不存在,则会自动创建集合,通常我们使用隐式创建文档即可。
字面意思演示不。
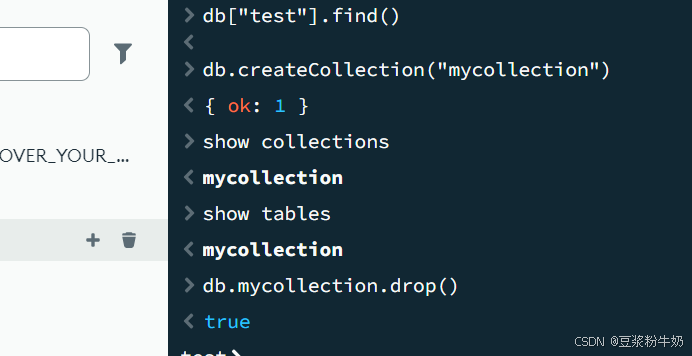
2.2.4 集合的删除
语法:
1db.collection.drop() 2或 3db.集合.drop() 4
返回值
如果成功删除选定集合,则 drop() 方法返回 true,否则返回 false。
例如:要删除mycollection集合
1db.mycollection.drop() 2
3. 文档基本CRUD
文档(document)的数据结构和 JSON 基本一样。
所有存储在集合中的数据都是 BSON 格式。
3.1 文档的插入
(1)单个文档插入
使用insert() 或 save() 方法向集合中插入文档,语法如下:
1db.collection.insert( 2 <document or array of documents>, 3 { 4 writeConcern: <document>, 5 ordered: <boolean> 6 } 7) 8
示例:
要向comment的集合(表)中插入一条测试数据:
1db.comment.insert({ 2 "articleid": "100000", 3 "content": "今天天气真好,阳光明媚", 4 "userid": "1001", 5 "nickname": "Rose", 6 "createdatetime": new Date(), 7 "likenum": NumberInt(10), 8 "state": null 9}); 10
提示:
- comment集合如果不存在,则会隐式创建
- mongo中的数字,默认情况下是double类型,如果要存整型,必须使用函数NumberInt(整型数字),否则取出来就有问题了。
- 插入当前日期使用 new Date()
- 插入的数据没有指定 _id ,会自动生成主键值
- 如果某字段没值,可以赋值为null,或不写该字段。
执行返回:
1{ 2 acknowledged: true, 3 insertedIds: { 4 '0': ObjectId('680caf8f687f6de08df5292b') 5 } 6} 7
说明插入一个数据成功了。
注意:
- 文档中的键/值对是有序的。
- 文档中的值不仅可以是在双引号里面的字符串,还可以是其他几种数据类型(甚至可以是整个嵌入的文档)。
- MongoDB区分类型和大小写。
- MongoDB的文档不能有重复的键。
- 文档的键是字符串。除了少数例外情况,键可以使用任意UTF-8字符。
文档键命名规范:
- 键不能含有\0 (空字符)。这个字符用来表示键的结尾。
- .和$有特别的意义,只有在特定环境下才能使用。
- 以下划线"_"开头的键是保留的(不是严格要求的)。
当然也可以批量插入:
1db.comment.insertMany([ 2 { 3 "_id": "4", 4 "articleid": "100001", 5 "content": "专家说不能空腹吃饭,影响健康。", 6 "userid": "1003", 7 "nickname": "凯撒", 8 "createdatetime": { "$date": "2019-08-06T08:18:35.288Z" }, 9 "likenum": 2000, 10 "state": "1" 11 }, 12 { 13 "_id": "5", 14 "articleid": "100001", 15 "content": "研究表明,刚烧开的水千万不能喝,因为烫嘴。", 16 "userid": "1003", 17 "nickname": "凯撒", 18 "createdatetime": { "$date": "2019-08-06T11:01:02.521Z" }, 19 "likenum": 3000, 20 "state": "1" 21 } 22]) 23
参数:
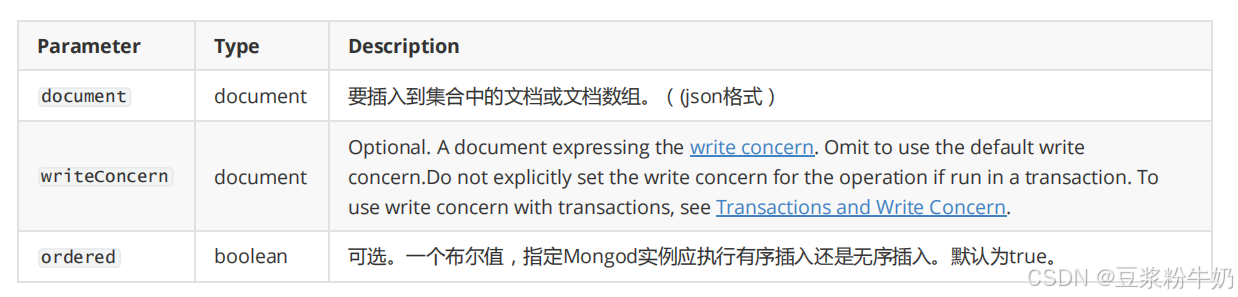
如果某条数据插入失败,将会终止插入,但已经插入成功的数据不会回滚掉。
因为批量插入由于数据较多容易出现失败,因此,可以使用try catch进行异常捕捉处理,测试的时候可以不处理。
1try { 2 db.comment.insertMany([ 3 { 4 "_id": "1", 5 "articleid": "100001", 6 "content": "我们不应该把清晨浪费在手机上,健康很重要,一杯温水幸福你我他。", 7 "userid": "1002", 8 "nickname": "相忘于江湖", 9 "createdatetime": new Date("2019-08-05T22:08:15.522Z"), 10 "likenum": NumberInt(1000), 11 "state": "1" 12 }, 13 { 14 "_id": "2", 15 "articleid": "100001", 16 "content": "我夏天空腹喝凉开水,冬天喝温开水", 17 "userid": "1005", 18 "nickname": "伊人憔悴", 19 "createdatetime": new Date("2019-08-05T23:58:51.485Z"), 20 "likenum": NumberInt(888), 21 "state": "1" 22 }, 23 { 24 "_id": "3", 25 "articleid": "100001", 26 "content": "我一直喝凉开水,冬天夏天都喝。", 27 "userid": "1004", 28 "nickname": "杰克船长", 29 "createdatetime": new Date("2019-08-06T01:05:06.321Z"), 30 "likenum": NumberInt(666), 31 "state": "1" 32 }, 33 { 34 "_id": "4", 35 "articleid": "100001", 36 "content": "专家说不能空腹吃饭,影响健康。", 37 "userid": "1003", 38 "nickname": "凯撒", 39 "createdatetime": new Date("2019-08-06T08:18:35.288Z"), 40 "likenum": NumberInt(2000), 41 "state": "1" 42 }, 43 { 44 "_id": "5", 45 "articleid": "100001", 46 "content": "研究表明,刚烧开的水千万不能喝,因为烫嘴。", 47 "userid": "1003", 48 "nickname": "凯撒", 49 "createdatetime": new Date("2019-08-06T11:01:02.521Z"), 50 "likenum": NumberInt(3000), 51 "state": "1" 52 } 53 ]); 54} catch (e) { 55 print(e); 56} 57
3.2文档的基本查询
语法:
1db.collection.find(<query>, [projection]) 2
3.2.1 查询所有
如果我们要查询spit集合的所有文档,我们输入以下命令
1db.comment.find() 2或 3db.comment.find({}) 4
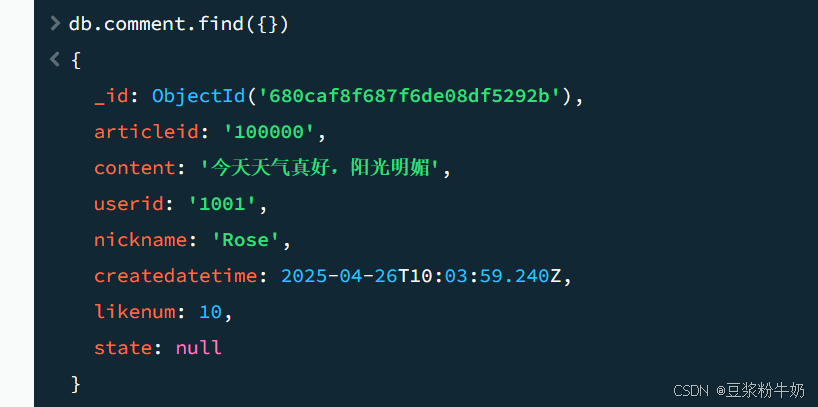
这里你会发现每条文档会有一个叫_id的字段,这个相当于我们原来关系数据库中表的主键,当你在插入文档记录时没有指定该字段,
MongoDB会自动创建,其类型是ObjectID类型。
如果我想按一定条件来查询,比如我想查询userid为1003的记录,怎么办?很简单!只 要在find()中添加参数即可,参数也是json格式,如下:
1db.comment.find({userid:'1003'}) 2
3.2.2投影查询(Projection Query)
如果要查询结果返回部分字段,则需要使用投影查询(不显示所有字段,只显示指定的字段)。
命令:
1db.comment.find({userid:"1003"},{userid:1,nickname:1}) 2
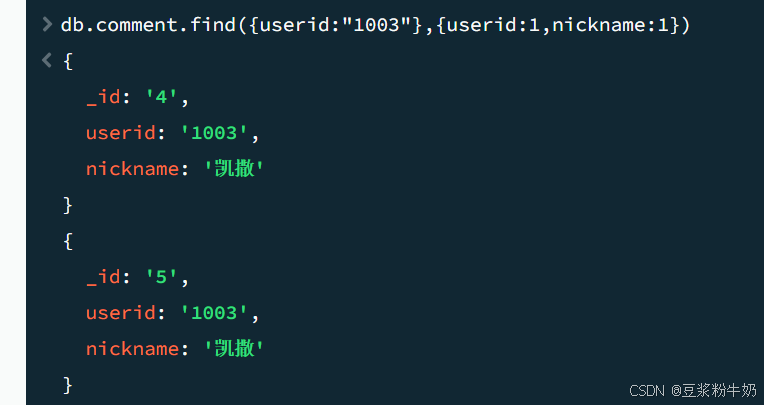
这里后面的{userid:1,nickname:1}为userid:1显示。
默认 _id 会显示。
如:查询结果只显示 、userid、nickname ,不显示 _id :
1db.comment.find({userid:"1003"},{userid:1, nickname:1,_id:0}) 2
再例如:查询所有数据,但只显示 _id、userid、nickname:
1db.comment.find({},{userid:1,nickname:1}) 2
3.3 文档的更新
3.3.1 更新单个文档
语法:
1db.collection.updateMany( 2 <filter>, // 查询条件 3 <update>, // 更新操作符 4 { // 可选参数 5 upsert: <boolean>, 6 collation: <document>, 7 arrayFilters: <array> 8 } 9) 10
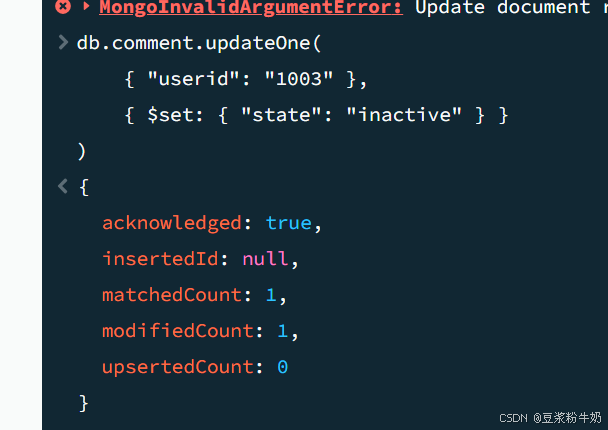
示例 1:更新 userid 为 “1003” 的第一个文档的 state 字段
1db.comment.updateOne( 2 { "userid": "1003" }, 3 { $set: { "state": "inactive" } } 4) 5
在这个例子中,我们使用 $set 操作符来更新文档中的特定字段。如果没有找到符合条件的文档,默认情况下不会执行任何操作。
3.3.2 更新多个文档
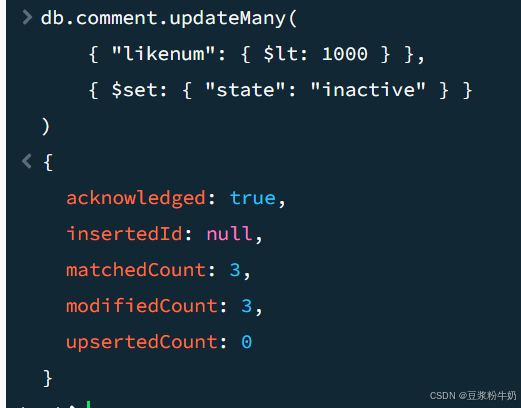
如果你想要更新所有符合条件的文档,可以使用 updateMany 方法。
语法:
1db.collection.updateMany( 2 <filter>, // 查询条件 3 <update>, // 更新操作符 4 { // 可选参数 5 upsert: <boolean>, 6 arrayFilters: <array> 7 } 8) 9
示例:
将所有 likenum 小于 1000 的文档的 state 字段更新为 “inactive”
1db.comment.updateMany( 2 { "likenum": { $lt: 1000 } }, 3 { $set: { "state": "inactive" } } 4) 5
3.3.3 常用更新操作符
- $set 设置字段值
$set 用于更新或添加文档中的字段。如果字段不存在,则会创建该字段。
1db.comment.updateOne( 2 { "_id": "1" }, 3 { $set: { "content": "新的内容" } } 4) 5
- $inc 增加或减少数值
$inc 用于增加或减少数值字段的值。
1db.comment.updateOne( 2 { "userid": "1003" }, 3 { $inc: { "likenum": 100 } } 4) 5
- $unset 删除字段
$unset 用于从文档中删除指定字段。
1db.comment.updateOne( 2 { "_id": "1" }, 3 { $unset: { "state": "" } } 4) 5
- $push 向数组字段添加元素
$push 用于向数组字段添加一个或多个元素。
1db.comment.updateOne( 2 { "_id": "1" }, 3 { $push: { "tags": "健康" } } 4) 5
- $pull 从数组字段中移除元素
$pull 用于从数组字段中移除指定元素。
1db.comment.updateOne( 2 { "_id": "1" }, 3 { $pull: { "tags": "健康" } } 4) 5
- $addToSet 避免重复元素
$addToSet 类似于 $push,但它只会添加不重复的元素。
1db.comment.updateOne( 2 { "_id": "1" }, 3 { $addToSet: { "tags": "健康" } } 4) 5
3.3.4 删除文档
deleteOne:删除符合条件的第一个文档。
deleteMany:删除所有符合条件的文档。
语法:
1db.collection.deleteOne( 2 <filter>, // 查询条件 3 { // 可选参数 4 collation: <document> // 指定文本比较规则 5 } 6) 7 8db.collection.deleteMany( 9 <filter>, // 查询条件 10 { // 可选参数 11 collation: <document> // 指定文本比较规则 12 } 13) 14
删除单个文档:deleteOne
删除 _id 为 “1” 的第一个文档
示例:
1db.comment.deleteOne({ "_id": "1" }) 2或者 3db.comment.remove({_id:"1"}) 4
删除多个文档:deleteMany
删除所有 likenum 小于 500 的文档
示例:
1db.comment.deleteMany({ "likenum": { $lt: 500 } }) 2
删除所有文档
如果你想要删除集合中的所有文档,可以使用空查询条件 {}:
1db.comment.deleteMany({}) 2
这将删除集合中的所有文档,但不会删除集合本身。
3.4 文档的分页查询
3.4.1 统计查询
统计查询使用count()方法。
语法:
1db.collection.count(query, options) 2
参数:

示例1:
统计comment集合的所有的记录数:
1db.comment.count() 2
示例2:
统计userid为1003的记录条数
1db.comment.count({userid:"1003"}) 2
默认情况下 count() 方法返回符合条件的全部记录条数。
3.4.2 分页列表查询
skip(n):跳过查询结果中的前 n 个文档。
limit(m):限制返回的结果数量为 m 条记录。
语法:
1db.comment.find().limit(NUMBER).skip(NUMBER) 2
示例:
分页查询:需求:每页2个,第二页开始:跳过前两条数据,接着值显示3和4条数据
1//第一页 2db.comment.find().skip(0).limit(2) 3//第二页 4db.comment.find().skip(2).limit(2) 5//第三页 6db.comment.find().skip(4).limit(2) 7
3.4.3 排序查询
sort() 方法对数据进行排序,sort() 方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而 -1 是用于降序排列。
语法:
1db.comment.find().sort({KEY:1}) 2或 3db.集合名称.find().sort(排序方式) 4
示例:
对userid降序排列,并对访问量进行升序排列(混合)
1db.comment.find().sort({userid:-1,likenum:1}) 2
skip(), limilt(), sort()三个放在一起执行的时候,执行的顺序是先sort(), 然后是 skip(),最后是显示的 limit(),和命令编写顺序无关。
3.5 文档的更多查询
3.5.1 正则的复杂条件查询
MongoDB的模糊查询是通过正则表达式的方式实现的。格式为:
1db.collection.find({field:/正则表达式/}) 2或 3db.集合.find({字段:/正则表达式/}) 4
提示:正则表达式是js的语法,直接量的写法。
例如,我要查询评论内容包含“开水”的所有文档,代码如下:
1db.comment.find({content:/开水/}) 2
如果要查询评论的内容中以“专家”开头的,代码如下:
1db.comment.find({content:/^专家/}) 2
正则表达是的操作还有很多,这里就不多讲了。
3.5.2 比较查询
<, <=, >, >= 这个操作符也是很常用的,格式如下:
1db.集合名称.find({ "field" : { $gt: value }}) // 大于: field > value 2db.集合名称.find({ "field" : { $lt: value }}) // 小于: field < value 3db.集合名称.find({ "field" : { $gte: value }}) // 大于等于: field >= value 4db.集合名称.find({ "field" : { $lte: value }}) // 小于等于: field <= value 5db.集合名称.find({ "field" : { $ne: value }}) // 不等于: field != value 6
示例:查询评论点赞数量大于700的记录
1db.comment.find({likenum:{$gt:NumberInt(700)}}) 2
3.5.3 包含查询($in)
包含使用$in操作符。 示例:查询评论的集合中userid字段包含1003或1004的文档
1db.comment.find({userid:{$in:["1003","1004"]}}) 2
不包含使用$nin操作符。 示例:查询评论集合中userid字段不包含1003和1004的文档
1db.comment.find({userid:{$nin:["1003","1004"]}}) 2
3.5.4 条件连接查询
我们如果需要查询同时满足两个以上条件,需要使用$and操作符将条件进行关联。(相 当于SQL的and) 格式为:
1$and:[ { },{ },{ } ] 2
示例:查询评论集合中likenum大于等于700 并且小于2000的文档:
1db.comment.find({$and:[{likenum:{$gte:NumberInt(700)}},{likenum:{$lt:NumberInt(2000)}}]}) 2
如果两个以上条件之间是或者的关系,我们使用 操作符进行关联,与前面 and的使用方式相同 格式为:
1$or:[ { },{ },{ } ] 2
示例:查询评论集合中userid为1003,或者点赞数小于1000的文档记录:
1db.comment.find({$or:[ {userid:"1003"} ,{likenum:{$lt:1000} }]}) 2
3.6 常用命令小结
1选择切换数据库:use articledb 2插入数据:db.comment.insert({bson数据}) 3查询所有数据:db.comment.find(); 4条件查询数据:db.comment.find({条件}) 5查询符合条件的第一条记录:db.comment.findOne({条件}) 6查询符合条件的前几条记录:db.comment.find({条件}).limit(条数) 7查询符合条件的跳过的记录:db.comment.find({条件}).skip(条数) 8修改数据:db.comment.update({条件},{修改后的数据}) 或db.comment.update({条件},{$set:{要修改部分的字段:数据}) 9修改数据并自增某字段值:db.comment.update({条件},{$inc:{自增的字段:步进值}}) 10删除数据:db.comment.remove({条件}) 11统计查询:db.comment.count({条件}) 12模糊查询:db.comment.find({字段名:/正则表达式/}) 13条件比较运算:db.comment.find({字段名:{$gt:值}}) 14包含查询:db.comment.find({字段名:{$in:[值1,值2]}})或db.comment.find({字段名:{$nin:[值1,值2]}}) 15条件连接查询:db.comment.find({$and:[{条件1},{条件2}]})或db.comment.find({$or:[{条件1},{条件2}]}) 16
4 索引-Index
学过算法或者是mysql的同学应该不陌生索引。
MongoDB还支持多个字段的用户定义索引,即复合索引(Compound Index)。
复合索引中列出的字段顺序具有重要意义。例如,如果复合索引由 { userid: 1, score: -1 } 组成,则索引首先按userid正序排序,然后在每个userid的值内,再在按score倒序排序。
还有一些其他的索引,比如说:
地理空间索引(Geospatial Index)
为了支持对地理空间坐标数据的有效查询,MongoDB提供了两种特殊的索引:返回结果时使用平面几何的二维索引和返回结果时使用球面几何的二维球面索引。
文本索引(Text Indexes)
MongoDB提供了一种文本索引类型,支持在集合中搜索字符串内容。这些文本索引不存储特定于语言的停止词(例如“the”、“a”、“or”),而将集合中的词作为词干,只存储根词。
哈希索引(Hashed Indexes)
为了支持基于散列的分片,MongoDB提供了散列索引类型,它对字段值的散列进行索引。这些索引在其范围内的值分布更加随机,但只支持相等匹配,不支持基于范围的查询。
4.1 索引的管理操作
4.1.1 索引的查看
说明:
返回一个集合中的所有索引的数组。
语法:
1db.collection.getIndexes() 2
提示:该语法命令运行要求是MongoDB 3.0+
示例:
查看comment集合中所有的索引情况

结果中显示的是默认 _id 索引。
默认_id索引:
1> db.comment.getIndexes() 2 3
MongoDB在创建集合的过程中,在 _id 字段上创建一个唯一的索引,默认名字为 id ,该索引可防止客户端插入两个具有相同值的文档,您不能在_id字段上删除此索引。
注意:该索引是唯一索引,因此值不能重复,即 _id 值不能重复的。在分片集群中,通常使用 _id 作为片键。
4.1.2 索引的创建
在集合上创建索引。
语法:
1db.collection.createIndex(keys, options) 2
参数:

提示:
注意在 3.0.0 版本前创建索引方法为 db.collection.ensureIndex() ,之后的版本使用了 db.collection.createIndex() 方法,ensureIndex() 还能用,但只是 createIndex() 的别名。
示例:
(1)单字段索引示例:对 userid 字段建立索引:
1db.comment.createIndex({userid:1}) 2
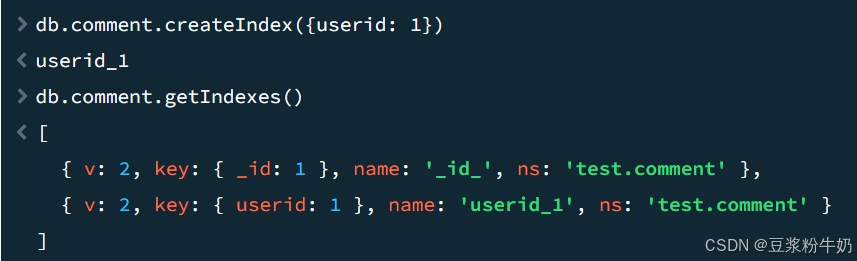
2)复合索引:对 userid 和 nickname 同时建立复合(Compound)索引:
1db.comment.createIndex({userid:1,nickname:-1}) 2
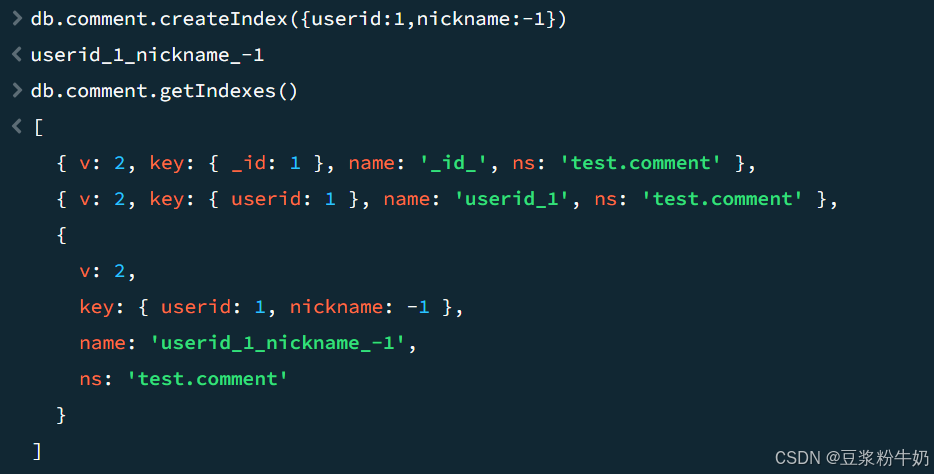
4.1.3 索引的移除
说明:可以移除指定的索引,或移除所有索引
一、指定索引的移除
语法:
1db.collection.dropIndexes() 2
示例1:
指定删除索引
1db.comment.dropIndex("userid_1") 2
查看:

删除:

删除 spit 集合中所有索引。
语法:
1db.collection.dropIndexes() 2
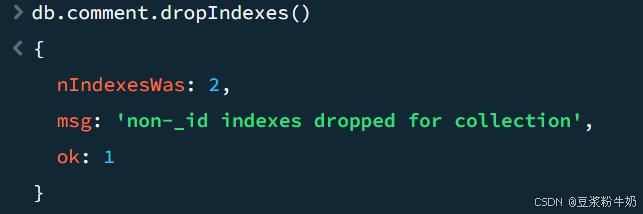
提示: _id 的字段的索引是无法删除的,只能删除非 _id 字段的索引。
4.2 索引的使用
分析查询性能(Analyze Query Performance)通常使用执行计划(解释计划、Explain Plan)来查看查询的情况,如查询耗费的时间、是
否基于索引查询等。
那么,通常,我们想知道,建立的索引是否有效,效果如何,都需要通过执行计划查看。
语法:
1db.collection.find(query,options).explain(options) 2
比如说:
查看根据userid查询数据的情况:
语法:
1db.collection.find(query,options).explain(options) 2
1db.comment.find({userid:"1003"}).explain() 2
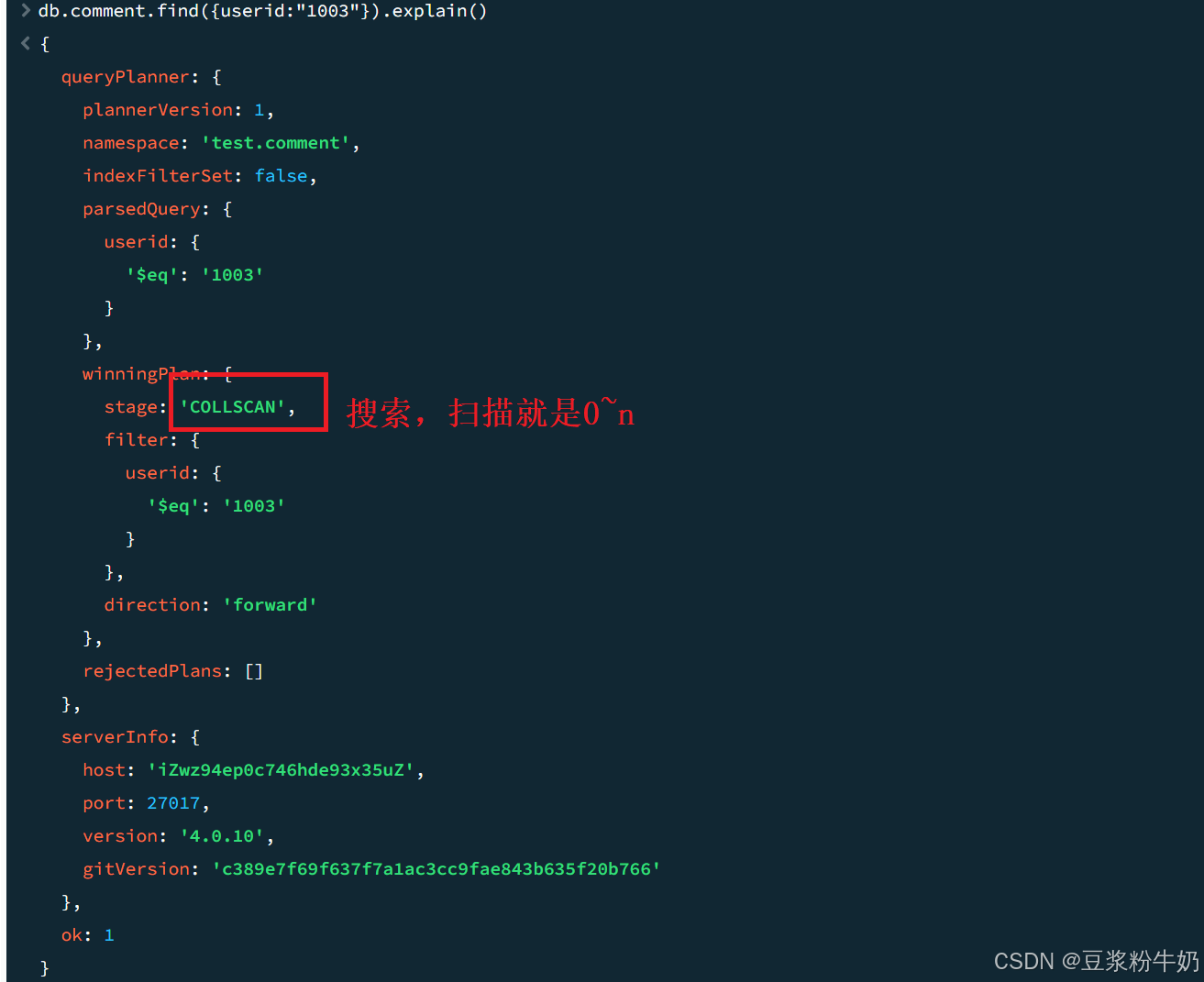
关键点看: “stage” : “COLLSCAN”, 表示全集合扫描
下面对userid建立索引
1db.comment.createIndex({userid:1}) 2
关键点看: “stage” : “IXSCAN” ,基于索引的扫描
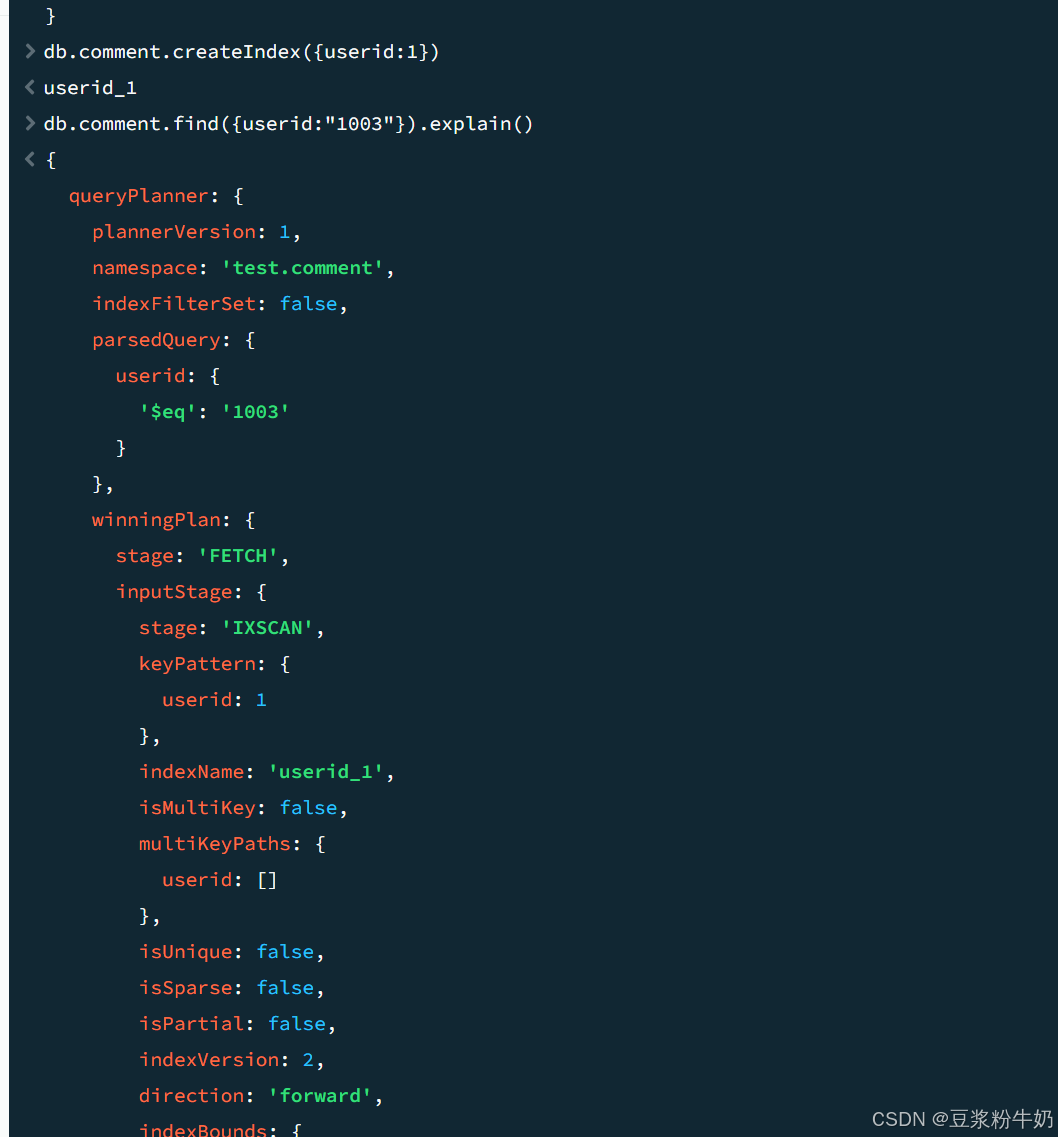
compass查看:
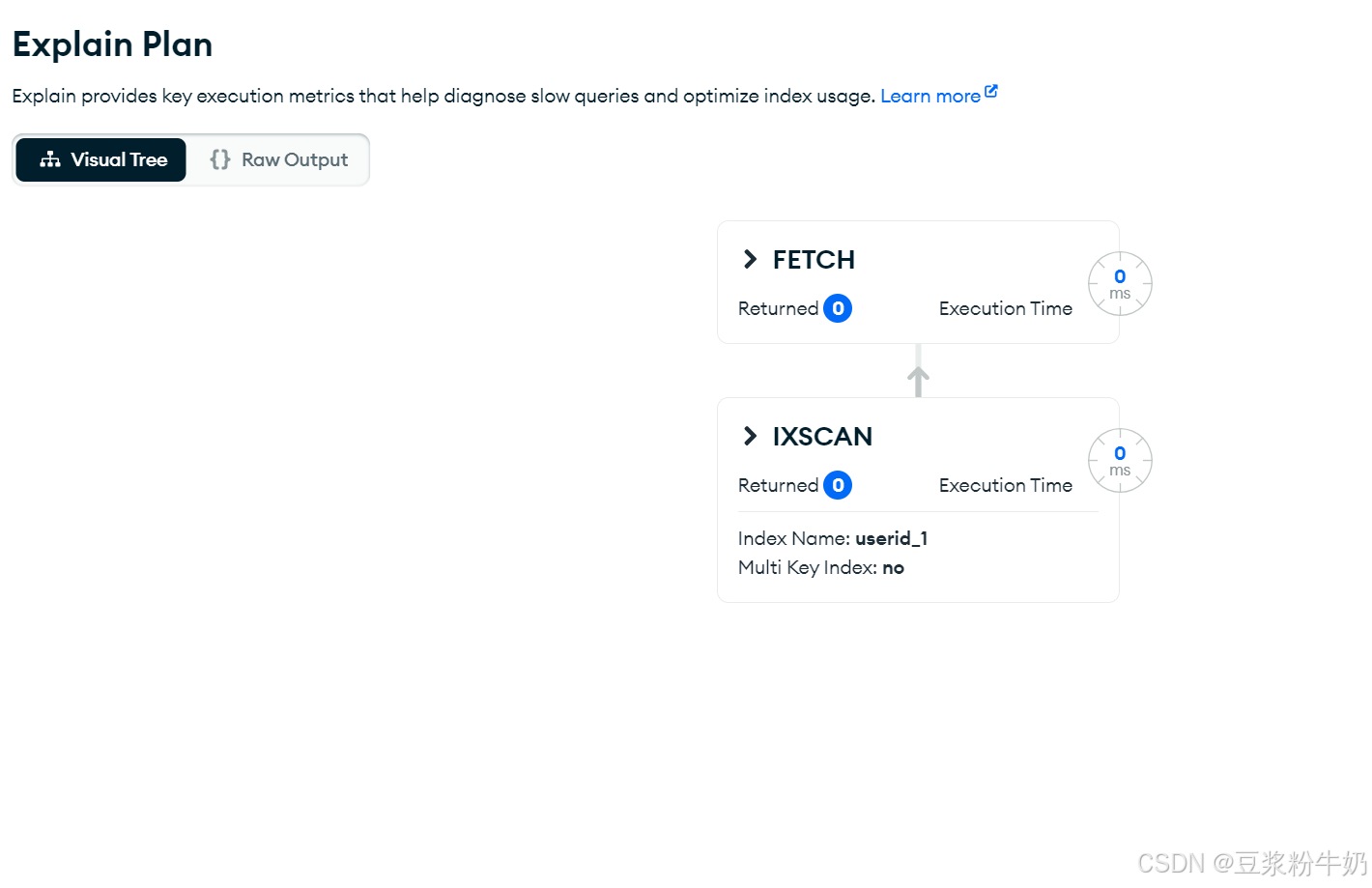
数据量太小,所以查询时间都无限接近于0
4.3涵盖的查询(含索引的查询)
当查询条件和查询的投影仅包含索引字段时,MongoDB直接从索引返回结果,而不扫描任何文档或将文档带入内存。 这些覆盖的查询可以非常有效。
示例:
1db.comment.find({userid:"1003"},{userid:1,_id:0}) 2
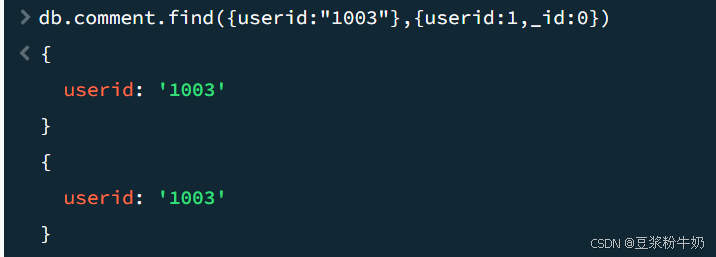
还可以这样
1db.comment.find({userid:"1003"},{userid:1,_id:0}).explain() 2
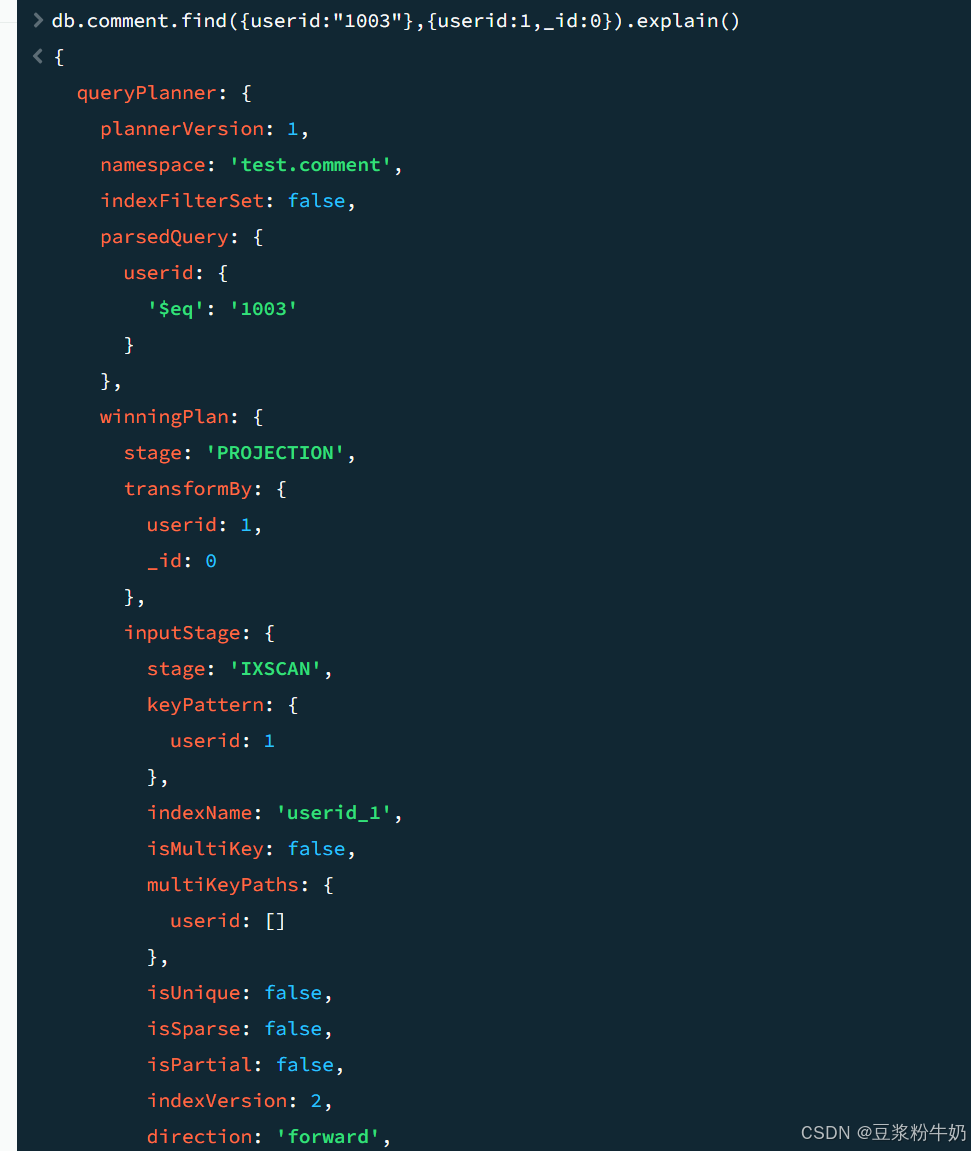
5. spring连接和使用
依赖引入
1<dependency> 2 <groupId>org.springframework.boot</groupId> 3 <artifactId>spring-boot-starter-data-mongodb</artifactId> 4</dependency> 5
配置连接yml
1spring: 2 #数据源配置 3 data: 4 mongodb: 5 # 主机地址 6 host: 47.119.155.67 7 # 数据库 8 database: cdm 9 # 默认端口是27017 10 port: 27017 11 #也可以使用uri连接 12 #uri: mongodb://192.168.40.134:27017/articledb 13
创建实体类
1/** 2 * 文章评论实体类 3 */ 4//把一个java类声明为mongodb的文档,可以通过collection参数指定这个类对应的文档。 5//@Document(collection="mongodb 对应 collection 名") 6// 若未加 @Document ,该 bean save 到 mongo 的 comment collection 7// 若添加 @Document ,则 save 到 comment collection 8 9@Data 10@Document(collection = "comment")//可以省略,如果省略,则默认使用类名小写映射集合 11//复合索引 12// @CompoundIndex( def = "{'userid': 1, 'nickname': -1}") 13public class Comment implements Serializable { 14 //主键标识,该属性的值会自动对应mongodb的主键字段"_id",如果该属性名就叫“id”,则该注解可以省略,否则必须写 15 @Id 16 private String id;//主键 17 //该属性对应mongodb的字段的名字,如果一致,则无需该注解 18 @Field("content") 19 private String content;//吐槽内容 20 private Date publishtime;//发布日期 21 //添加了一个单字段的索引 22 @Indexed 23 private String userid;//发布人ID 24 private String nickname;//昵称 25 private Date createdatetime;//评论的日期时间 26 private Integer likenum;//点赞数 27 private Integer replynum;//回复数 28 private String state;//状态 29 private String parentid;//上级ID 30 private String articleid; 31 32 @Override 33 public String toString() { 34 return "Comment{" + 35 "id='" + id + '\'' + 36 ", content='" + content + '\'' + 37 ", publishtime=" + publishtime + 38 ", userid='" + userid + '\'' + 39 ", nickname='" + nickname + '\'' + 40 ", createdatetime=" + createdatetime + 41 ", likenum=" + likenum + 42 ", replynum=" + replynum + 43 ", state='" + state + '\'' + 44 ", parentid='" + parentid + '\'' + 45 ", articleid='" + articleid + '\'' + 46 '}'; 47 } 48} 49
5.1 文章评论的基本增删改查
(1)创建数据访问接口 cn.itcast.article包下创建dao包,包下创建接口
1public interface CommentRepository extends MongoRepository<Comment, String > {//这里有点类似于MyBatis-Plus 2 /** 3 * 实现分页u 4 * 这里一定要注意一下 findByParentid 类名一定要是这个,findBy是MongoRepository传入Comment泛型实现好的。 5 * findBy是固定后面要接Comment属性名 6 */ 7 public Page<Comment> findByParentid(String parentid, Pageable pageable); 8 9} 10 11
(2)创建业务逻辑类 cn.itcast.article包下创建service包,包下创建类
1@Service 2public class CommentService { 3 @Autowired 4 public CommentRepository commentRepository; //封装 5 6 @Autowired 7 public MongoTemplate mongoTemplate; //原生 8 9 /** 10 * 保存一个评论(添加) 11 */ 12 public void saveComment(Comment comment){ 13 commentRepository.save(comment); 14 } 15 /** 16 * 更新评论 17 */ 18 19 public void updateComment(Comment comment){ 20 commentRepository.save(comment); 21 } 22 23 /** 24 * 删除id的评论 25 * @param id 26 */ 27 public void deleteComment(String id){ 28 commentRepository.deleteById(id); 29 } 30 31 /** 32 * 查询所有评论 33 * 34 */ 35 public List<Comment> findComment(){ 36 return commentRepository.findAll(); 37 } 38 39 /** 40 * 根据id查询评论 41 */ 42 public Comment findCommentById(String id){ 43 return commentRepository.findById(id).get(); 44 } 45 46 /** 47 * 实现分页 48 */ 49 public Page<Comment> findCommentByPage(String parentid, int page, int size){ 50 //从第0页开始,所以要减1,size是每页多少条数据,根据parentid来查 51 return commentRepository.findByParentid(parentid, PageRequest.of(page - 1, size)); 52 } 53 54 /** 55 * 实现评论数加1 56 */ 57 public void incrById(String id){ 58 //构建参数列表 59 Query query = new Query(Criteria.where("id").is(id)); //这个方法是mongodb内部实现的,底层是mongodb命令行 60 Update update = new Update(); //这个类是mongodb的命令封装 61 update.inc("likenum"); 62 mongoTemplate.updateFirst(query, update, Comment.class); 63 } 64} 65
5.2 根据上级ID查询文章评论的分页列表
(1)CommentRepository新增方法定义
1//根据父id,查询子评论的分页列表 2Page<Comment> findByParentid(String parentid, Pageable pageable); //这里的接口名字要注意 3
(2)CommentService新增方法
1/** 2* 根据父id查询分页列表 3* @param parentid 4* @param page 5* @param size 6* @return 7*/ 8public Page<Comment> findCommentListPageByParentid(String parentid,int page ,int size){ 9 return commentRepository.findByParentid(parentid, PageRequest.of(page-1,size)); 10} 11
5.3 MongoTemplate实现评论点赞
MongoTemplate实现评论点赞
1/** 2* 点赞-效率低 3* @param id 4*/ 5public void updateCommentThumbupToIncrementingOld(String id){ 6 Comment comment = CommentRepository.findById(id).get(); 7 comment.setLikenum(comment.getLikenum()+1); 8 CommentRepository.save(comment); 9} 10
以上方法虽然实现起来比较简单,但是执行效率并不高,因为我只需要将点赞数加1就可以了,没必要查询出所有字段修改后再更新所有字段。(蝴蝶效应)
我们可以使用MongoTemplate类来实现对某列的操作。
1@Service 2public class CommentService { 3 @Autowired 4 public CommentRepository commentRepository; //封装 5 6 @Autowired 7 public MongoTemplate mongoTemplate; //原生 8 9 /** 10 * 实现分页 11 */ 12 public Page<Comment> findCommentByPage(String parentid, int page, int size){ 13 //从第0页开始,所以要减1,size是每页多少条数据,根据parentid来查 14 return commentRepository.findByParentid(parentid, PageRequest.of(page - 1, size)); 15 } 16 17 /** 18 * 实现评论数加1 19 */ 20 public void incrById(String id){ 21 //构建参数列表 22 Query query = new Query(Criteria.where("id").is(id)); //这个方法是mongodb内部实现的,底层是mongodb命令行 23 Update update = new Update(); //这个类是mongodb的命令封装 24 update.inc("likenum"); 25 mongoTemplate.updateFirst(query, update, Comment.class); 26 } 27} 28} 29
好了,mongodb的学习就到这里,感谢观看。
《mongodb的基本命令》 是转载文章,点击查看原文。

