【深度学习基础篇】从回归到分类:图像分类与卷积神经网络入门
文章目录
- 【深度学习基础篇】从回归到分类:图像分类与卷积神经网络入门
- 一、前情提要:从回归实战到分类任务的核心转变
-
- 回归与分类的核心区别:输出逻辑的本质不同
-
- 分类任务的输出解码:从“置信度”到“类别标签”
- 二、图像分类的前提:理解图像的张量表示
-
- 1. 图像的核心维度:通道×高度×宽度(C×H×W)
- 2. 批量图像的张量格式:N×C×H×W
- 3. 全连接层处理图像的痛点:维度爆炸
- 三、卷积的核心概念:从“局部感知”到特征提取
-
- 1. 卷积核(Kernel/Filter):图像的“特征探测器”
- 2. 卷积运算:局部加权求和
- 3. 感受野(Receptive Field):特征对应的图像区域
- 四、缩小特征图:步长与池化的核心作用
-
- 1. 步长(Stride):控制卷积核的滑动距离
- 2. 池化(Pooling):无参数的下采样
- 3. 填充(Padding):保持特征图尺寸
- 4. 实战计算:卷积输出尺寸与参数量
-
- 1. 输出特征图尺寸计算公式
- 2. 例题1:计算输出尺寸与参数量
- 3. 例题2:步长过大导致信息丢失
- Q&A:既然池化能降维,为什么还需要卷积?
- 1. 输出特征图尺寸计算公式
- 五、手搓一个简单的卷积神经网络:从图像到类别
-
- 5.1 从 `3×224×224` 到 `1024×7×7`:特征提取与下采样
-
- 核心思路
- 示例网络结构
- 核心思路
- 5.2 从 `1024×7×7` 到类别预测:卷积到全连接的桥梁
-
- 方式一:直接展平(Flatten)
- 方式二:全局平均/最大池化(Global Pooling)
- 方式一:直接展平(Flatten)
- 5.3 Softmax:从“置信度”到“概率分布”
-
- Softmax 公式
- 5.4 分类任务的损失函数:交叉熵损失(Cross-Entropy Loss)
-
- 多分类交叉熵公式
- 示例计算
- 多分类交叉熵公式
- 5.5 完整流程总结
- 六、总结:从分类任务到卷积的核心逻辑
一、前情提要:从回归实战到分类任务的核心转变
在“回归实战”章节中,我们已经掌握了全连接层 nn.Linear(A, B) 的核心用法——它能将维度为A的输入矩阵,映射到维度为B的隐藏特征空间;通过堆叠多层全连接层,还能加深网络深度、增强模型的拟合能力。同时,我们也吃透了梯度下降算法的落地逻辑:包括数据集读取、模型定义、训练流程的完整闭环,这是深度学习的通用基础,可总结为下图的核心流程:
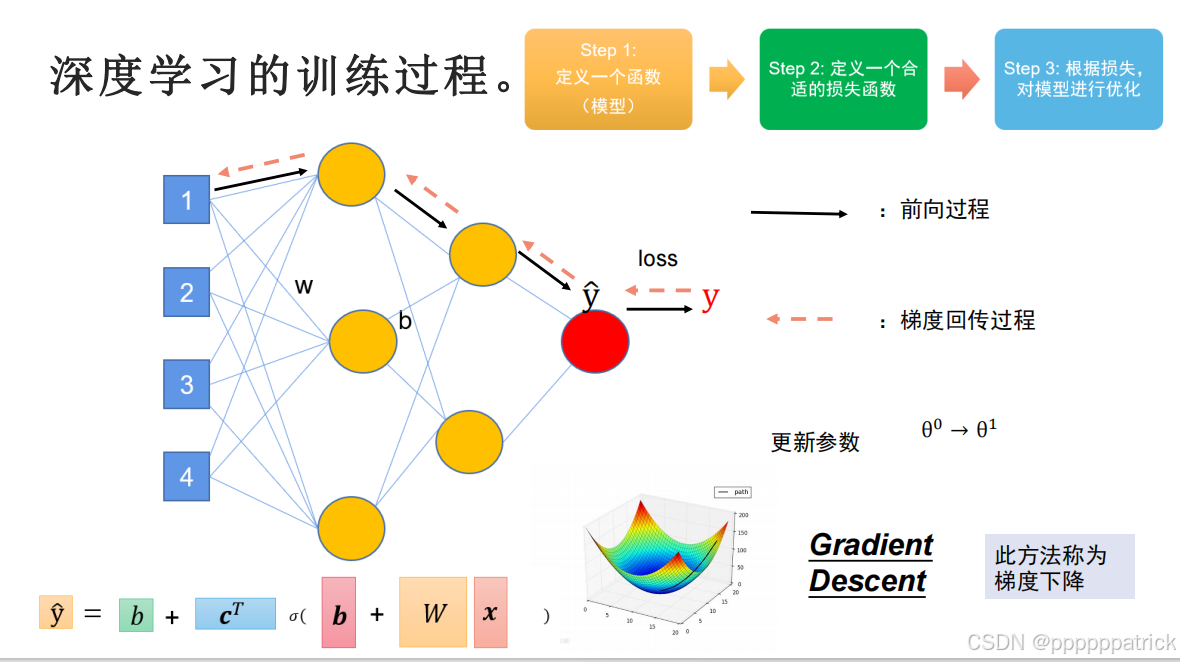
但真实的深度学习场景中,除了“预测具体数值”的回归任务,更常见的是“判断类别归属”的分类任务;而分类任务中最典型的场景就是图像分类——这意味着我们不仅要理解分类任务的输出逻辑,还要掌握“如何向神经网络输入图片数据”这一核心技能。
回归与分类的核心区别:输出逻辑的本质不同
回归任务和分类任务的核心差异,首先体现在输出目标上:
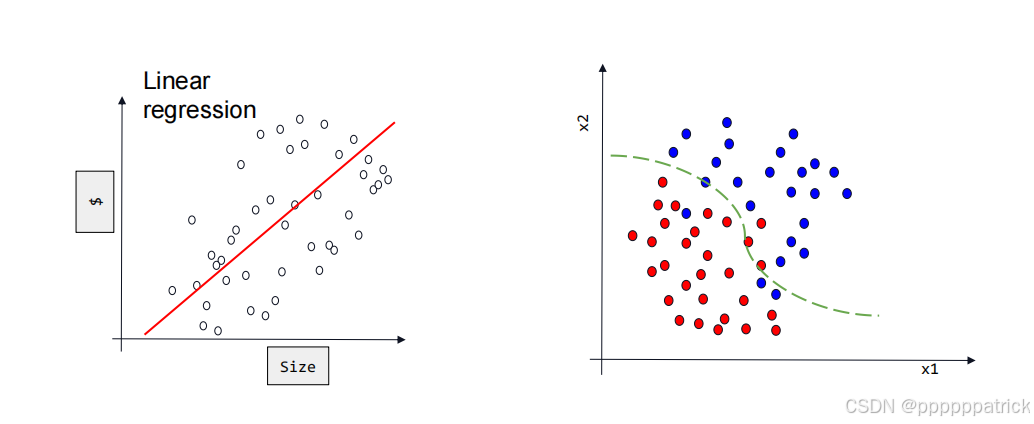
在回归任务中,我们的目标是预测一个连续的数值(比如房价、温度、血糖值),因此全连接层的最终输出维度必然是1,即 nn.Linear(?, 1)——无论前面的隐藏层维度如何,最终只需要输出一个“精准的数值结果”。
但分类任务完全不同:我们的目标是判断输入样本属于“提前定义好的某一类”(比如识别图片是猫、狗、鸟),因此最终的输出维度不能是1,而必须等于类别总数。比如三分类任务(猫/狗/鸟),最终的全连接层需要写成 nn.Linear(?, 3)——输出的3个数值,分别对应样本属于“猫”“狗”“鸟”的“置信度”(可理解为“可能性分数”)。
分类任务的输出解码:从“置信度”到“类别标签”
对于分类任务的输出结果,我们需要一套明确的解码规则:
假设三分类任务的输出为 ŷ = [1.2, 5.8, 0.9](分别对应猫、狗、鸟的置信度),我们会选取其中数值最大的位置,将其标记为1,其余位置标记为0,最终得到 [0, 1, 0]——这个“独热编码”形式的结果,就表示模型预测该样本属于“下标为1的类别(狗)”。
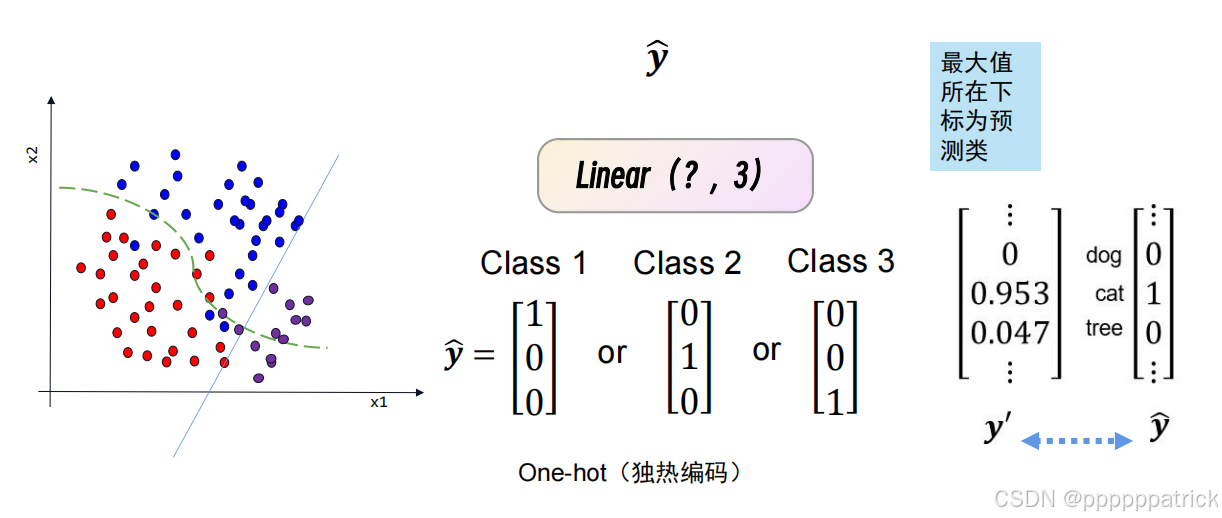
这一逻辑是分类任务的核心:全连接层输出的“多维度置信度”,本质是为每个类别分配一个“可能性分数”,最终通过“取最大值下标”的方式,确定样本的预测类别。
二、图像分类的前提:理解图像的张量表示
要做图像分类,首先要解决“神经网络如何读图片”的问题——图片在计算机中并非“视觉画面”,而是多维张量,我们需要先理解它的维度定义和核心特征。
1. 图像的核心维度:通道×高度×宽度(C×H×W)
一张数字图片的本质是“像素值组成的矩阵/张量”,不同类型的图片对应不同的维度:
- 灰度图:只有1个颜色通道(黑白),维度为
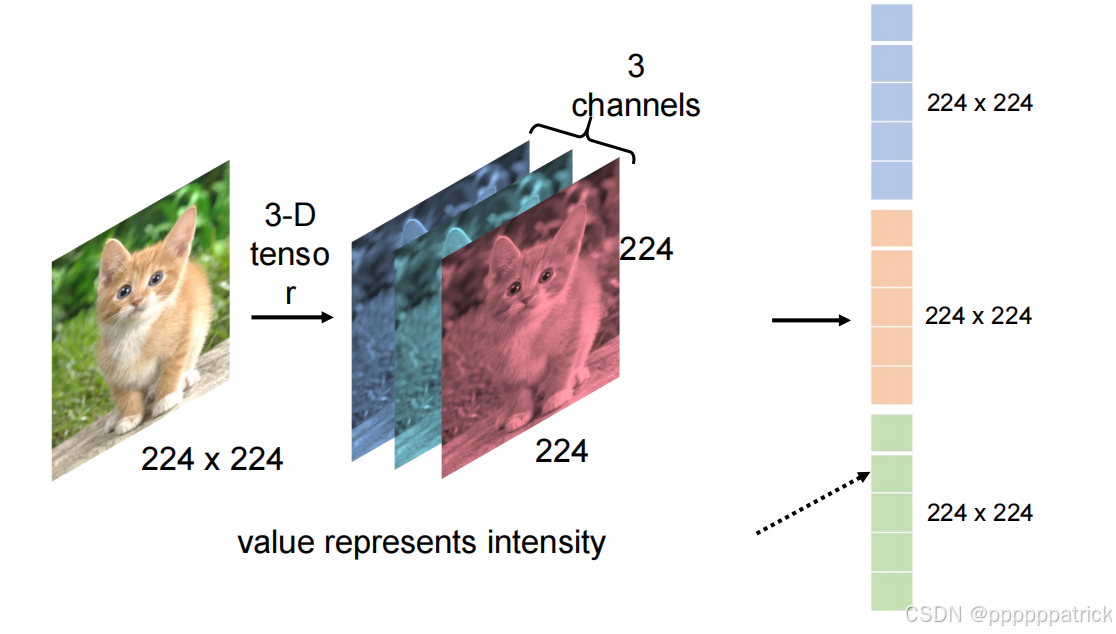
1×H×W(比如1×224×224,表示1个通道、224像素高、224像素宽); - 彩色图:包含RGB三个颜色通道(红/绿/蓝),维度为
3×H×W——这是最常见的图像格式,比如我们日常接触的图片、深度学习数据集(如ImageNet)中的图片,几乎都是3×224×224规格(224×224是行业通用的标准尺寸,兼顾计算效率和识别精度)。
2. 批量图像的张量格式:N×C×H×W
实际训练时,我们不会单张输入图片,而是以“批量”为单位输入,此时图像张量的完整维度为:
(批量数, 通道数, 高度, 宽度),即 N×C×H×W。
比如批量输入16张彩色图片,张量形状为 16×3×224×224——这是PyTorch中图像数据的标准格式,也是卷积神经网络的核心输入形式。
3. 全连接层处理图像的痛点:维度爆炸
既然我们已经掌握了全连接层,为什么不能直接用它处理图像?
以 3×224×224 的彩色图为例:要输入全连接层,需要先将其“展平”为一维向量,维度为 3×224×224 = 150528。若后续接一个隐藏层为1024的全连接层,仅这一层的参数数量就达到 150528×1024 ≈ 1.5亿——参数过多会导致:
- 计算量巨大,训练速度极慢;
- 容易过拟合(模型记住训练数据,却无法泛化到新数据);
- 丢失图像的“空间信息”(比如像素的位置、相邻像素的关联)。
因此,我们需要一种更高效的方式处理图像——卷积神经网络(CNN),而卷积是其核心操作。
为什么全连接层必须展平?
全连接层 nn.Linear(in_features, out_features) 的核心要求是:输入必须是 “二维张量(批量数 × 特征数)”,其中 “特征数” 必须是一维的。
单张 3×224×224 的图片展平后是 1×150528(1 个样本,150528 个特征);
批量 16 张图片展平后是 16×150528(16 个样本,每个样本 150528 个特征)—— 这才符合全连接层的输入要求。
三、卷积的核心概念:从“局部感知”到特征提取
卷积(Convolution)是CNN的灵魂,它的设计灵感来自人类视觉系统的“局部感知”特性:我们看一张图片时,会先关注局部细节(比如眼睛、鼻子),再整合为整体,卷积正是模拟这一过程。
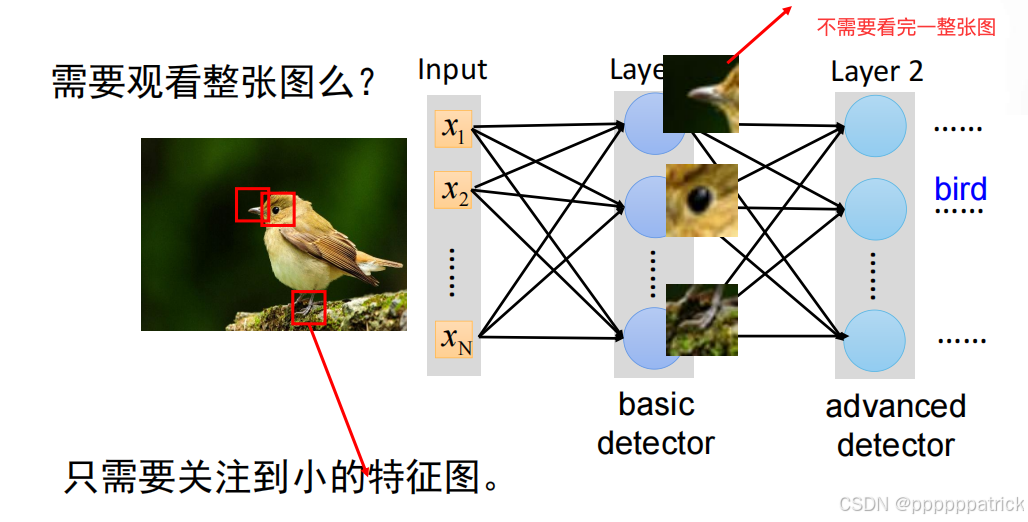
1. 卷积核(Kernel/Filter):图像的“特征探测器”
卷积核是一个小型的权重矩阵(张量),比如最常用的 3×3 卷积核(也有 5×5、1×1 等规格),它的核心作用是“滑动遍历图像,提取局部特征”:
- 对于彩色图(3通道),卷积核的维度为
3×3×3(输入通道数×核高度×核宽度),确保能覆盖所有颜色通道的局部像素; - 卷积核的权重是可训练的参数——训练过程中,卷积核会自动学习“边缘”“纹理”“角点”等基础特征,进而组合成复杂特征(比如“猫的耳朵”“狗的爪子”)。
2. 卷积运算:局部加权求和
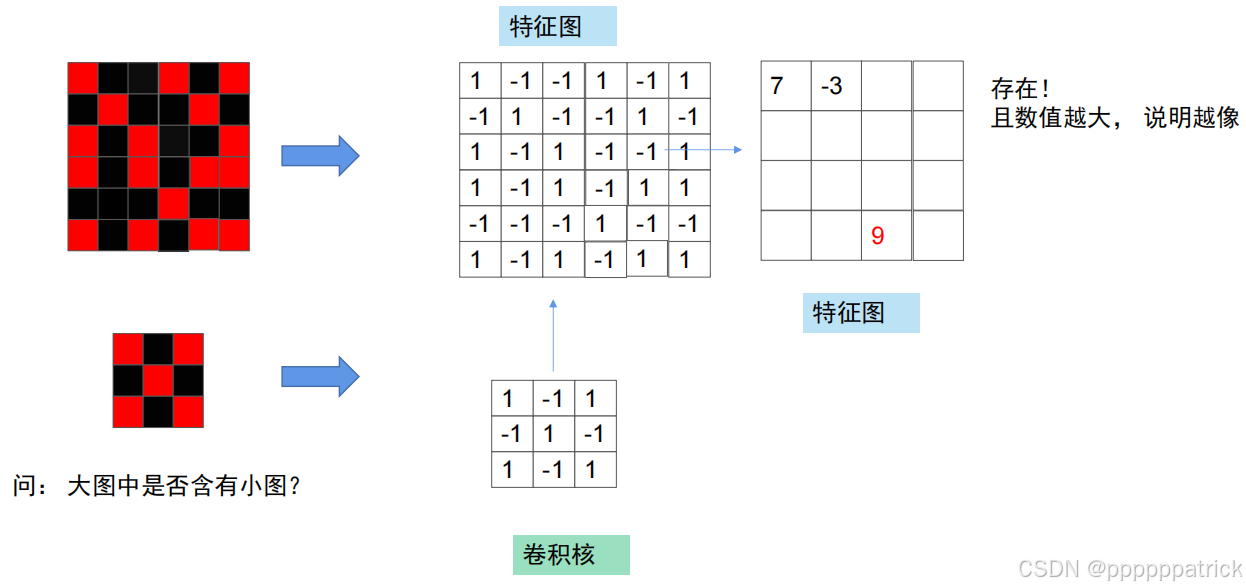
卷积的计算过程可总结为三步:
- 滑动:卷积核以固定步长在图像张量上逐位置滑动,每次覆盖一个“局部区域”;
- 相乘:将卷积核的每个权重与对应位置的图像像素值相乘;
- 求和:将所有相乘结果相加,得到该位置的“特征值”。
最终,所有位置的特征值会组成一张新的“特征图(Feature Map)”——这张特征图就是图像的“局部特征编码”。
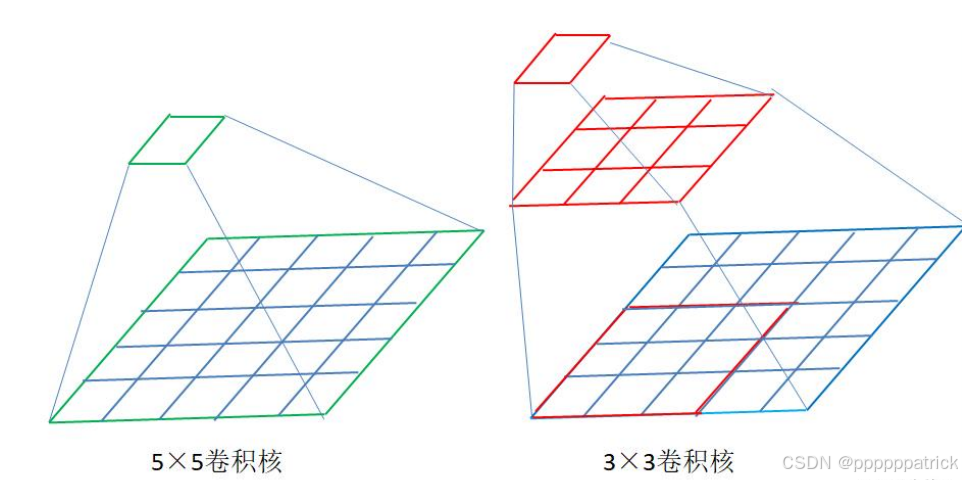
3. 感受野(Receptive Field):特征对应的图像区域
感受野是指“特征图上的一个像素,对应原始图像的区域大小”:
- 比如用
3×3卷积核做一次卷积,特征图的像素感受野是3×3; - 堆叠多层卷积后,感受野会逐层扩大(比如两层
3×3卷积的感受野是5×5)——这意味着深层特征能捕捉图像的“全局信息”,浅层特征捕捉“局部细节”。
四、缩小特征图:步长与池化的核心作用
卷积操作后得到的特征图尺寸可能仍然较大,我们需要通过“缩小特征图”来:
- 降低计算量和参数数量;
- 扩大感受野,提升特征的全局关联性;
- 增强模型的鲁棒性(对位置变化不敏感)。
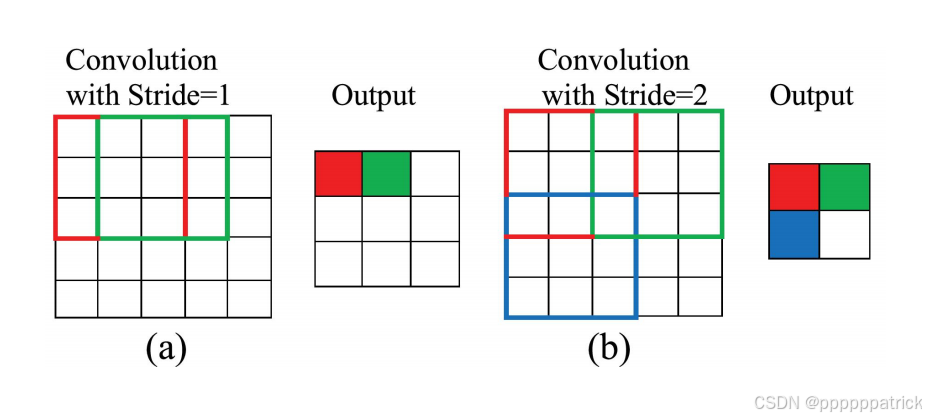
1. 步长(Stride):控制卷积核的滑动距离
步长是卷积核每次滑动的像素数,默认步长为1(逐像素滑动),若将步长设为2:
- 卷积核每次滑动2个像素,特征图的尺寸会直接减半(比如
224×224的特征图,步长2卷积后变为112×112); - 注意:步长过大会导致特征丢失,因此常用步长为1或2。
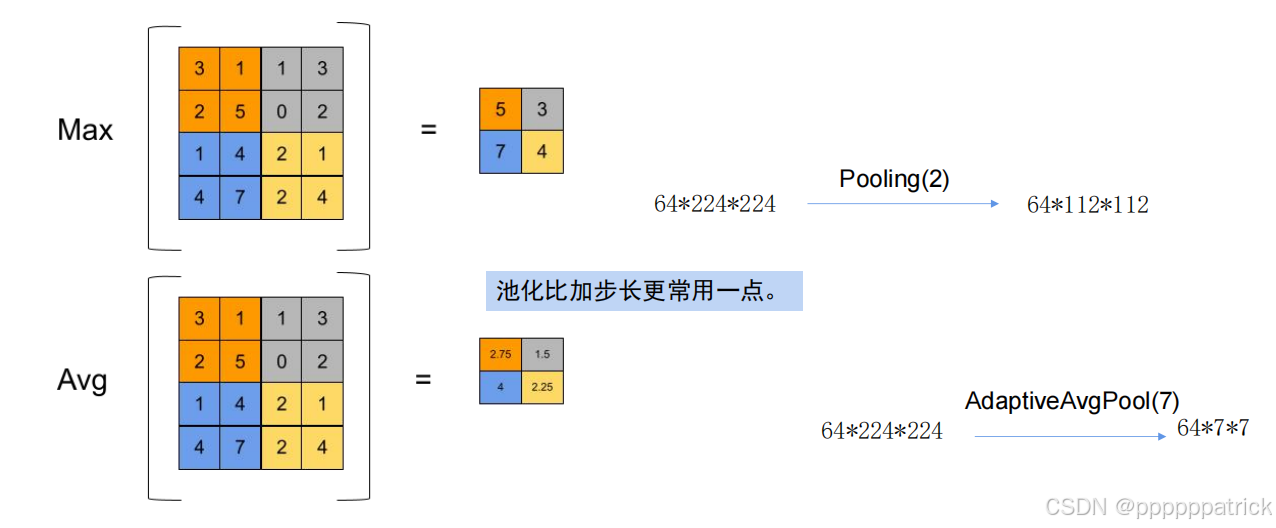
2. 池化(Pooling):无参数的下采样
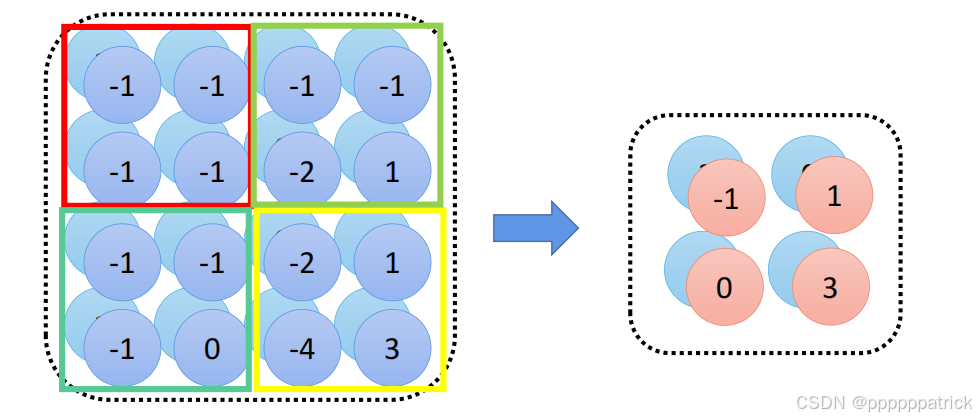
池化是专门用于缩小特征图的操作,它没有可训练的参数,核心是“对局部区域做聚合统计”,常见的池化方式有两种:
- 最大池化(Max Pooling):取局部区域的最大值作为输出——能保留图像的“边缘”“纹理”等关键特征,是最常用的池化方式;
- 平均池化(Average Pooling):取局部区域的平均值作为输出——能保留区域的整体亮度特征,常用于网络深层。
池化的常用规格是 2×2、步长2——比如对 112×112 的特征图做 2×2 最大池化,会得到 56×56 的特征图,尺寸减半且不丢失核心特征。
3. 填充(Padding):保持特征图尺寸
卷积或池化会导致特征图尺寸缩小,若想保持尺寸不变(比如避免边缘特征丢失),可使用“填充”:在图像的边缘填充0值,比如对 224×224 的图像做 3×3 卷积时,填充1圈0值,卷积后尺寸仍为 224×224。
4. 实战计算:卷积输出尺寸与参数量
在实际搭建卷积神经网络时,我们经常需要提前计算卷积后的特征图尺寸,以及卷积层的参数量。这两个问题都有明确的公式可以套用。
1. 输出特征图尺寸计算公式
对于一个标准的卷积层,输出特征图的空间尺寸(高度和宽度)可以通过以下公式计算:
O = I − K + 2 P S + 1 O = \frac{I - K + 2P}{S} + 1 O=SI−K+2P+1
其中:
- O OO:输出特征图的空间尺寸(高度或宽度)
- I II:输入特征图的空间尺寸(高度或宽度)
- K KK:卷积核的空间尺寸(Kernel Size)
- P PP:填充(Padding),在输入边缘填充的0值圈数
- S SS:步长(Stride),卷积核每次滑动的像素数
2. 例题1:计算输出尺寸与参数量
已知条件:
- 输入特征图: 64 × 224 × 224 64 \times 224 \times 22464×224×224(通道数 C i n = 64 C_{in}=64Cin=64,空间尺寸 I = 224 I=224I=224)
- 卷积核: K = 3 × 3 K=3 \times 3K=3×3
- 填充: P = 1 P=1P=1
- 步长: S = 1 S=1S=1
- 卷积核数量(输出通道数): C o u t = 128 C_{out}=128Cout=128
① 计算输出特征图尺寸
将参数代入公式:
O = 224 − 3 + 2 × 1 1 + 1 = 223 1 + 1 = 224 O = \frac{224 - 3 + 2 \times 1}{1} + 1 = \frac{223}{1} + 1 = 224 O=1224−3+2×1+1=1223+1=224
因此,输出特征图的空间尺寸仍为 224 × 224 224 \times 224224×224,通道数为卷积核数量128,最终输出特征图为:
128 × 224 × 224 128 \times 224 \times 224 128×224×224
② 计算这套卷积核的参数量
卷积层的参数量由两部分组成:权重和偏置。
- 权重:每个卷积核的维度为 C i n × K × K C_{in} \times K \times KCin×K×K,总共有 C o u t C_{out}Cout 个卷积核。
权重参数量 = C o u t × C i n × K × K = 128 × 64 × 3 × 3 \text{权重参数量} = C_{out} \times C_{in} \times K \times K = 128 \times 64 \times 3 \times 3 权重参数量=Cout×Cin×K×K=128×64×3×3 - 偏置:每个输出通道对应一个偏置。
偏置参数量 = C o u t = 128 \text{偏置参数量} = C_{out} = 128 偏置参数量=Cout=128
总参数量为:
总参数量 = ( 128 × 64 × 3 × 3 ) + 128 \text{总参数量} = (128 \times 64 \times 3 \times 3) + 128 总参数量=(128×64×3×3)+128
在很多简化计算中,偏置参数数量相对较少,有时会被忽略,只计算权重部分:
3 × 3 × 64 × 128 3 \times 3 \times 64 \times 128 3×3×64×128
3. 例题2:步长过大导致信息丢失
已知条件:
- 输入特征图: 3 × 224 × 224 3 \times 224 \times 2243×224×224( C i n = 3 C_{in}=3Cin=3, I = 224 I=224I=224)
- 卷积核: K = 11 × 11 K=11 \times 11K=11×11
- 填充: P = 2 P=2P=2
- 步长: S = 4 S=4S=4
- 卷积核数量: C o u t = 64 C_{out}=64Cout=64
计算输出尺寸:
O = 224 − 11 + 2 × 2 4 + 1 = 224 − 11 + 4 4 + 1 = 217 4 + 1 = 54.25 + 1 = 55.25 O = \frac{224 - 11 + 2 \times 2}{4} + 1 = \frac{224 - 11 + 4}{4} + 1 = \frac{217}{4} + 1 = 54.25 + 1 = 55.25 O=4224−11+2×2+1=4224−11+4+1=4217+1=54.25+1=55.25
由于特征图的尺寸必须是整数,我们向下取整,得到输出空间尺寸为 55 × 55 55 \times 5555×55。因此,最终输出特征图为:
64 × 55 × 55 64 \times 55 \times 55 64×55×55
注意:
从计算结果 55.25 55.2555.25 可以看出,步长 S = 4 S=4S=4 过大,导致卷积核在滑动时无法覆盖所有像素,这会造成信息丢失,并且引入了额外的计算复杂性。在实际工程中,我们应尽量避免这种情况,确保 ( I − K + 2 P ) (I - K + 2P)(I−K+2P) 能被步长 S SS 整除。
更多练习题请移步本专栏中的另一篇文章:【深度学习基础篇】手算卷积神经网络:13道经典题全解析
Q&A:既然池化能降维,为什么还需要卷积?
很多初学者都会有这样的疑问:既然池化操作可以降低特征图尺寸、减少计算量,那为什么神经网络的核心还是卷积,而不是直接用池化呢?
我们可以从两者的核心使命和分工来理解:
- 卷积(Convolution):负责“提取”特征
卷积层的核心是学习。它通过可训练的卷积核(权重矩阵),在图像上滑动并提取关键信息,比如边缘、纹理、形状,甚至是“猫耳朵”“狗鼻子”等复杂特征。没有卷积,神经网络就无法理解图像的内容,就像人没有眼睛一样。 - 池化(Pooling):负责“压缩”信息
池化层的核心是统计。它没有可学习的参数,只是对卷积提取出的特征图进行“下采样”,比如用2x2的最大池化将特征图尺寸减半。它的作用是降低计算量、扩大感受野,并增强模型的鲁棒性。
一句话总结:卷积是“干活的”,负责从图像中提炼有价值的信息;池化是“减负的”,负责让这些信息更紧凑、更高效地被后续层处理。池化无法替代卷积的根本原因在于,它没有学习能力,永远无法从像素中识别出有意义的模式。
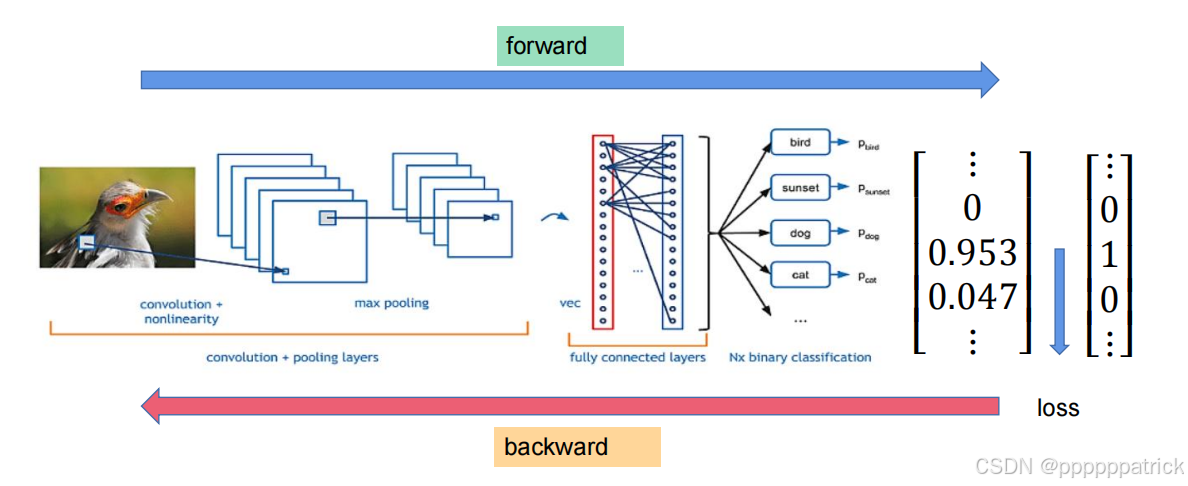
五、手搓一个简单的卷积神经网络:从图像到类别
在前面的章节中,我们已经掌握了卷积、池化、全连接等核心组件。现在,我们将这些组件组合起来,手搓一个完整的卷积神经网络,实现从一张 3×224×224 的图片,到最终输出类别预测的全过程。
5.1 从 3×224×224 到 1024×7×7:特征提取与下采样
我们的目标是将一张高分辨率的图片,逐步转换为一个高通道、低分辨率的特征图 1024×7×7。这个过程的核心是卷积提取特征 + 池化/大步长卷积下采样。
核心思路
- 卷积:增加通道数,提取更丰富的特征。
- 池化/大步长卷积:降低空间尺寸,减少计算量并扩大感受野。
示例网络结构
我们可以通过多次“卷积+池化”的组合,实现维度的转换:
3 × 224 × 224 → Conv(64, 3×3, P=1, S=1) 64 × 224 × 224 → Conv(128, 3×3, P=1, S=2) 128 × 112 × 112 → Conv(256, 3×3, P=1, S=2) 256 × 56 × 56 → Conv(512, 3×3, P=1, S=2) 512 × 28 × 28 → Conv(1024, 3×3, P=1, S=2) 1024 × 14 × 14 → MaxPooling(2×2, S=2) 1024 × 7 × 7 \begin{aligned} &3 \times 224 \times 224 \xrightarrow{\text{Conv(64, 3×3, P=1, S=1)}} 64 \times 224 \times 224 \\ &\xrightarrow{\text{Conv(128, 3×3, P=1, S=2)}} 128 \times 112 \times 112 \\ &\xrightarrow{\text{Conv(256, 3×3, P=1, S=2)}} 256 \times 56 \times 56 \\ &\xrightarrow{\text{Conv(512, 3×3, P=1, S=2)}} 512 \times 28 \times 28 \\ &\xrightarrow{\text{Conv(1024, 3×3, P=1, S=2)}} 1024 \times 14 \times 14 \\ &\xrightarrow{\text{MaxPooling(2×2, S=2)}} 1024 \times 7 \times 7 \end{aligned} 3×224×224Conv(64, 3×3, P=1, S=1) 64×224×224Conv(128, 3×3, P=1, S=2) 128×112×112Conv(256, 3×3, P=1, S=2) 256×56×56Conv(512, 3×3, P=1, S=2) 512×28×28Conv(1024, 3×3, P=1, S=2) 1024×14×14MaxPooling(2×2, S=2) 1024×7×7
- 最少需要多少次卷积?:理论上,最少一次卷积就可以将通道数从3提升到1024,再通过5次池化将尺寸从224降到7。
- 实战中怎么做?:在实战中,我们通常会将卷积和池化交替进行,如上面的示例,这样可以逐步提取从简单到复杂的特征,网络效果更好。
5.2 从 1024×7×7 到类别预测:卷积到全连接的桥梁
当我们得到 1024×7×7 的特征图后,如何将它变成最终的类别预测(如3个类别的置信度)呢?这需要一个从“卷积空间”到“全连接向量”的过渡,主要有以下几种方式:
方式一:直接展平(Flatten)
这是最直接的方法,将三维的特征图“展平”为一维向量,然后输入全连接层。
- 展平:将
1024×7×7的特征图展平为1×50176的一维向量(因为1024 × 7 × 7 = 50176)。 - 全连接:
- 直接映射:
nn.Linear(50176, 3),一步到位输出3个类别的置信度。 - 多层映射:
nn.Linear(50176, 1024) -> nn.Linear(1024, 3),先降维再分类,减少参数量。
- 直接映射:
方式二:全局平均/最大池化(Global Pooling)
为了避免直接展平导致的参数量过大,我们可以先对特征图进行全局池化,将空间维度压缩到1×1。
- 全局最大池化:对
1024×7×7的特征图应用MaxPooling(7×7),得到1024×1×1的向量。 - 全连接:
nn.Linear(1024, 1024) -> nn.Linear(1024, 3)。这种方式大大减少了参数量,同时增强了模型的鲁棒性。
5.3 Softmax:从“置信度”到“概率分布”
全连接层的输出 y 是一组未归一化的置信度,我们需要通过 Softmax 函数将其转换为一个和为1的概率分布,这样每个输出值就代表了模型认为样本属于该类别的概率。
Softmax 公式
y i ′ = e x p ( y i ) ∑ j e x p ( y j ) y'_i = \frac{exp(y_i)}{\sum_j exp(y_j)} yi′=∑jexp(yj)exp(yi)
- 输入:全连接层的输出
y = [11.7, 23, 20](分别对应dog, cat, tree)。 - 输出:
y' = [0, 0.953, 0.047],表示模型认为这张图片是“cat”的概率为95.3%。
注:在PyTorch等框架中,交叉熵损失函数
nn.CrossEntropyLoss()内部已经集成了Softmax操作,我们在模型最后一层通常不需要显式调用Softmax。
5.4 分类任务的损失函数:交叉熵损失(Cross-Entropy Loss)
在回归任务中,我们使用MSE等损失来衡量预测值和真实值的差距。在分类任务中,我们使用交叉熵损失来衡量预测的概率分布和真实分布之间的差距。
多分类交叉熵公式
L = − 1 N ∑ i ∑ c y i c log ( p i c ) L = -\frac{1}{N}\sum_i\sum_c y_{ic} \log(p_{ic}) L=−N1i∑c∑yiclog(pic)
- y i c y_{ic}yic:真实标签,如果样本i属于类别c,则为1,否则为0(独热编码)。
- p i c p_{ic}pic:模型预测样本i属于类别c的概率。
示例计算
假设我们有3个样本,预测和真实标签如下:
| 预测 (猫, 狗, 猪) | 真实 (猫, 狗, 猪) | 是否正确 |
|---|---|---|
| [0.3, 0.3, 0.4] | [0, 0, 1] (猪) | 正确 |
| [0.3, 0.4, 0.3] | [0, 1, 0] (狗) | 正确 |
| [0.1, 0.2, 0.7] | [1, 0, 0] (猫) | 错误 |
计算每个样本的损失:
- 样本1: L 1 = − ( 0 × log 0.3 + 0 × log 0.3 + 1 × log 0.4 ) = 0.91 L_1 = -(0 \times \log0.3 + 0 \times \log0.3 + 1 \times \log0.4) = 0.91L1=−(0×log0.3+0×log0.3+1×log0.4)=0.91
- 样本2: L 2 = − ( 0 × log 0.3 + 1 × log 0.4 + 0 × log 0.3 ) = 0.91 L_2 = -(0 \times \log0.3 + 1 \times \log0.4 + 0 \times \log0.3) = 0.91L2=−(0×log0.3+1×log0.4+0×log0.3)=0.91
- 样本3: L 3 = − ( 1 × log 0.1 + 0 × log 0.2 + 0 × log 0.7 ) = 2.30 L_3 = -(1 \times \log0.1 + 0 \times \log0.2 + 0 \times \log0.7) = 2.30L3=−(1×log0.1+0×log0.2+0×log0.7)=2.30
总损失为所有样本损失的平均值:
L = 0.91 + 0.91 + 2.30 3 = 1.37 L = \frac{0.91 + 0.91 + 2.30}{3} = 1.37 L=30.91+0.91+2.30=1.37
5.5 完整流程总结
一个简单的卷积神经网络,从输入到输出的完整流程可以总结为:
- 输入:一张
3×224×224的彩色图片。 - 特征提取:通过多次卷积和池化,将图片转换为
1024×7×7的高维特征图。 - 过渡到全连接:通过展平或全局池化,将特征图转换为一维向量。
- 分类头:通过全连接层输出类别数维度的置信度。
- 概率转换:(可选,由损失函数内部完成)通过Softmax将置信度转换为概率分布。
- 损失计算:使用交叉熵损失衡量预测和真实标签的差距。
- 反向传播:根据损失更新网络参数,优化模型。
六、总结:从分类任务到卷积的核心逻辑
- 分类任务与回归任务的核心差异在于输出:分类需输出“类别数维度的置信度”,通过“取最大值下标”确定最终类别;
- 图像的张量表示为
C×H×W(批量为N×C×H×W),3×224×224是彩色图的通用规格; - 卷积通过“局部感知”提取图像特征,卷积核是特征探测器,感受野反映特征对应的图像区域;
- 缩小特征图的核心方式是“增大步长”和“池化”,既能降低计算量,又能增强特征的全局关联性。
《【深度学习基础篇04】从回归到分类:图像分类与卷积神经网络入门》 是转载文章,点击查看原文。


