我们每天都在跟数据打交道,但提到数据仓库这个词,大多数人的第一反应还是——听说过,但说不清到底是什么。
有人觉得它就是存数据的地方; 有人觉得它和数据库差不多; 也有不少人以为,只有大厂、只有数据团队才需要数据仓库。
实际上,只要企业存在多个业务系统、多个部门协同、多个分析口径,数据仓库几乎就会成为绕不开的一步。
这篇文章,我们就把数据仓库这件事彻底讲清楚: 数据仓库到底是什么?企业为什么需要它?怎么搭建?又能给企业带来什么价值?
开始之前,我整理了一份数据仓库建设解决方案,里面涵盖了从数据标准、数据仓库到报表体系等关键环节的建设思路,可供参考。需要自取:https://s.fanruan.com/7igmg(复制到浏览器)
一、什么是数据仓库?
先说结论: **数据仓库,是一个面向分析决策的数据管理系统。**它的核心任务不是支撑业务交易,而是把企业分散在各个系统中的数据,经过整合、清洗、统一和沉淀,变成可以用于统计分析、经营管理和决策支持的数据资产。
如果用更容易理解的话来说,数据仓库解决的是这样一件事:
让企业的数据,不只是存在,而是能看、能用、能统一、能分析。
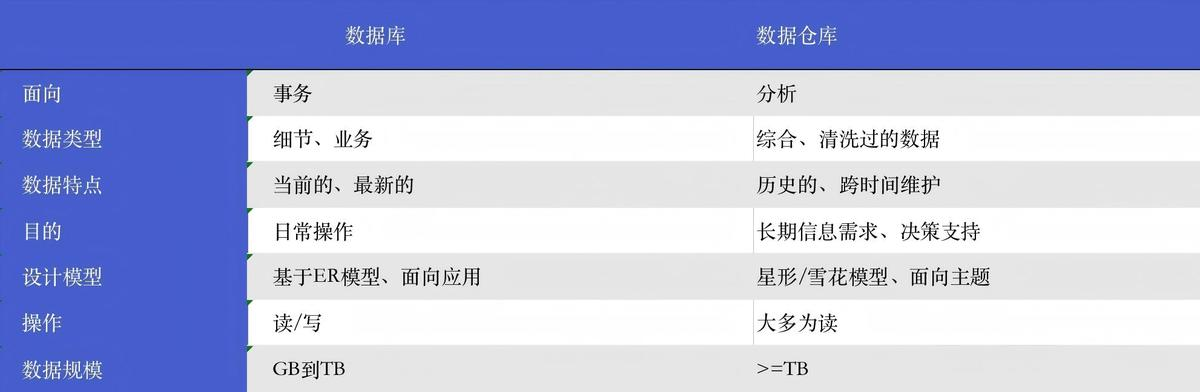
为什么很多人会把数据仓库和数据库混淆?
因为从字面上看,它们都和数据存储有关。但本质上,它们服务的目标不同。
1. 数据库:服务业务运行,目标是做事
数据库主要承载日常业务系统的高并发实时操作,比如订单下单、支付扣款、库存更新。它的设计追求的是事务处理的高效、精准和稳定,核心在于“增删改查”的即时性。你可以把它想象成高速运转的生产线。
2. 数据仓库:服务分析决策,目标是洞察
数据仓库则专注于分析处理。它关心的是诸如本月销售额为何下降、哪类客户贡献了主要利润这类问题。它面向海量历史数据,进行复杂、耗时的大规模查询,但几乎不进行随机修改。它的设计目标是快速、灵活地从海量数据中获取洞察,就像一个庞大的分析研究中心。
3.一个更标准的定义
从行业角度看,一个真正的数据仓库通常具备四个典型特征,这将其与数据库从根本上区分开来:
- 面向主题:围绕销售、客户、产品、财务等主题组织数据
- 集成性:整合来自不同系统、不同格式的数据
- 稳定性:数据一旦进入数据仓库,就会被妥善保存,通常不会频繁被业务改写
- 时变性:不仅看当前状态,还保留历史数据
所以,数据仓库不是简单把数据放一起,而是对数据进行系统化治理之后,形成的企业唯一可信的数据分析基础。
二、企业数据面临什么问题?为什么需要数据仓库?
如果你在企业里真正接触过数据工作,就会发现,很多企业不是没有数据,而是数据很多,但很难用。问题通常不是数据太少,而是数据太散、太乱、太碎。
1.场景一:数据分散在不同系统,根本拼不起来
市场部看投放数据,销售看CRM数据,运营看用户行为数据……每个部门都有自己的系统,也都有自己的报表。
问题在于,这些数据之间并没有天然打通。
比如,一个企业想分析某次市场活动最终带来了多少真实成交和利润贡献,就可能要同时拉取:广告平台投放数据、官网线索数据、CRM跟进数据等等。
只要其中一个环节的字段对不上、时间不统一、客户ID无法映射,分析就很难继续。数据之间缺乏连接的桥梁。
2.场景二:同一个指标,不同部门算出来不一样
这是最消耗团队精力的内耗。例如市场部按留资算和销售部按建档算。会上大家拿出的数字都对,但就是对不上。
这不是技术错误,而是缺少统一的业务定义和计算口径。没有共识,决策就无从谈起。
3.场景三:报表靠手工整理,效率低且容易出错
很多企业的数据分析仍停留在Excel搬运阶段:从多个系统导出,手工清洗合并,用透视表做统计,最后发周报。
这种方式高度依赖个人经验,耗时易错,难以复用和继承,无法支撑业务的敏捷迭代。
4.场景四:只看到结果,看不到原因
很多管理层都会遇到一个问题:报表上能看到发生了什么,但看不到为什么发生。是线索少了?转化率降了?还是某个区域出了问题?
如果没有一套整合后的分析型数据体系,企业只能停留在看到现象,却很难向下追溯原因。
三、如何搭建数据仓库?
很多人一听搭建数据仓库,就觉得这是极其复杂的技术工程。确实涉及技术,但它首先是一个业务驱动、数据支撑的系统工程。有效的建设,绝非简单堆砌技术,而是遵循一套清晰的逻辑。以下是结合了经典方法论与实践的关键步骤:
1.第一步:明确建设目标
先问自己几个问题:我们要解决哪些分析问题?管理层最关心哪些经营指标?目前哪些报表最耗时、最容易出错?哪些系统的数据最需要打通?
如果目标不清晰,仓库很容易做成数据堆积场,投入很大,但业务感知不强。所以,比较合理的做法是从明确的业务主题切入。比如先做销售主题、客户主题、财务主题,优先解决高频分析需求。
2.第二步:梳理数据来源
数据仓库不是凭空产生数据,它的数据来自企业已有系统。常见来源包括有ERP、CRM、OA、财务系统、电商平台、广告投放平台、Excel表格和外部数据源。
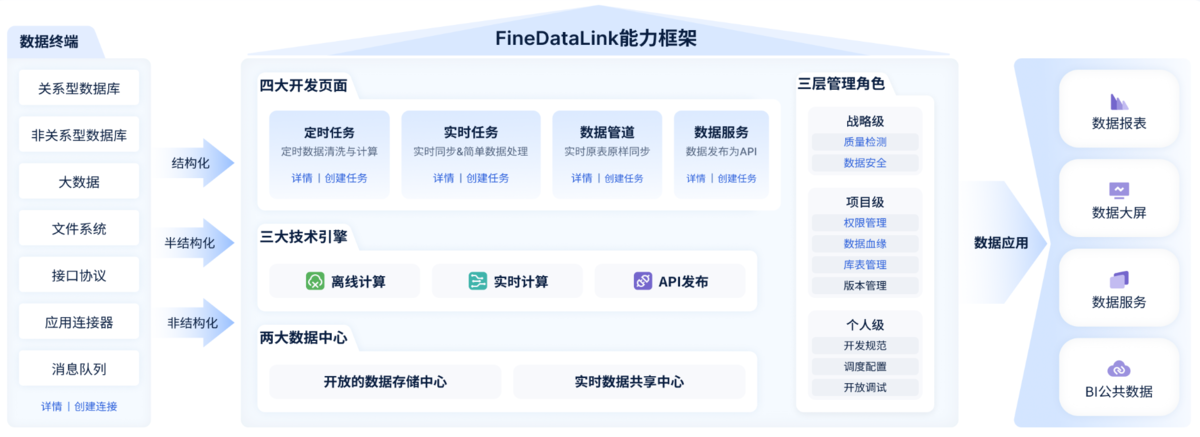
这一步要搞清楚三件事:数据在哪?数据长什么样?数据质量怎么样?一般需要先打通不同渠道、系统的数据,我们团队是直接用数据集成工具FineDataLink来做的,它可以一键打通不同系统、平台的数据,不需要人工再去每个平台手动爬取,又省时又省力。
很多项目推进到一半才发现,核心字段缺失、时间格式混乱、主键对不上。所以前期数据盘点非常关键。
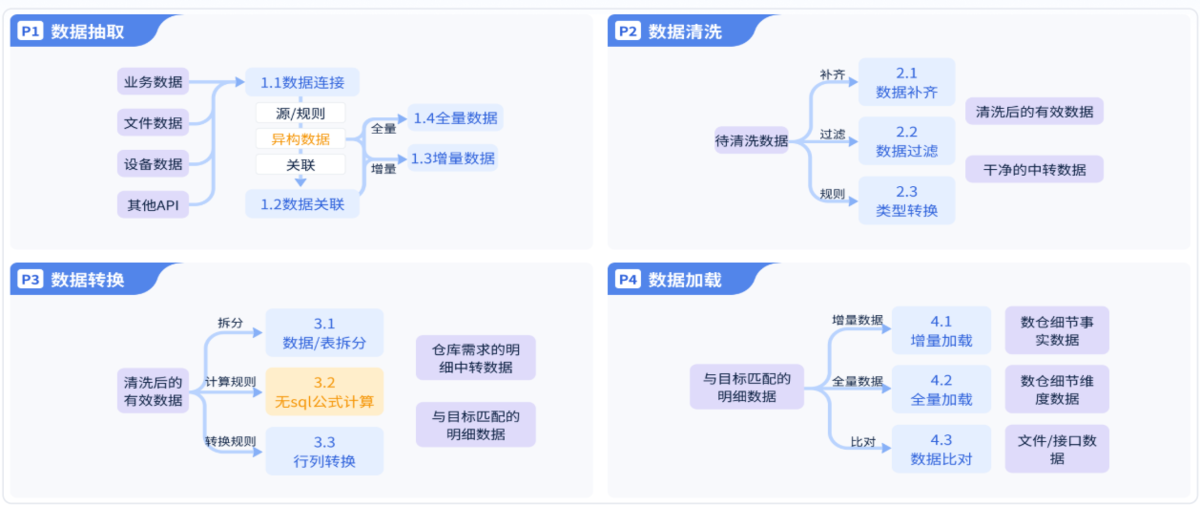
3.第三步:数据集成与清洗
把数据接进来只是开始,更重要的是把数据处理成可分析的状态。
这一步通常会做:去重,补全缺失值,统一字段格式,统一时间口径,建立主数据映射关系,合并多源数据。
比如同一个客户,在不同系统里可能有不同名字、不同编号、不同联系方式。如果不做统一映射,后续客户分析就会严重失真。这也是为什么数据仓库建设离不开数据治理。
因为分析结果的可靠性,取决于底层数据是否规范。
4.第四步:建立分层模型
成熟的数据仓库一般不会把所有原始数据直接扔给业务使用,而是采用分层建设思路。
常见做法包括:
- ODS层:接收原始数据,尽量保留源系统原貌
- DWD层:对明细数据进行清洗、标准化处理
- DWS层:按主题汇总,形成可分析的数据集
- ADS层:直接面向报表和应用输出结果数据
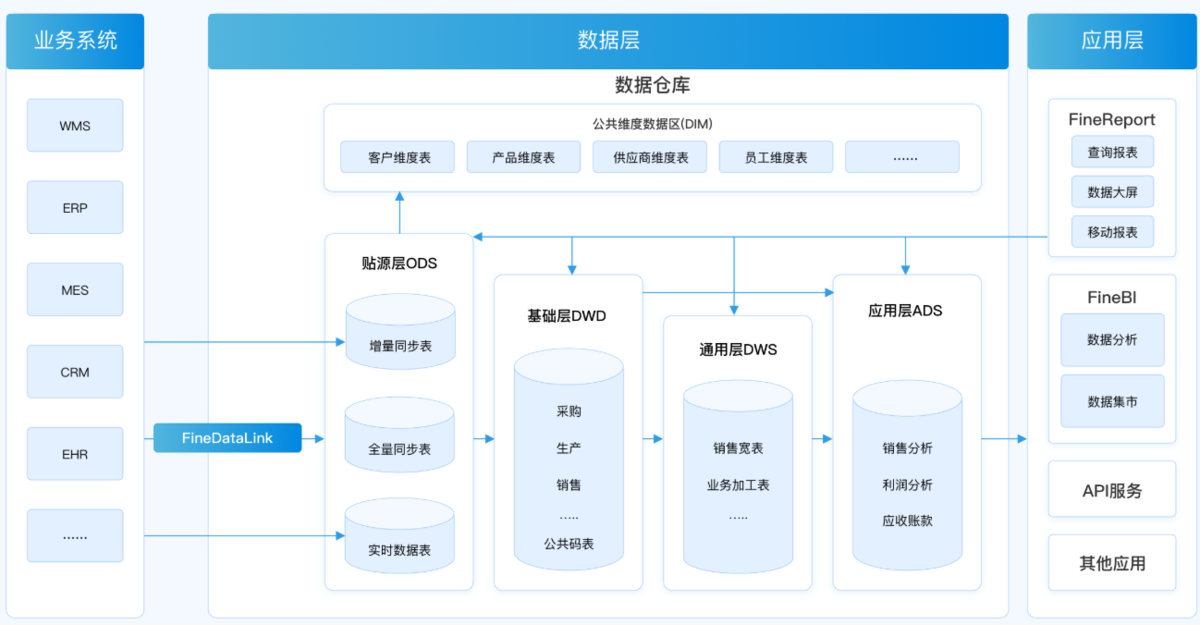
这样做的好处是结构清晰、复用性高,也便于后续扩展。对于小白来说,不用死记这些缩写,但要理解一个原则:
数据仓库不是一步到位生成报表,而是通过分层处理,把原始数据逐步加工成业务可用的数据资产。
5.第五步:开展数据治理
没有治理的数据仓库会迅速腐化。关键是两点:
- 数据质量监控:在关键环节设置校验规则,自动化告警,将问题阻断在进入核心层之前。
- 元数据管理:管理数据的数据,包括业务含义、计算口径,以及至关重要的数据血缘。它能清晰展示数据从何而来、被谁使用,是问题定位和影响评估的地图,是数仓可维护性的基石。
说到数据仓库的治理,大家在实际操作中可以借助 FineDataLink 这种平台,把 ERP、CRM、仓储系统甚至 Excel、接口里的数据都先拉到一块儿来。接进来之后,可以在平台里做去重、补全缺失值、统一时间和编码格式、处理异常值,再按照统一的业务口径把数据规整好,**最后形成一套标准数据,各部门拉出来的报表口径就能对齐,不再各说各的。**工具链接我放在这里,有需要可以点击体验:https://s.fanruan.com/tx4dw(复制到浏览器)
6.第六步:连接BI工具、形成分析应用
数据仓库建好后,最终还是要服务业务。最常见的落地方式,就是结合BI工具,把仓库中的数据转化为可视化看板、经营报表、专题分析和预警应用。
这也是很多企业最能直接感受到价值的环节:
- 管理层可以随时看经营总览
- 业务部门可以自助取数分析
- 数据团队减少重复做报表
- 关键指标可以自动监控
四、写在最后:数据仓库是企业数据化经营的必经一步
最后想说一个我自己的观察:很多企业一开始并不是不重视数据,而是低估了把数据真正用起来这件事的难度。 因为只要业务系统一多、数据来源一杂、分析需求一深,原来依赖人工拉表和部门协作的方式,很快就会遇到瓶颈。
这时候,数据仓库的价值就体现出来了。它不是一个抽象的技术名词,也不是为了显得企业很数字化才去建设。
它真正解决的是企业经营里最现实的问题:数据不统一、分析不高效、决策不及时。
所以,如果要用一句话来总结什么是数据仓库,我会这样说:
数据仓库,就是企业把分散的数据整理成统一、可信、可分析的数据资产,并持续服务经营决策的一套基础设施。
当企业开始重视数据协同、指标统一和经营洞察时,数据仓库往往就不再是要不要做的问题,而是什么时候开始做、怎么更高效地做的问题。
《数据仓库是什么?怎么搭建数据仓库?》 是转载文章,点击查看原文。