想象一个巨大的文档分类任务,一个人处理要一个月。MapReduce 把这个任务分配给一百个人,每人处理一小部分,最后把结果汇总,半小时就完成了!这就是 MapReduce 的威力!
📑 目录
- MapReduce 概述
- 名词解释(命令与术语)
- Map 阶段详解
- Shuffle 阶段详解
- Reduce 阶段详解
- 完整 WordCount 示例
- 高级特性
- MapReduce 与 YARN
- 监控与调试
- 性能优化
- 总结
- 官方文档与参考
🎯 MapReduce 概述
什么是 MapReduce?
MapReduce 是一种分布式计算框架,用于处理和生成大数据集。它将复杂的并行计算过程抽象为两个阶段:Map(映射)和 Reduce(归约)。
官方定义简述(来源:Apache Hadoop MapReduce):MapReduce 是建立在 YARN 之上的并行处理大数据集的编程模型。用户实现 Mapper 和 Reducer,框架负责把输入切分为分片、调度 Task、处理 Shuffle 与容错,适合批处理场景。
为什么需要 MapReduce?
想象一个图书馆要统计所有书中的单词出现次数:
- 单机处理 = 一个图书管理员一本本翻,可能要几个月
- MapReduce = 一百个管理员每人负责几本书,最后汇总结果,几天就完成
📂 大数据集
📤 自动分发
🗺️ Map 并行处理
🔀 Shuffle 数据交换
📊 Reduce 汇总结果
📁 最终输出
MapReduce 的核心思想
| 概念 | 说明 | 生活类比 |
|---|---|---|
| 分而治之 | 大任务拆成小任务 | 公司分成部门处理不同业务 |
| 移动计算而非数据 | 计算靠近数据 | 去仓库处理货物,而非把货物搬到办公室 |
| 容错性 | 任务失败自动重试 | 员工请假有人顶替 |
MapReduce vs 传统计算
MapReduce
📂 读取数据
🗺️ Map 并行
🔀 Shuffle 排序
📊 Reduce 汇总
📁 输出结果
传统计算
📂 读取数据
🖥️ 单机处理
📁 输出结果
| 特性 | 传统计算 | MapReduce |
|---|---|---|
| 数据规模 | GB 级别 | TB/PB 级别 |
| 计算方式 | 单机串行 | 分布式并行 |
| 容错能力 | 无 | 自动重试 |
| 适用场景 | 小数据 | 大数据 |
| 硬件要求 | 高性能服务器 | 普通机器集群 |
Map 与 Reduce 对比(相近概念辨析)
| 维度 | Map | Reduce |
|---|---|---|
| 输入 | 一个 InputSplit,一条条 (key, value) | 同一 key 的所有 value 的迭代器 |
| 输出 | 若干 (key, value),可多可少 | 通常每个 key 输出一条(或几条) |
| 并行度 | 由分片数决定,通常很多 | 由 setNumReduceTasks 决定 |
| 是否必须 | 必须有 | 可以设为 0(仅 Map 作业) |
| 生活类比 | 各部门各自统计原始数据 | 总部把各部门结果按类别汇总成总表 |
📖 名词解释(命令与术语)
以下对文档中出现的命令、概念、配置项做简要解释,并配上生活例子与「为什么」,便于记忆与理解。
常用命令
| 命令/名称 | 含义 | 说明 | 生活例子 | 为什么? |
|---|---|---|---|---|
| hadoop jar | 提交 MapReduce 作业 | hadoop jar <jar> <MainClass> <input> <output>,把打包好的 Job 提交到集群运行 | 像「把任务单和工具箱交给工地负责人」:jar 是工具箱,MainClass 是任务单上的负责人 | 为什么用 jar?因为集群各节点要能加载同一份代码,jar 便于分发和指定入口类 |
| mapred job -list | 列出作业 | 查看当前或历史 MapReduce 作业列表 | 像「看工地任务看板」:哪些任务在跑、哪些已完成 | 为什么需要?方便排查卡住的任务、查作业 ID 看日志 |
| mapred job -status | 查看作业状态 | 根据 job_id 查看该作业的进度、计数器、失败信息 | 像「查某一份任务单的当前进度」 | 为什么重要?失败时要看在 Map 还是 Reduce、哪个 Task 出错 |
| mapred job -kill | 杀死作业 | 终止正在运行的作业 | 像「叫停一个任务」:发现跑错或不需要时及时停 | 为什么有时要 kill?错误参数、重复提交、或为腾出资源给更重要的任务 |
| hdfs dfs -put | 上传文件到 HDFS | 将本地文件或目录放入 HDFS 路径 | 像「把材料搬进仓库」:MapReduce 读的是 HDFS 上的数据 | 为什么数据要在 HDFS?计算靠近数据、多副本可靠、与 MapReduce 同生态 |
| hdfs dfs -cat | 查看 HDFS 文件内容 | 输出 HDFS 上文件内容到标准输出 | 像「打开仓库里某箱货看一眼」 | 为什么用 cat?快速看输出目录里的 part-r-00000 等结果文件 |
| FileInputFormat.addInputPath | 设置作业输入路径 | 指定 Job 从哪些 HDFS 路径读入数据,可多次调用或传目录 | 像「指定从哪几个仓库取料」 | 为什么可以传目录?框架会递归列出目录下文件并切成 InputSplit,便于多文件一批处理 |
核心概念
| 名词 | 含义 | 生活例子 | 为什么? |
|---|---|---|---|
| InputSplit | 输入分片,逻辑上的一段输入,对应一个 Map Task | 像「把一本大书拆成若干章,每人负责一章」 | 为什么按块(如 128MB)切?和 HDFS 块对齐便于数据本地化,且单 Task 不宜过大否则失败成本高 |
| RecordReader | 记录读取器,把 InputSplit 读成一条条 (key, value) | 像「章节负责人按行/按条读出内容」 | 为什么需要?Map 只认识键值对,不同文件格式(文本、SequenceFile)用不同 RecordReader 解析 |
| Partitioner | 分区器,决定每条 (k,v) 去哪个 Reduce | 像「按姓氏首字母分到不同收银台结账」 | 为什么默认用 hash?保证同一 key 一定进同一 Reduce,且尽量均衡;自定义可解决数据倾斜 |
| Spill(溢写) | 内存缓冲区满时把数据排序后写到本地磁盘 | 像「桌上摆满了就先整理成几摞放进抽屉,桌上继续接新单」 | 为什么不全放内存?数据可能远超内存,溢写避免 OOM,且排序后便于后续 Merge 与 Reduce 拉取 |
| Shuffle | Map 输出到 Reduce 输入之间的数据搬运、排序、分组 | 像「各部门交表后,总部按姓氏排序、装订成册再分给不同汇总员」 | 为什么叫 Shuffle?像洗牌一样把数据重新打乱再按 key 归拢,是 MR 里最耗时的阶段之一 |
| Combiner | Map 端局部聚合,在 Shuffle 前先做一次「小 Reduce」 | 像「各部门先把自己部门的数加总,再交表,而不是交一摞原始单子」 | 为什么能减少网络?同一 key 的多个 value 在 Map 端先合并,传的数据量变小;但必须满足结合律(如求和) |
| Container | YARN 的资源容器,封装 CPU+内存,跑一个 Task | 像「一个工位:一张桌子+一台电脑」 | 为什么需要?YARN 按 Container 分配资源,Map/Reduce Task 都在 Container 里跑,便于隔离与调度 |
| ApplicationMaster (AM) | 每个 Job 一个,向 RM 要资源、管理 Task 生命周期 | 像「项目经理:向公司要人、派活、盯进度」 | 为什么每个 Job 一个?不同 Job 的 Map/Reduce 数量、依赖不同,AM 负责本 Job 的调度与容错 |
配置参数(为什么这样设?)
| 参数 | 典型含义 | 为什么? |
|---|---|---|
| mapreduce.job.reduces / setNumReduceTasks | Reduce 任务数 | 太少则单 Reduce 成瓶颈;太多则小文件多、启动开销大;0 表示只有 Map 无 Reduce |
| io.sort.mb(旧)/ mapreduce.task.io.sort.mb | Map 端环形缓冲区大小 | 越大溢写次数越少,但占内存;默认约 100MB 是经验折中 |
| mapreduce.map.output.compress | 是否压缩 Map 输出 | 压缩减少 Shuffle 网络和磁盘 IO,用少量 CPU 换大量 IO,通常值得开 |
| mapreduce.map.speculative | Map 是否推测执行 | 慢 Task 会拖慢整个 Job;再起一份备份谁先完成用谁,可防「拖后腿」节点 |
🗺️ Map 阶段详解
Map 的作用
Map 阶段负责将输入数据拆分成独立的键值对,并进行初步处理。
生活类比:
- 公司年终报告
- Map = 各部门各自统计自己的数据
- Reduce = 汇总各部门数据形成总报告
Map 工作流程
📂 输入数据
InputSplit
📖 RecordReader
读取记录
✏️ Map 函数
用户自定义
🔀 Partition
分区
📋 Sort
排序
💾 Spill
溢写磁盘
📦 Merge
合并文件
Map 阶段详细说明
1. InputSplit(输入分片)
📂 大文件 1TB
📄 分片1: 128MB
📄 分片2: 128MB
📄 分片3: 128MB
📄 ...共 8000+ 分片
InputSplit 是 MapReduce 对输入数据的逻辑划分,每个分片由一个 Map Task 处理。
为什么默认 128MB? 与 HDFS 块大小(默认 128MB)对齐,这样多数分片可以数据本地化(Task 和块在同一节点),减少网络拉取。分片太大则单 Task 耗时长、失败重试成本高;太小则 Task 数过多、调度与启动开销大。
| 属性 | 说明 | 默认值 |
|---|---|---|
| 分片大小 | 每个 Split 的数据量 | 128MB (HDFS 块大小) |
| 分片数量 = 总数据量 / 分片大小 | 决定 Map 任务数 |
2. RecordReader(记录读取器)
将输入分片转换为键值对记录。为什么键是偏移量(如 LongWritable)? 文本按行切时,框架需要唯一标识每一行,用「文件内字节偏移」可以保证不重复且便于定位;若不需要 key,Map 里可以忽略不用。
1// TextInputFormat 示例 2// 输入文件: 3// Hello World 4// Hello Hadoop 5 6// 输出键值对: 7// (0, "Hello World") <- 键是行首偏移量,值是行内容 8// (12, "Hello Hadoop") <- 键是第二行的偏移量 9
3. Map 函数
用户自定义的核心处理逻辑。
1// WordCount 的 Map 函数 2public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { 3 4 private final static IntWritable one = new IntWritable(1); 5 private Text word = new Text(); 6 7 @Override 8 protected void map(LongWritable key, Text value, Context context) 9 throws IOException, InterruptedException { 10 11 // 输入:行偏移量, 行内容 12 // "Hello World Hello" 13 14 String line = value.toString(); 15 String[] words = line.split("\\s+"); 16 17 for (String w : words) { 18 word.set(w); 19 // 输出:(Hello, 1), (World, 1), (Hello, 1) 20 context.write(word, one); 21 } 22 } 23} 24
Map 输出示例:
1输入: "Hello World Hello" 2输出: (Hello, 1) 3 (World, 1) 4 (Hello, 1) 5
4. Partition(分区)
决定每个键值对发送到哪个 Reducer。为什么必须按 key 分区? 因为 Reduce 是按 key 分组汇总的,同一 key 的所有 value 必须送到同一个 Reducer,否则结果会错(例如 WordCount 里 “Hello” 被拆到两个 Reduce 就得不到正确总数)。
1// 默认的 HashPartitioner 2public class HashPartitioner<K, V> extends Partitioner<K, V> { 3 4 @Override 5 public int getPartition(K key, V value, int numReduceTasks) { 6 // 根据键的哈希值决定分区 7 return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks; 8 } 9} 10
5. Sort(排序)
在每个分区内按键排序。
1排序前: 2(Apple, 1) 3(Banana, 1) 4(Apple, 1) 5(Cherry, 1) 6(Banana, 1) 7 8排序后: 9(Apple, 1) 10(Apple, 1) 11(Banana, 1) 12(Banana, 1) 13(Cherry, 1) 14
6. Spill(溢写)
当内存缓冲区满时(默认 100MB),数据溢写到磁盘。为什么是 80% 就溢写? 留出 20% 空间给新来的数据,避免写盘期间缓冲区被撑爆;溢写与 Map 输出可并行,提高吞吐。
达到 80%
后台线程
🔄 环形缓冲区
100MB
💾 溢写到磁盘
📋 排序+分区
📁 生成溢写文件
7. Merge(合并)
将多个溢写文件合并成一个大文件。为什么先 Spill 再 Merge? 因为 Map 输出可能很大,无法一次性在内存排序;先按 80% 阈值一段段排序后写盘,最后多路归并成一个大有序文件,Reduce 拉取时只需顺序读。
🔀 Shuffle 阶段详解
什么是 Shuffle?
Shuffle 是 MapReduce 的核心,负责将 Map 的输出传输到 Reduce。它是 Map 和 Reduce 之间的"数据搬运工"。
为什么叫 Shuffle?
就像洗牌一样,把数据重新排列组合。
Shuffle 工作流程
Reduce端
数据传输
Map端
🗺️ Map 输出
💾 内存缓冲区
🔀 分区排序
💾 溢写磁盘
📦 合并文件
📤 HTTP 拉取
🌐 网络传输
💾 内存缓冲
📋 归并排序
📊 Reduce 输入
Map 端 Shuffle
1// Map 端 Shuffle 配置优化 2// 1. 环形缓冲区大小(默认 100MB) 3conf.set("io.sort.mb", "200"); 4 5// 2. 溢写阈值(默认 80%) 6conf.set("io.sort.record.percent", "0.9"); 7 8// 3. 溢写工作线程数 9conf.set("io.sort.factor", "10"); 10 11// 4. 压缩 Map 输出 12conf.set("mapreduce.map.output.compress", "true"); 13conf.set("mapreduce.map.output.compress.codec", 14 "org.apache.hadoop.io.compress.SnappyCodec"); 15
Reduce 端 Shuffle
为什么 Reduce 要主动拉取(Pull)而不是 Map 主动推(Push)? Pull 模式下 Reduce 按自己进度拉取,避免 Map 输出爆满时拖垮 Map 端;且多个 Reduce 可并行从多个 Map 拉,负载更均衡。
🗺️ Map Task 3 🗺️ Map Task 2 🗺️ Map Task 1 📊 Reducer 🗺️ Map Task 3 🗺️ Map Task 2 🗺️ Map Task 1 📊 Reducer 启动拷贝线程 启动拷贝线程 启动拷贝线程 输出文件 1 输出文件 2 输出文件 3 💾 磁盘合并 📋 归并排序 ✏️ 送给 Reduce 函数
Shuffle 性能优化
| 优化点 | 配置参数 | 说明 |
|---|---|---|
| 压缩 | mapreduce.map.output.compress | 减少 IO 和网络传输 |
| 缓冲区大小 | mapreduce.task.io.sort.mb | 增大减少溢写次数 |
| 并行拷贝 | mapreduce.reduce.shuffle.parallelcopies | 增加拷贝线程 |
| 预取 | mapreduce.reduce.shuffle.input.buffer.percent | 提前拉取数据 |
📊 Reduce 阶段详解
Reduce 的作用
Reduce 阶段负责接收 Map 的输出,按键分组,进行最终汇总计算。
生活类比:
- 各省(Map)统计完人口后
- 中央统计局(Reduce)汇总成全国总人口
Reduce 工作流程
🔀 Shuffle 输出
已排序的键值对
📂 Grouping
按键分组
✏️ Reduce 函数
用户自定义
📁 OutputFormat
写入文件系统
Reduce 函数示例
1// WordCount 的 Reduce 函数 2public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> { 3 4 private IntWritable result = new IntWritable(); 5 6 @Override 7 protected void reduce(Text key, Iterable<IntWritable> values, Context context) 8 throws IOException, InterruptedException { 9 10 // 输入:(Hello, [1, 1, 1, 1, ...]) 11 12 int sum = 0; 13 for (IntWritable val : values) { 14 sum += val.get(); 15 } 16 17 result.set(sum); 18 // 输出:(Hello, 1000) 19 context.write(key, result); 20 } 21} 22
Reduce 输入结构
1输入格式:键 + 值迭代器 2 3示例: 4键:"Hello" 5值:[1, 1, 1, 1, 1, 1, 1, 1, 1, 1] (10个1) 6 7处理逻辑: 8遍历所有值,求和 9输出:(Hello, 10) 10
Reduce 任务数量
1# 设置 Reduce 任务数量 2conf.setNumReduceTasks(3); 3 4# 如何确定 Reduce 数量? 5# - 太少:单个 Reduce 负担重,成为瓶颈 6# - 太多:小文件增多,集群开销大 7# - 经验公式:0.95 * 集群节点数 * 每节点任务槽位数 8
为什么 0 个 Reduce 也可以? 有些作业只需要做 Map(如过滤、格式转换),不需要按 key 汇总,设 setNumReduceTasks(0) 即可,输出直接写 HDFS,文件数为 Map 数。
| 数量 | 适用场景 | 注意事项 |
|---|---|---|
| 0 个 | 只需 Map,不需要汇总 | 只有 Map,没有 Reduce |
| 1 个 | 小数据集 | 所有数据到一个 Reduce |
| 多个 | 大数据集 | 需要合理分区 |
🚀 完整 WordCount 示例
完整代码
1import java.io.IOException; 2import org.apache.hadoop.conf.Configuration; 3import org.apache.hadoop.fs.Path; 4import org.apache.hadoop.io.IntWritable; 5import org.apache.hadoop.io.LongWritable; 6import org.apache.hadoop.io.Text; 7import org.apache.hadoop.mapreduce.Job; 8import org.apache.hadoop.mapreduce.Mapper; 9import org.apache.hadoop.mapreduce.Reducer; 10import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 11import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 12 13public class WordCount { 14 15 // Mapper 类 16 public static class TokenizerMapper 17 extends Mapper<LongWritable, Text, Text, IntWritable>{ 18 19 private final static IntWritable one = new IntWritable(1); 20 private Text word = new Text(); 21 22 @Override 23 public void map(LongWritable key, Text value, Context context) 24 throws IOException, InterruptedException { 25 26 // 输入:(行偏移量, 行内容) 27 String line = value.toString(); 28 String[] tokens = line.split("\\s+"); 29 30 for (String token : tokens) { 31 if (token.length() > 0) { 32 word.set(token); 33 context.write(word, one); 34 } 35 } 36 } 37 } 38 39 // Reducer 类 40 public static class IntSumReducer 41 extends Reducer<Text,IntWritable,Text,IntWritable> { 42 43 private IntWritable result = new IntWritable(); 44 45 @Override 46 public void reduce(Text key, Iterable<IntWritable> values, 47 Context context) throws IOException, InterruptedException { 48 49 int sum = 0; 50 for (IntWritable val : values) { 51 sum += val.get(); 52 } 53 result.set(sum); 54 context.write(key, result); 55 } 56 } 57 58 // Driver 类 59 public static void main(String[] args) throws Exception { 60 61 // 创建配置 62 Configuration conf = new Configuration(); 63 64 // 创建 Job 65 Job job = Job.getInstance(conf, "word count"); 66 job.setJarByClass(WordCount.class); 67 68 // 设置 Mapper 和 Reducer 69 job.setMapperClass(TokenizerMapper.class); 70 job.setReducerClass(IntSumReducer.class); 71 72 // 设置输出类型 73 job.setOutputKeyClass(Text.class); 74 job.setOutputValueClass(IntWritable.class); 75 76 // 设置输入输出路径 77 FileInputFormat.addInputPath(job, new Path(args[0])); 78 FileOutputFormat.setOutputPath(job, new Path(args[1])); 79 80 // 等待任务完成 81 System.exit(job.waitForCompletion(true) ? 0 : 1); 82 } 83} 84
编译和运行
1# 1. 编译 2hadoop com.sun.tools.javac.Main WordCount.java 3jar cf wc.jar WordCount*.class 4 5# 2. 创建测试数据 6hdfs dfs -mkdir /user/input 7echo "Hello World Hello Hadoop" > /tmp/test.txt 8hdfs dfs -put /tmp/test.txt /user/input/ 9 10# 3. 运行 11hadoop jar wc.jar WordCount /user/input /user/output 12 13# 4. 查看结果 14hdfs dfs -cat /user/output/part-r-00000 15# 输出: 16# Hadoop 1 17# Hello 2 18# World 1 19
🔧 高级特性
Combiner(规约器)
什么是 Combiner?
Combiner 是 Map 端的"小 Reduce",在 Shuffle 前先进行局部汇总。
是
否
🗺️ Map 输出
有 Combiner?
📊 局部汇总
减少网络传输
🔀 直接 Shuffle
生活类比:
- 没有 Combiner = 每个人把自己统计的纸条全部送到总部
- 有 Combiner = 每个人先汇总自己的结果,只送汇总后的数据
1// 设置 Combiner(与 Reducer 相同) 2job.setCombinerClass(IntSumReducer.class); 3 4// WordCount 示例: 5// Map 输出:(Hello, 1), (Hello, 1), (Hello, 1), (Hello, 1), (Hello, 1) 6// 有 Combiner:(Hello, 5) <- 只传输 5 而不是 5 个 1 7// 没有 Combiner:传输 (Hello, 1) 五次 8
| 场景 | 可以用 Combiner | 不能用 Combiner |
|---|---|---|
| 求和/计数 | ✅ 可交换结合 | - |
| 最大/最小值 | ✅ 可交换结合 | - |
| 平均值 | ❌ 不能直接用 | 需要特殊处理 |
| 去重 | ❌ 不能直接用 | 会丢失数据 |
为什么平均值不能直接用 Combiner? 因为 (sum1/count1 + sum2/count2)/2 ≠ (sum1+sum2)/(count1+count2) 的等价形式不能简单「先平均再平均」;若用 Combiner,应输出 (局部 sum, 局部 count),在 Reduce 里再总 sum / 总 count。
数据本地化(Data Locality)
为什么需要数据本地化?
网络传输比磁盘读取慢很多,让计算靠近数据可以显著提升性能。
理想
次优
最差
📂 数据在 Node A
任务调度
✅ Task 在 Node A 执行
DATA_LOCAL
🟡 Task 在同机架执行
RACK_LOCAL
❌ Task 在远程执行
OFF_SWITCH
| 本地化级别 | 说明 | 性能 |
|---|---|---|
| NODE_LOCAL | 任务和数据在同一节点 | 最快 |
| RACK_LOCAL | 任务和数据在同一机架 | 较快 |
| OFF_SWITCH | 跨机架执行 | 较慢 |
推测执行(Speculative Execution)
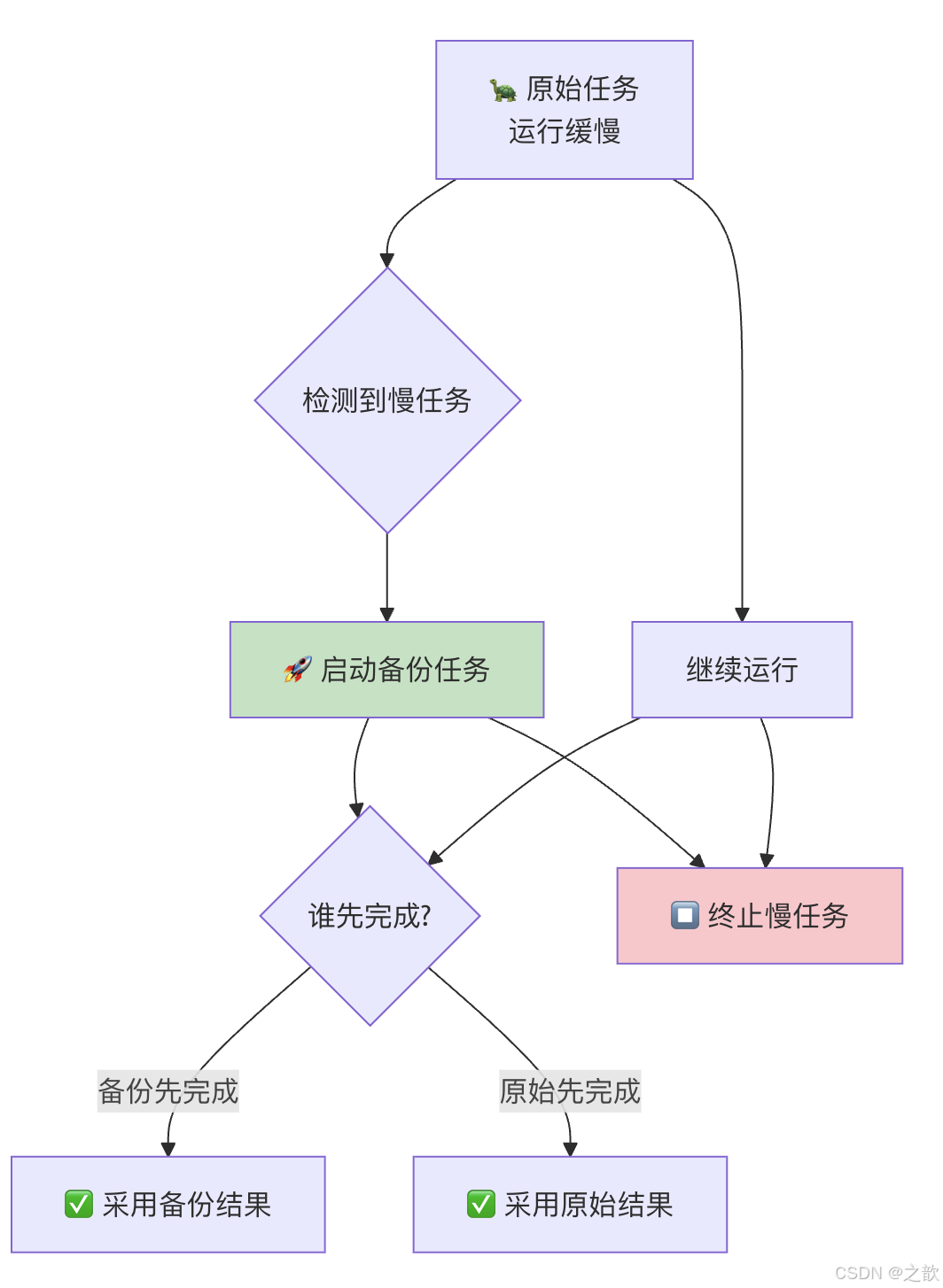
什么是推测执行?
当一个任务运行明显慢于其他任务时,Hadoop 会在另一个节点上启动一个相同任务的备份,哪个先完成就采用哪个的结果。
1# 启用推测执行 2<property> 3 <name>mapreduce.map.speculative</name> 4 <value>true</value> 5</property> 6 7<property> 8 <name>mapreduce.reduce.speculative</name> 9 <value>true</value> 10</property> 11
为什么任务必须幂等? 因为同一份数据可能被原始 Task 和备份 Task 各写一次(或先写后杀),若写库、发消息等有副作用,就会重复;只读或「同一 key 多次写同一结果」则安全。
自定义 Partitioner
1// 自分区示例:按首字母分区 2public static class FirstLetterPartitioner 3 extends Partitioner<Text, IntWritable> { 4 5 @Override 6 public int getPartition(Text key, IntWritable value, int numPartitions) { 7 String word = key.toString(); 8 char firstChar = word.charAt(0); 9 10 // A-M 到 partition 0 11 if (firstChar >= 'A' && firstChar <= 'M') { 12 return 0; 13 } 14 // N-Z 到 partition 1 15 else { 16 return 1 % numPartitions; 17 } 18 } 19} 20 21// 设置自定义 Partitioner 22job.setPartitionerClass(FirstLetterPartitioner.class); 23job.setNumReduceTasks(2); 24
📊 MapReduce 与 YARN
YARN 架构
YARN
提交 Job
👤 Client
🏢 ResourceManager
📅 Scheduler
资源调度
📋 ApplicationsManager
应用管理
🖥️ NodeManager 1
🖥️ NodeManager 2
🖥️ NodeManager 3
📌 ApplicationMaster
每个 Job 一个
📦 Container 1
Map Task
📦 Container 2
Reduce Task
YARN 组件说明
| 组件 | 职责 | 生活类比 |
|---|---|---|
| ResourceManager | 全局资源管理 | 公司总经理 |
| Scheduler | 分配资源 | 人事经理 |
| NodeManager | 管理单个节点资源 | 部门主管 |
| ApplicationMaster | 管理单个应用 | 项目经理 |
| Container | 资源容器 | 办公工位 |
🔍 监控与调试
常用监控命令
1# 1. 查看运行中的任务 2mapred job -list 3 4# 2. 查看任务详情 5mapred job -status job_1234567890000_0001 6 7# 3. 杀死任务 8mapred job -kill job_1234567890000_0001 9 10# 4. 查看任务日志 11mapred job -logs job_1234567890000_0001 12 13# 5. 查看任务计数器 14mapred job -counter job_1234567890000_0001 15
| 命令 | 为什么常用? |
|---|---|
| mapred job -list | 作业卡住时先看是否在跑、拿到 job_id 才能查 status/logs |
| mapred job -status | 看进度百分比、Map/Reduce 完成数、失败 Task 列表,定位是否数据倾斜或单 Task 失败 |
| mapred job -logs | 失败时看具体异常栈和业务日志,不加 container 会列出所有 Task 的 log 路径 |
| mapred job -counter | 看 MAP_INPUT_RECORDS 等是否异常(如为 0 可能是输入路径或格式问题) |
Web UI
1# 访问 MapReduce Web UI 2http://resourcemanager:8088/ 3 4# 查看的信息: 5# - 运行中的任务 6# - 历史任务 7# - 任务统计信息 8# - 日志查看 9
常见计数器
| 计数器组 | 计数器 | 说明 |
|---|---|---|
| MapReduce 框架 | MAP_INPUT_RECORDS | Map 读取的记录数 |
| MAP_OUTPUT_RECORDS | Map 输出的记录数 | |
| REDUCE_INPUT_RECORDS | Reduce 输入的记录数 | |
| REDUCE_OUTPUT_RECORDS | Reduce 输出的记录数 | |
| 文件系统 | BYTES_READ | 读取的字节数 |
| BYTES_WRITTEN | 写入的字节数 |
🚨 性能优化
优化策略
🚀 MapReduce 性能优化
🔀 减少 Shuffle
⚖️ 优化数据倾斜
⚙️ 调整参数
📊 合理分区
📊 使用 Combiner
🗜️ 压缩中间数据
📉 减少 Map 输出
🔀 自定义 Partitioner
📌 预处理倾斜 Key
💾 调整缓冲区大小
📈 调整并行度
📊 合理设置 Reduce 数
📁 避免小文件
优化配置
1<!-- mapred-site.xml --> 2 3<!-- 启用压缩 --> 4<property> 5 <name>mapreduce.map.output.compress</name> 6 <value>true</value> 7</property> 8 9<!-- Compressor codec --> 10<property> 11 <name>mapreduce.map.output.compress.codec</name> 12 <value>org.apache.hadoop.io.compress.SnappyCodec</value> 13</property> 14 15<!-- 增大 Shuffle 缓冲区 --> 16<property> 17 <name>mapreduce.reduce.shuffle.input.buffer.percent</name> 18 <value>0.7</value> 19</property> 20 21<!-- 并行拷贝数 --> 22<property> 23 <name>mapreduce.reduce.shuffle.parallelcopies</name> 24 <value>10</value> 25</property> 26 27<!-- 推测执行 --> 28<property> 29 <name>mapreduce.map.speculative</name> 30 <value>true</value> 31</property> 32
🎯 总结
核心要点记忆口诀
1MapReduce 大数据 2Map 处理分而治 3Shuffle 传数据排序 4Reduce 汇总出结果 5 6Combiner 减传输 7本地化提性能 8推测执行防慢节点 9YARN 管理调度灵 10
WordCount 完整流程
📂 输入文件
📄 Split 1
📄 Split 2
🗺️ Map 1
🗺️ Map 2
📊 Combiner
🔀 Shuffle & Sort
📊 Reduce
📁 输出文件
生活类比总结
- Map = 各部门统计数据
- Shuffle = 把各部门数据汇总整理
- Reduce = 总部形成最终报告
- Combiner = 各部门先汇总再上报
- 数据本地化 = 就地处理,不搬砖
- 推测执行 = 慢了就叫人帮忙一起做
最后提醒:MapReduce 适合批处理,不适合低延迟交互式查询!对于实时处理,考虑使用 Spark 或 Flink!
📚 官方文档与参考
| 资源 | 链接 | 说明 |
|---|---|---|
| MapReduce Tutorial | Apache Hadoop MapReduce Tutorial | 官方入门教程与 WordCount 示例 |
| Hadoop 文档首页 | Apache Hadoop | 当前版本文档,含 HDFS、YARN、MapReduce |
| MapReduce API | org.apache.hadoop.mapreduce | Mapper、Reducer、Job、InputFormat 等 API 说明 |
MapReduce 与其它计算框架对比(相近方案)
| 维度 | MapReduce | Spark | Flink |
|---|---|---|---|
| 计算模型 | 批处理,Map+Reduce 两阶段 | 批/流统一,内存迭代 DAG | 流优先,批为流特例 |
| 延迟 | 高(多轮落盘) | 中(内存为主) | 低(流式、增量) |
| 适用场景 | 大批量、一次性 ETL、历史分析 | 迭代 ML、交互查询、批处理 | 实时流、事件驱动、精确一次 |
| 生活类比 | 月底统一盘点、报表 | 随时查库存、多轮试算 | 流水线边生产边统计 |
《Hadoop MapReduce 详解》 是转载文章,点击查看原文。