1 OWUI启动脚本
1# Open-WebUI Settings 2export DATA_DIR='data0331' 3export ENABLE_SIGNUP=True 4export DEFAULT_USER_ROLE='admin' 5export DEFAULT_GROUP_ID='xai' 6export OFFLINE_MODE=false 7export HF_HUB_OFFLINE=1 8 9# OpenAI API 配置 10export ENABLE_OLLAMA_API=false 11export ENABLE_OPENAI_API=true 12export OPENAI_API_BASE_URLS='https://api.siliconflow.cn/v1;' 13export OPENAI_API_KEYS='sk-xxx;' 14 15# Activate conda environment 16source ~/miniconda3/etc/profile.d/conda.sh 17conda activate owui-0.6.43 18 19# Start Open-WebUI 20open-webui serve --port 9999 21 22# pkill -f "open-webui --port 9999" && sleep 1 && ps aux | grep open-webui | grep -v grep || echo "已停止" 23 24
2 Chat提取脚本1
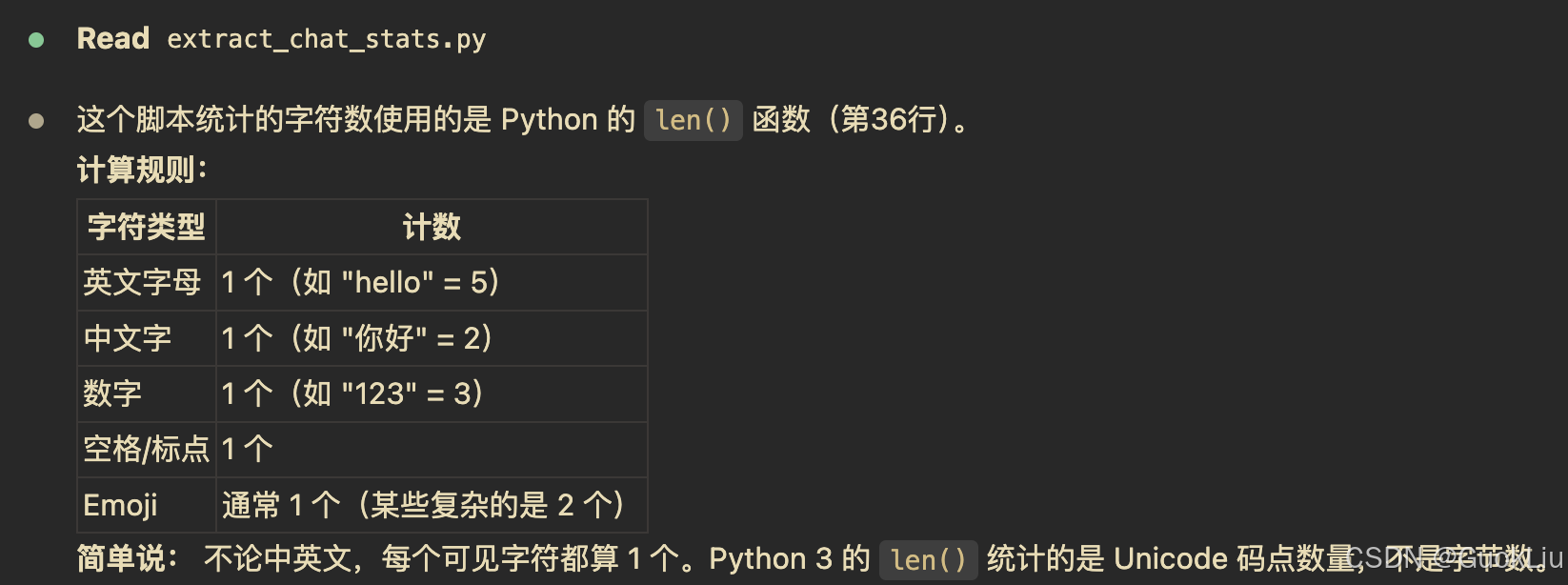
1#!/usr/bin/env python3 2""" 3从webui.db提取chat表数据,计算每个chat中所有content的字符长度,保存到新sqlite文件 4""" 5 6import sqlite3 7import json 8import os 9 10# 配置 11SOURCE_DB = "data0331/webui.db" 12TARGET_DB = "chat_content_stats.db" 13 14 15def extract_content_length(chat_json: str) -> int: 16 """ 17 从chat JSON中提取所有message的content字符长度总和 18 """ 19 if not chat_json: 20 return 0 21 22 try: 23 data = json.loads(chat_json) 24 except json.JSONDecodeError: 25 return 0 26 27 total_length = 0 28 29 # Open-WebUI的chat JSON结构: {"history": {"messages": {...}}} 30 messages = data.get("history", {}).get("messages", {}) 31 32 for msg_id, msg in messages.items(): 33 if isinstance(msg, dict): 34 content = msg.get("content", "") 35 if content: 36 total_length += len(str(content)) 37 38 return total_length 39 40 41def main(): 42 # 检查源数据库是否存在 43 if not os.path.exists(SOURCE_DB): 44 print(f"错误: 源数据库不存在: {SOURCE_DB}") 45 return 46 47 # 连接源数据库 48 source_conn = sqlite3.connect(SOURCE_DB) 49 source_cursor = source_conn.cursor() 50 51 # 获取所有chat记录 52 source_cursor.execute(""" 53 SELECT user_id, created_at, chat 54 FROM chat 55 ORDER BY created_at 56 """) 57 rows = source_cursor.fetchall() 58 print(f"从 {SOURCE_DB} 读取到 {len(rows)} 条chat记录") 59 60 # 创建目标数据库 61 if os.path.exists(TARGET_DB): 62 os.remove(TARGET_DB) 63 64 target_conn = sqlite3.connect(TARGET_DB) 65 target_cursor = target_conn.cursor() 66 67 # 创建目标表 68 target_cursor.execute(""" 69 CREATE TABLE chat_content_stats ( 70 user_id TEXT NOT NULL, 71 created_at TEXT NOT NULL, 72 content_length INTEGER NOT NULL 73 ) 74 """) 75 76 # 插入数据 77 processed = 0 78 for user_id, created_at, chat_json in rows: 79 content_length = extract_content_length(chat_json) 80 target_cursor.execute(""" 81 INSERT INTO chat_content_stats (user_id, created_at, content_length) 82 VALUES (?, ?, ?) 83 """, (user_id, created_at, content_length)) 84 processed += 1 85 86 target_conn.commit() 87 88 # 显示统计信息 89 target_cursor.execute("SELECT COUNT(*), SUM(content_length), AVG(content_length) FROM chat_content_stats") 90 count, total, avg = target_cursor.fetchone() 91 92 print(f"\n处理完成!") 93 print(f"输出文件: {TARGET_DB}") 94 print(f"总记录数: {count}") 95 print(f"总字符数: {total:,}") 96 print(f"平均每条chat字符数: {avg:.2f}") 97 98 # 显示前5条示例 99 print("\n前5条数据示例:") 100 target_cursor.execute("SELECT user_id, created_at, content_length FROM chat_content_stats LIMIT 5") 101 for row in target_cursor.fetchall(): 102 print(f" user_id={row[0][:8]}..., created_at={row[1]}, content_length={row[2]:,}") 103 104 # 关闭连接 105 source_conn.close() 106 target_conn.close() 107 108 109if __name__ == "__main__": 110 main() 111 112
3 Chat提取脚本2
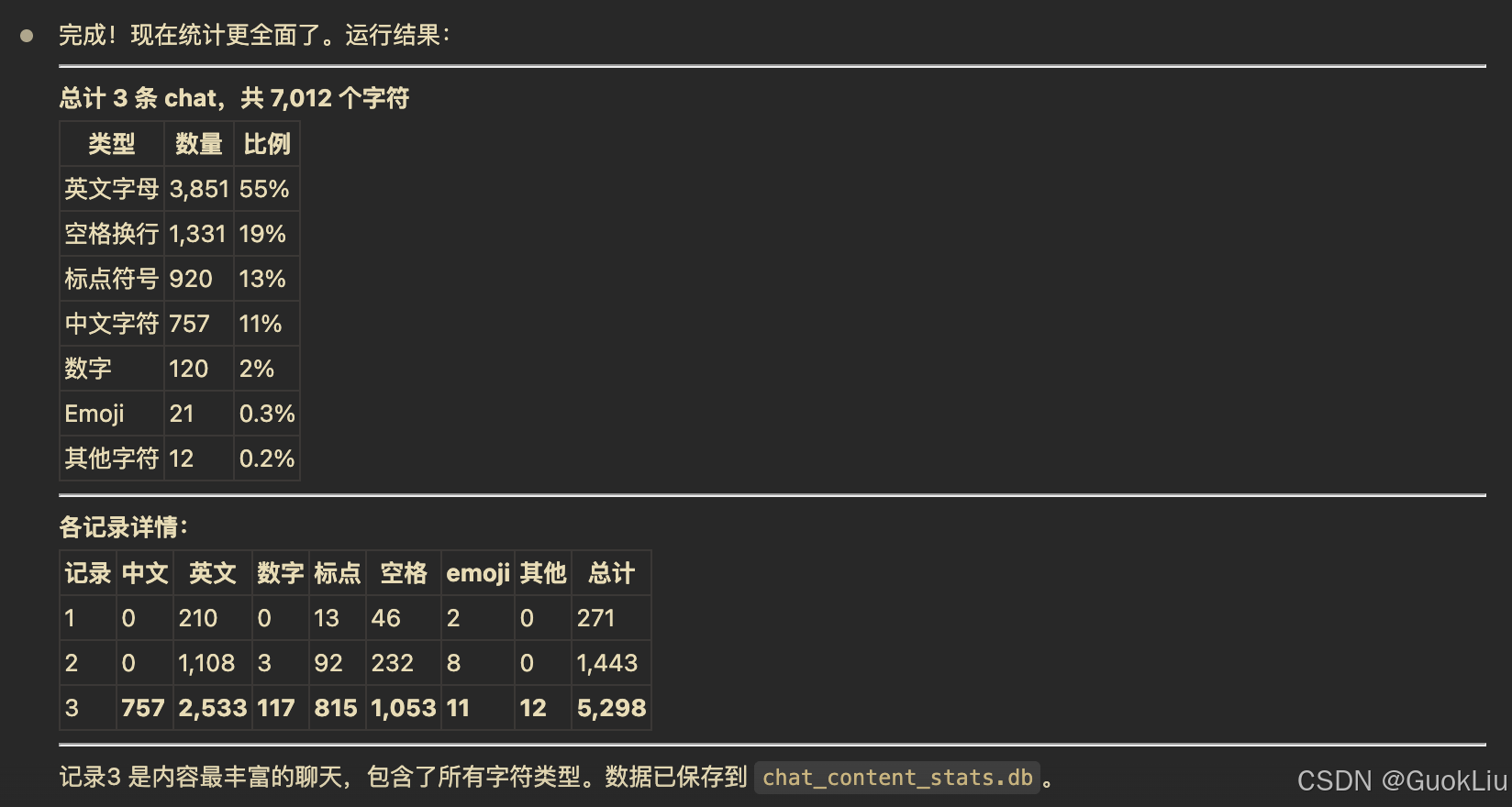
1#!/usr/bin/env python3 2""" 3从webui.db提取chat表数据,计算每个chat中所有content的字符长度,保存到新sqlite文件 4""" 5 6import sqlite3 7import json 8import os 9 10import re 11 12 13# 配置 14SOURCE_DB = "data0331/webui.db" 15TARGET_DB = "chat_content_stats.db" 16 17 18def extract_content_stats(chat_json: str) -> dict: 19 """ 20 从chat JSON中提取内容统计:中文字、英文字母、数字、标点符号、空格、emoji、其他 21 """ 22 if not chat_json: 23 return { 24 "chinese": 0, "english": 0, "digit": 0, 25 "punctuation": 0, "space": 0, "emoji": 0, "other": 0 26 } 27 28 try: 29 data = json.loads(chat_json) 30 except json.JSONDecodeError: 31 return { 32 "chinese": 0, "english": 0, "digit": 0, 33 "punctuation": 0, "space": 0, "emoji": 0, "other": 0 34 } 35 36 chinese_count = 0 37 english_count = 0 38 digit_count = 0 39 punctuation_count = 0 40 space_count = 0 41 emoji_count = 0 42 other_count = 0 43 44 # 标点符号定义 45 punctuation_chars = set(".,;:!?-'\"()[]{}<>`~@#$%^&*+=_|\\/·,。;:!?、""''()【】《》「」『』〔〕~@#¥%……&*——+|\\") 46 47 # Emoji范围检测 48 def is_emoji(char): 49 code = ord(char) 50 return ( 51 0x1F600 <= code <= 0x1F64F or # 表情符号 52 0x1F300 <= code <= 0x1F5FF or # 符号和象形文字 53 0x1F680 <= code <= 0x1F6FF or # 交通和地图符号 54 0x1F700 <= code <= 0x1F77F or # 其他符号 55 0x1F780 <= code <= 0x1F7FF or # 几何图形 56 0x1F900 <= code <= 0x1F9FF or # 补充符号 57 0x1FA00 <= code <= 0x1FA6F or # 扩展符号 58 0x2600 <= code <= 0x26FF or # 杂项符号 59 0x2700 <= code <= 0x27BF or # 装饰符号 60 0x2B50 <= code <= 0x2B55 or # 更多符号 61 0x1F1E0 <= code <= 0x1F1FF # 国旗 62 ) 63 64 # Open-WebUI的chat JSON结构: {"history": {"messages": {...}}} 65 messages = data.get("history", {}).get("messages", {}) 66 67 for msg_id, msg in messages.items(): 68 if isinstance(msg, dict): 69 content = str(msg.get("content", "")) 70 for char in content: 71 if '\u4e00' <= char <= '\u9fff': # 中文字符范围 72 chinese_count += 1 73 elif char.isalpha(): # 英文字母 74 english_count += 1 75 elif char.isdigit(): # 数字 76 digit_count += 1 77 elif char.isspace(): # 空格、换行等空白字符 78 space_count += 1 79 elif is_emoji(char): # Emoji 80 emoji_count += 1 81 elif char in punctuation_chars: # 标点符号 82 punctuation_count += 1 83 else: 84 other_count += 1 85 86 return { 87 "chinese": chinese_count, 88 "english": english_count, 89 "digit": digit_count, 90 "punctuation": punctuation_count, 91 "space": space_count, 92 "emoji": emoji_count, 93 "other": other_count 94 } 95 96 97def main(): 98 # 检查源数据库是否存在 99 if not os.path.exists(SOURCE_DB): 100 print(f"错误: 源数据库不存在: {SOURCE_DB}") 101 return 102 103 # 连接源数据库 104 source_conn = sqlite3.connect(SOURCE_DB) 105 source_cursor = source_conn.cursor() 106 107 # 获取所有chat记录,包含user_id 108 source_cursor.execute(""" 109 SELECT user_id, created_at, chat 110 FROM chat 111 ORDER BY created_at 112 """) 113 rows = source_cursor.fetchall() 114 print(f"从 {SOURCE_DB} 读取到 {len(rows)} 条chat记录") 115 116 # 获取所有用户的email映射 {user_id: email} 117 source_cursor.execute("SELECT id, email FROM user") 118 user_emails = dict(source_cursor.fetchall()) 119 print(f"从 user 表读取到 {len(user_emails)} 个用户") 120 121 # 创建目标数据库 122 if os.path.exists(TARGET_DB): 123 os.remove(TARGET_DB) 124 125 target_conn = sqlite3.connect(TARGET_DB) 126 target_cursor = target_conn.cursor() 127 128 # 创建目标表 129 target_cursor.execute(""" 130 CREATE TABLE chat_content_stats ( 131 user_id TEXT NOT NULL, 132 email TEXT, 133 created_at TEXT NOT NULL, 134 chinese INTEGER NOT NULL DEFAULT 0, 135 english INTEGER NOT NULL DEFAULT 0, 136 digit INTEGER NOT NULL DEFAULT 0, 137 punctuation INTEGER NOT NULL DEFAULT 0, 138 space INTEGER NOT NULL DEFAULT 0, 139 emoji INTEGER NOT NULL DEFAULT 0, 140 other INTEGER NOT NULL DEFAULT 0 141 ) 142 """) 143 144 # 插入数据 145 processed = 0 146 for user_id, created_at, chat_json in rows: 147 stats = extract_content_stats(chat_json) 148 email = user_emails.get(user_id, "unknown") 149 target_cursor.execute(""" 150 INSERT INTO chat_content_stats 151 (user_id, email, created_at, chinese, english, digit, punctuation, space, emoji, other) 152 VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?) 153 """, (user_id, email, created_at, stats["chinese"], stats["english"], stats["digit"], 154 stats["punctuation"], stats["space"], stats["emoji"], stats["other"])) 155 processed += 1 156 157 target_conn.commit() 158 159 # 显示统计信息 160 target_cursor.execute(""" 161 SELECT 162 COUNT(*), 163 SUM(chinese), 164 SUM(english), 165 SUM(digit), 166 SUM(punctuation), 167 SUM(space), 168 SUM(emoji), 169 SUM(other), 170 AVG(chinese + english + digit + punctuation + space + emoji + other) 171 FROM chat_content_stats 172 """) 173 result = target_cursor.fetchone() 174 count = result[0] 175 total_chinese, total_english, total_digit, total_punct = result[1:5] 176 total_space, total_emoji, total_other = result[5:8] 177 avg = result[8] 178 179 # 计算总计 180 grand_total = sum([total_chinese, total_english, total_digit, 181 total_punct, total_space, total_emoji, total_other]) 182 183 print(f"\n处理完成!") 184 print(f"输出文件: {TARGET_DB}") 185 print(f"总记录数: {count}") 186 print(f"\n【字符类型统计】") 187 print(f" 中文字符: {total_chinese:,}") 188 print(f" 英文字母: {total_english:,}") 189 print(f" 数字: {total_digit:,}") 190 print(f" 标点符号: {total_punct:,}") 191 print(f" 空格换行: {total_space:,}") 192 print(f" Emoji: {total_emoji:,}") 193 print(f" 其他字符: {total_other:,}") 194 print(f" ─────────") 195 print(f" 总计: {grand_total:,}") 196 print(f"\n平均每条chat字符数: {avg:.2f}") 197 198 # 显示前5条示例 199 print("\n【前3条数据示例】:") 200 target_cursor.execute(""" 201 SELECT user_id, email, created_at, chinese, english, digit, 202 punctuation, space, emoji, other 203 FROM chat_content_stats 204 LIMIT 3 205 """) 206 for i, row in enumerate(target_cursor.fetchall()): 207 total = sum(row[3:]) 208 print(f"\n 记录 {i+1}:") 209 print(f" user_id={row[0][:8]}..., email={row[1]}") 210 print(f" created_at={row[2]}") 211 print(f" 中文={row[3]:,}, 英文={row[4]:,}, 数字={row[5]:,}") 212 print(f" 标点={row[6]:,}, 空格={row[7]:,}, emoji={row[8]:,}, 其他={row[9]:,}") 213 print(f" 总计={total:,}") 214 215 # 关闭连接 216 source_conn.close() 217 target_conn.close() 218 219 220if __name__ == "__main__": 221 main() 222 223
《260331-OpenWebUI统计所有Chat的对话字符个数》 是转载文章,点击查看原文。
