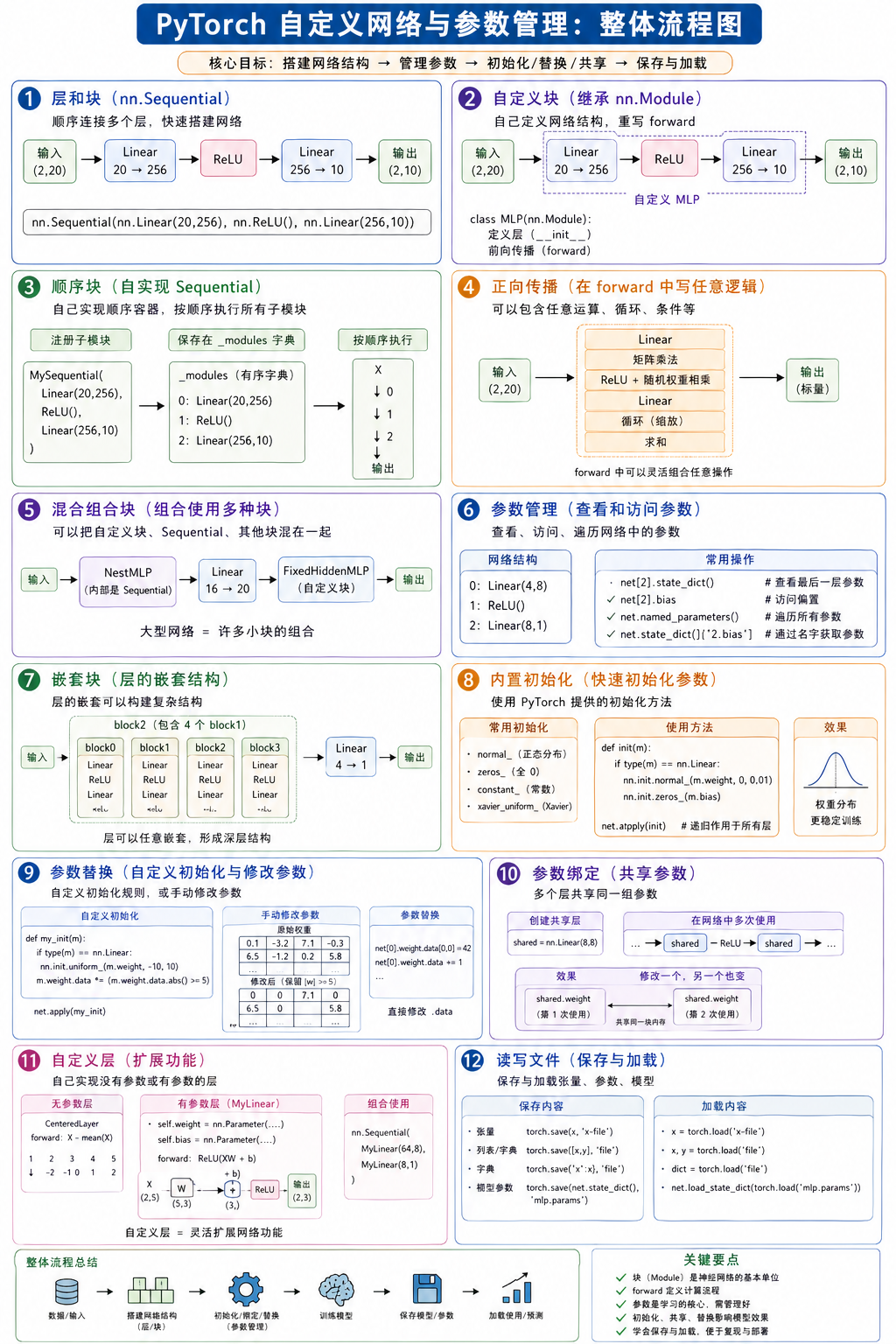
1. 层和块
① nn.Sequential 定义了一种特殊的Module。
1# 回顾一下多层感知机 2import torch #基础计算(类似 numpy) 3from torch import nn #神经网络工具(层、模型) 4from torch.nn import functional as F #一些函数(比如激活函数) 5#搭建神经网络结构 6net = nn.Sequential(nn.Linear(20,256),nn.ReLU(),nn.Linear(256,10)) 7 8#造输入数据 9#生成随机数据:2行 × 20列 10#2个样本,每个样本有20个特征 11X = torch.rand(2,20) 12net(X)
🧱 第1层:线性层
nn.Linear(20,256)👉 意思是:
1输入:20个数 2输出:256个数数学上:
👉 本质就是:
- 把 20 维 → 变成 256 维
- 相当于“扩展信息”
⚡ 第2层:激活函数
nn.ReLU()👉 ReLU 规则:
1小于0 → 变成0 2大于0 → 保留比如:
[-2, 3, -1, 5] → [0, 3, 0, 5]👉 作用:
- 加入“非线性”
- 不然模型太简单(只能学直线)
🧱 第3层:线性层
nn.Linear(256,10)👉 意思是:
1输入:256个数 2输出:10个数👉 最终得到:
- 10维输出(比如10个类别 / 10个预测值)
🧩 Sequential 是什么?
nn.Sequential(...)👉 意思是:
按顺序执行这些层
就像流水线:
1输入 2↓ 3Linear(20→256) 4↓ 5ReLU 6↓ 7Linear(256→10) 8↓ 9输出
X (2×20) ↓ Linear(20→256) → 变成 (2×256) ↓ ReLU → 还是 (2×256) ↓ Linear(256→10) → 变成 (2×10)
tensor([[-0.0214, -0.1789, -0.0700, -0.0238, -0.2697, 0.0381, 0.3078, -0.2082, -0.1502, 0.0433], [ 0.0200, -0.1466, -0.0633, 0.0031, -0.2042, 0.0993, 0.3137, -0.1206, -0.1057, 0.0434]], grad_fn=<AddmmBackward0>)
2. 自定义块
把第一个刚才的
Sequential写法,换成“手写版”。本质一样,但更灵活。自己定义一个神经网络类(MLP),然后用它处理数据
1#定义一个“神经网络模型”,名字叫 MLP ; 2#nn.Module 是所有模型的“基类”(必须继承 3class MLP(nn.Module): 4 #初始化函数 5 def __init__(self): 6 super().__init__() # 调用父类的__init__函数 7 #定义层 8 self.hidden = nn.Linear(20,256)#输入20 → 输出256 9 self.out = nn.Linear(256,10)#输入256 → 输出10 10 #定义前向传播 11 def forward(self, X): 12 return self.out(F.relu(self.hidden(X))) 13 14# 实例化多层感知机的层,然后在每次调用正向传播函数调用这些层 15net = MLP() 16#造数据 17X = torch.rand(2,20) 18#喂数据;自动执行:forward(X) 19net(X)
tensor([[-0.1600, 0.0363, 0.0851, 0.0364, 0.0189, 0.1590, 0.1519, 0.1299, -0.1382, -0.2075], [-0.1956, 0.0779, -0.0385, -0.0741, 0.0229, 0.0116, 0.1271, 0.0273, -0.0867, -0.0511]], grad_fn=<AddmmBackward0>)
3. 顺序块
自己写了一个“按顺序执行层”的容器(模仿
nn.Sequential)
1#定义一个模型类 2class MySequential(nn.Module): 3 #初始化(收集所有层) 4 #*args可以传“任意多个参数 5 def __init__(self, *args): 6 super().__init__() 7 for block in args: 8 #_modules PyTorch 内部的一个“字典,专门用来存模型里的“层” 9 #把每一层存进去 10 self._modules[block] = block # block 本身作为它的key,存在_modules里面的为层,以字典的形式 11 #定义数据怎么流动 12 def forward(self, X): 13 #取出所有层(按顺序) 14 for block in self._modules.values(): 15 print(block) 16 X = block(X) 17 return X 18 #创建模型把三层传进去 19net = MySequential(nn.Linear(20,256),nn.ReLU(),nn.Linear(256,10)) 20X = torch.rand(2,20) 21net(X) 22
Linear(in_features=20, out_features=256, bias=True)
ReLU()
Linear(in_features=256, out_features=10, bias=True)
tensor([[-0.0651, 0.0377, -0.0348, -0.0377, 0.1602, 0.0022, -0.0904, 0.1742, -0.0520, 0.0189], [-0.0192, 0.1056, -0.0497, 0.0301, 0.2464, 0.0126, -0.1700, 0.4147, 0.0703, -0.0013]], grad_fn=<AddmmBackward0>)
4. 正向传播
这段代码比前面的更“自由”,它在
forward里加了矩阵运算 + 循环 + 自定义逻辑做两次线性变换,中间插入随机矩阵计算,还会把结果不断缩小,最后输出一个数
1# 在正向传播函数中执行代码 2class FixedHiddenMLP(nn.Module): 3 def __init__(self): 4 super().__init__() 5 #定义一个“随机权重,创建一个 20×20 的随机矩阵 6 #requires_grad=False这个矩阵不会被训练,是“固定的” 7 self.rand_weight = torch.rand((20,20),requires_grad=False) 8 self.linear = nn.Linear(20,20) 9 10 def forward(self, X): 11 X = self.linear(X)#X = WX + b 12 #矩阵乘法 + ReLU 13 #self.rand_weight + 1把随机矩阵每个元素 +1 14 #torch.mm(X, ...)矩阵乘法:相当于“再变换一次数据” 15 #F.relu(...)负数变0 16 X = F.relu(torch.mm(X, self.rand_weight + 1))#线性 → 随机变换 → 激活 17 #参数共享(同一层用两次) 18 X = self.linear(X) 19 #把数值压小 20 while X.abs().sum() > 1: 21 X /= 2 22 return X.sum() 23 24net = FixedHiddenMLP() 25X = torch.rand(2,20) 26net(X)
tensor(0.3770, grad_fn=<SumBackward0>)

5. 混合组合块
模型可以“套娃”——一个模型里面再放模型
先用一个小网络处理 → 再接一层 → 再接一个“怪模型” → 得到最终结果
1# 混合代培各种组合块的方法 2class NestMLP(nn.Module): 3 def __init__(self): 4 super().__init__() 5 #一个“小网络”: 20 → 64 → 32 6 self.net = nn.Sequential(nn.Linear(20,64),nn.ReLU(), 7 nn.Linear(64,32),nn.ReLU()) 8 #再加一层:32 → 16 9 self.linear = nn.Linear(32,16) 10 11 def forward(self, X): 12 return self.linear(self.net(X)) 13#第1块:NestMLP()输入 20 → 输出 16 14#第2块:nn.Linear(16,20)输入 16 → 输出 20 15#第3块:FixedHiddenMLP()输入 20 → 输出 1(一个数) 16chimear = nn.Sequential(NestMLP(),nn.Linear(16,20),FixedHiddenMLP()) 17X = torch.rand(2,20) 18chimear(X)
tensor(-0.1488, grad_fn=<SumBackward0>)
6. 参数管理
这段代码的核心是在教你一件事:
如何“看见”和“操作”神经网络里的参数(权重和偏置)
1# 首先关注具有单隐藏层的多层感知机 2import torch 3from torch import nn 4 5#输入4维 → 变成8维 → ReLU → 变成1维 6net = nn.Sequential(nn.Linear(4,8),nn.ReLU(),nn.Linear(8,1)) 7#2个样本,每个4个特征 8X = torch.rand(size=(2,4)) 9print(net(X)) 10#state_dict()返回这一层的参数:weight': 权重矩阵,'bias': 偏置 11print(net[2].state_dict()) # 访问参数,net[2]就是最后一个输出层net[2] → Linear(8→1) 12print(type(net[2].bias)) # 目标参数 13print(net[2].bias) 14print(net[2].bias.data)#打印纯数据,只看“数值”,不管梯度 15print(net[2].weight.grad == None) # 还没进行反向计算,所以grad为None 16print(*[(name, param.shape) for name, param in net[0].named_parameters()]) # 一次性访问所有参数 17print(*[(name, param.shape) for name, param in net.named_parameters()]) # 0是第一层名字,1是ReLU,它没有参数 18print(net.state_dict()['2.bias'].data) # 通过名字获取参数
tensor([[0.3941], [0.4224]], grad_fn=<AddmmBackward0>) OrderedDict([('weight', tensor([[ 4.7564e-02, -5.3226e-02, 1.4919e-04, -2.8679e-01, 1.7408e-01, 3.0859e-01, -1.2281e-01, 5.6171e-02]])), ('bias', tensor([0.3129]))]) <class 'torch.nn.parameter.Parameter'> Parameter containing: tensor([0.3129], requires_grad=True) tensor([0.3129]) True ('weight', torch.Size([8, 4])) ('bias', torch.Size([8])) ('0.weight', torch.Size([8, 4])) ('0.bias', torch.Size([8])) ('2.weight', torch.Size([1, 8])) ('2.bias', torch.Size([1])) tensor([0.3129])

7. 嵌套块
“把小模块重复组合,变成一个很深的网络”
先造一个小网络(block1) → 复制4份 → 串起来 → 最后再接一层输出
1# 从嵌套块收集参数 2#这是一个“小网络”:4 → 8 → 4 3def block1(): 4 return nn.Sequential(nn.Linear(4,8),nn.ReLU(),nn.Linear(8,4),nn.ReLU()) 5 6def block2(): 7 net = nn.Sequential()#先创建一个“空容器” 8 #循环添加4个 block1 9 for i in range(4): 10 net.add_module(f'block{i}',block1()) # f'block{i}' 可以传一个字符串名字过来,block2可以嵌套四个block1 11 return net 12#构建大模型 13rgnet = nn.Sequential(block2(), nn.Linear(4,1)) 14#每个样本 → 一个结果 15print(rgnet(X)) 16#打印结构 17print(rgnet)
tensor([[-0.1750], [-0.1750]], grad_fn=<AddmmBackward0>) Sequential( (0): Sequential( (block0): Sequential( (0): Linear(in_features=4, out_features=8, bias=True) (1): ReLU() (2): Linear(in_features=8, out_features=4, bias=True) (3): ReLU() ) (block1): Sequential( (0): Linear(in_features=4, out_features=8, bias=True) (1): ReLU() (2): Linear(in_features=8, out_features=4, bias=True) (3): ReLU() ) (block2): Sequential( (0): Linear(in_features=4, out_features=8, bias=True) (1): ReLU() (2): Linear(in_features=8, out_features=4, bias=True) (3): ReLU() ) (block3): Sequential( (0): Linear(in_features=4, out_features=8, bias=True) (1): ReLU() (2): Linear(in_features=8, out_features=4, bias=True) (3): ReLU() ) ) (1): Linear(in_features=4, out_features=1, bias=True) )
8 内置初始化
三种初始化 + “给不同层用不同初始化
第一部分:随机初始化
1net = nn.Sequential(nn.Linear(4,8),nn.ReLU(),nn.Linear(8,1)) 2 3#定义初始化函数 4def init_normal(m): 5 if type(m) == nn.Linear: 6 #weight:小随机数(接近0);bias:全0 7 nn.init.normal_(m.weight, mean=0, std=0.01) # 下划线表示把m.weight的值替换掉 8 nn.init.zeros_(m.bias) 9 #应用到整个模型 10net.apply(init_normal) # 会递归调用 直到所有层都初始化 11print(net[0].weight.data[0]) 12print(net[0].bias.data[0])
tensor([ 0.0012, -0.0112, -0.0153, 0.0218])#权重都接近0
tensor(0.)#偏差都是0
第二部分:常数初始化(全部=1)
1 2 3net = nn.Sequential(nn.Linear(4,8),nn.ReLU(),nn.Linear(8,1)) 4 5def init_constant(m): 6 if type(m) == nn.Linear: 7 nn.init.constant_(m.weight,1) 8 nn.init.zeros_(m.bias) 9 10net.apply(init_constant) 11print(net[0].weight.data[0]) 12print(net[0].bias.data[0])
tensor([1., 1., 1., 1.]) tensor(0.)
第三部分:不同层用不同初始化(重点!)
**#Xavier 初始化(推荐):**根据输入输出维度自动调整范围
作用:
✔ 防止梯度爆炸/消失
✔ 训练更稳定**42 初始化(演示用):**所有权重 = 42(只是演示)
关键操作:只初始化某一层
🔥 apply 的两种用法
✅ 全局初始化
net.apply(func)👉 所有层都会执行
✅ 局部初始化
net[某一层].apply(func)👉 只改这一层
1# 对某些块应用不同的初始化 2 3def xavier(m): 4 if type(m) == nn.Linear: 5 nn.init.xavier_uniform_(m.weight) 6 7def init_42(m): 8 if type(m) == nn.Linear: 9 nn.init.constant_(m.weight, 42) 10 11net[0].apply(xavier) 12net[2].apply(init_42) 13print(net[0].weight.data[0]) 14print(net[2].weight.data)
tensor([ 0.0479, -0.1771, 0.5267, -0.0020]) tensor([[42., 42., 42., 42., 42., 42., 42., 42.]])
9. 参数替换
自己定义一套“奇怪的初始化规则”,再手动修改权重
1# 自定义初始化 2#第一部分:自定义初始化函数 3def my_init(m): 4 #只处理 Linear 层;只对有权重的层操作(Linear) 5 if type(m) == nn.Linear: 6 print("Init",*[(name, param.shape) for name, param in m.named_parameters()][0]) # 打印名字是啥,形状是啥 7 #随机初始化(范围很大!) 8 nn.init.uniform_(m.weight, -10, 10) 9 m.weight.data *= m.weight.data.abs() >= 5 # 这里*=的代码相当于先计算一个布尔矩阵(先判断>=),然后再用布尔矩阵的对应元素去乘以原始矩阵的每个元素。保留绝对值大于5的权重,不是的话就设为0 10 11#应用初始化 12net.apply(my_init) 13#查看前两行权重 14print(net[0].weight[:2]) 15#手动修改参数 所有权重 +1 16net[0].weight.data[:] += 1 # 参数替换 17net[0].weight.data[0,0] = 42#修改一个元素 18print(net[0].weight.data[0])
最关键一行(重点!!)
m.weight.data *= m.weight.data.abs() >= 5👉 这一行很重要,我给你拆到最简单👇
🧠 第一步:生成“筛选条件”
👉 生成一个“布尔矩阵”:
1True → 保留 2False → 删除举例:
原始权重:
[ 2, 7, -8, 3 ]判断:
abs >= 5 → [False, True, True, False]🧠 第二步:乘上这个布尔矩阵
👉 等价于:
1True → ×1 2False → ×0结果:
1[ 2, 7, -8, 3 ] 2→ [0, 7, -8, 0]🎯 这一行的本质:
只保留“绝对值 ≥ 5”的权重,其它全部变0
Init weight torch.Size([8, 4]) Init weight torch.Size([1, 8]) tensor([[ 0.0000, 7.1240, 0.0000, 5.1135], [-8.6745, -7.3974, 0.0000, -0.0000]], grad_fn=<SliceBackward0>) tensor([42.0000, 8.1240, 1.0000, 6.1135])

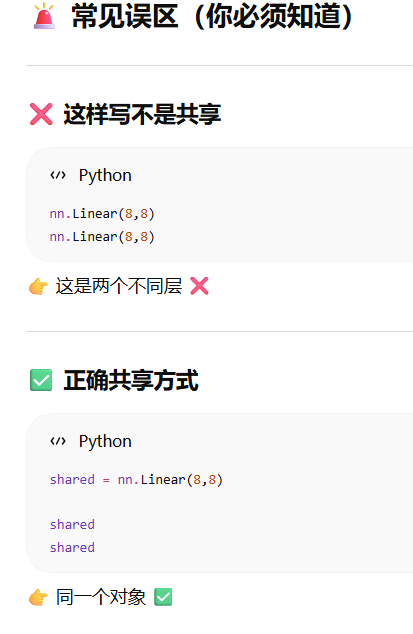
10. 参数绑定
让两个层“用同一份权重”
1# 参数绑定 2#第一步:创建一个共享层,里面有weight(8×8)bias(8) 3shared = nn.Linear(8,8) 4#第二步:构建网络 5net = nn.Sequential(nn.Linear(4,8),nn.ReLU(),shared,nn.ReLU(),shared,nn.ReLU(),nn.Linear(8,1)) # 第2个隐藏层和第3个隐藏层是share权重的,第一个和第四个是自己的 6net(X) 7#第三步:验证是否共享 8print(net[2].weight.data[0] == net[4].weight.data[0]) 9#第四步:修改一个地方 10net[2].weight.data[0,0] = 100#改的是shared 的某一个权重 11#第五步:再检查;结果仍然:全 True 12#因为:net[2] 和 net[4] 指向同一个对象 13print(net[2].weight.data[0] == net[4].weight.data[0])
tensor([True, True, True, True, True, True, True, True]) tensor([True, True, True, True, True, True, True, True])

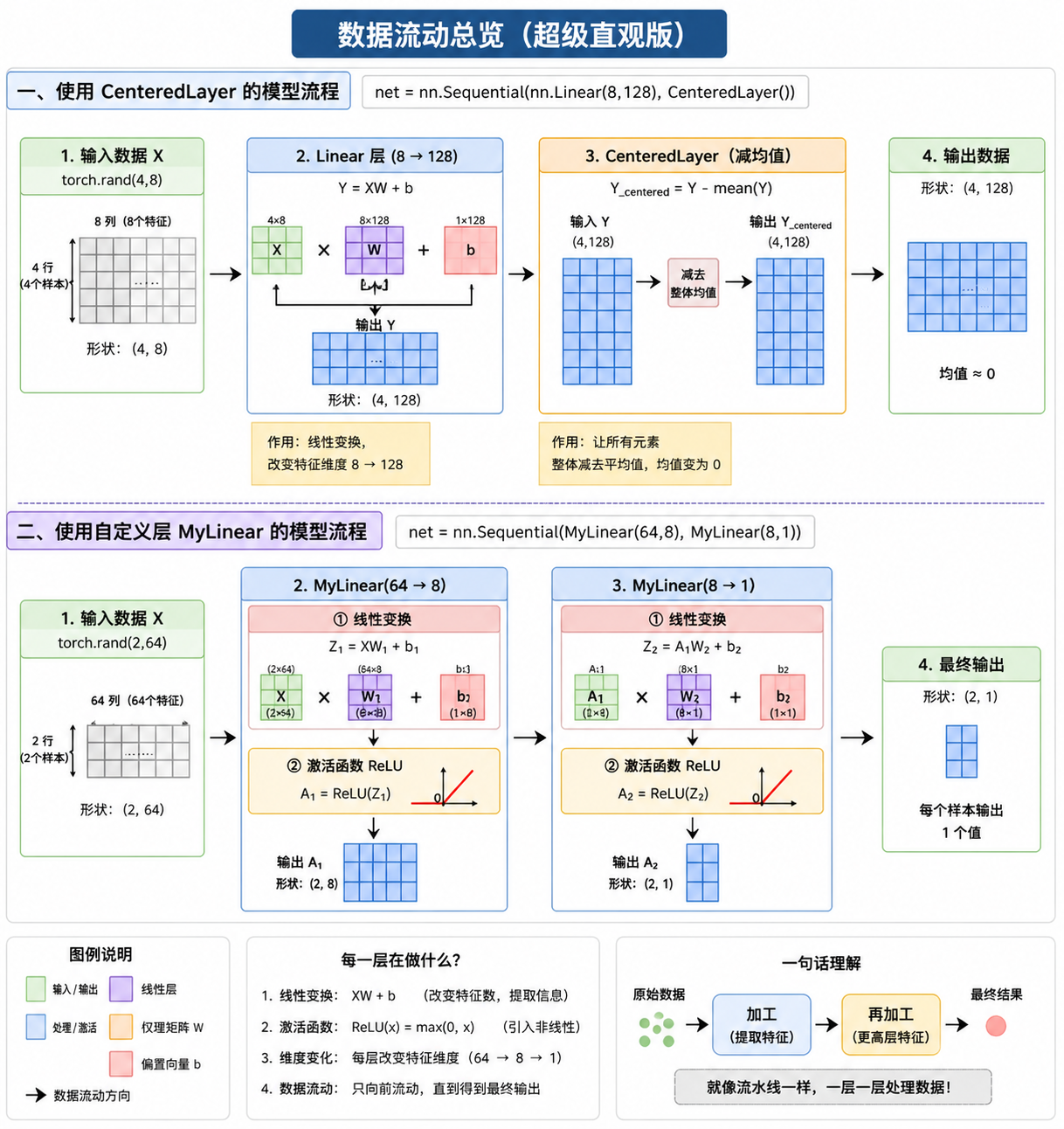
11. 自定义层
👉 学习如何在 PyTorch 里“自己造层 + 组装神经网络”
它分成三步:
11️⃣ 自定义一个没有参数的层 22️⃣ 自定义一个有参数的层 33️⃣ 把这些层拼成一个完整神经网络
1# 构造一个没有任何参数的自定义层 2import torch 3import torch.nn.functional as F 4from torch import nn 5 6#第一部分:无参数层 CenteredLayer 7class CenteredLayer(nn.Module): 8 #构造函数(初始化) 9 def __init__(self): 10 super().__init__() 11 #定义“前向传播” 12 def forward(self, X): 13 #让数据变成“均值为0,X.mean()为均值 14 return X - X.mean() 15#测试这个层,创建一个实例 16layer = CenteredLayer() 17print(layer(torch.FloatTensor([1,2,3,4,5]))) 18 19#第二部分:把层放进模型 20# 将层作为组件合并到构建更复杂的模型中 21net = nn.Sequential(nn.Linear(8,128),CenteredLayer())#CenteredLayer():把输出变成均值0 22#输入4个样本,每个样本8个特征 23Y = net(torch.rand(4,8)) 24print(Y.mean()) 25 26#第三部分:自定义“有参数层” 27# 带参数的图层 28class MyLinear(nn.Module): 29 def __init__(self, in_units, units):#in_units:输入维度;units:输出维度 30 super().__init__() 31 #创建权重矩阵:形状:(输入维度, 输出维度) 32 self.weight = nn.Parameter(torch.randn(in_units,units)) # nn.Parameter使得这些参数加上了梯度 33 #偏置;形状:(输出维度,) 34 self.bias = nn.Parameter(torch.randn(units,)) 35 36 def forward(self, X): 37 linear = torch.matmul(X, self.weight.data) + self.bias.data 38 return F.relu(linear) 39 40dense = MyLinear(5,3) 41print(dense.weight) 42 43# 使用自定义层直接执行正向传播计算 44print(dense(torch.rand(2,5))) 45 46#第四部分 使用自定义层构建模型 47net = nn.Sequential(MyLinear(64,8),MyLinear(8,1)) 48print(net(torch.rand(2,64)))
tensor([-2., -1., 0., 1., 2.]) tensor(-6.2864e-09, grad_fn=<MeanBackward0>) Parameter containing: tensor([[-2.8449, 0.1887, 0.7945], [ 0.4226, 1.6180, -0.5880], [-0.4794, -0.0817, -0.3648], [-0.1979, 0.8702, -0.3515], [-1.4943, 0.3618, 0.2969]], requires_grad=True) tensor([[0.0000, 0.0000, 1.3957], [0.8225, 0.0000, 0.9089]]) tensor([[0.], [0.]])
12. 读写文件
① 保存 / 读取数据(张量)
② 保存 / 恢复模型参数(神经网络)
1# 加载和保存张量 2import torch 3from torch import nn 4from torch.nn import functional as F 5 6#保存一个张量 7x = torch.arange(4) 8torch.save(x, 'x-file') #把x存到硬盘文件 "x-file" 里 9x2 = torch.load("x-file")#从文件读回来 10print(x2) #输出刚刚恢复的数据 11 12#保存多个张量 13#存储一个张量列表,然后把它们读回内存 14y = torch.zeros(4)#y = [0,0,0,0] 15torch.save([x,y],'x-files') #一个列表:[x, y] 16x2, y2 = torch.load('x-files')#x2 = x,y2 = y 17print(x2) 18print(y2) 19 20#保存字典 21# 写入或读取从字符串映射到张量的字典 22mydict = {'x':x,'y':y} 23torch.save(mydict,'mydict') 24mydict2 = torch.load('mydict') 25print(mydict2)
tensor([0, 1, 2, 3]) tensor([0, 1, 2, 3]) tensor([0., 0., 0., 0.]) {'x': tensor([0, 1, 2, 3]), 'y': tensor([0., 0., 0., 0.])}

1# 加载和保存模型参数 2#1. 定义模型 3class MLP(nn.Module):#定义一个神经网络(多层感知机) 4 def __init__(self): 5 super().__init__() 6 self.hidden = nn.Linear(20,256) 7 self.output = nn.Linear(256,10) 8 9 def forward(self, x): 10 return self.output(F.relu(self.hidden(x))) 11 12#2. 跑一遍模型 13net = MLP() 14#输入2个样本,每个20维 15X = torch.randn(size=(2,20)) 16Y = net(X) 17 18# 将模型的参数存储为一个叫做"mlp.params"的文件 19torch.save(net.state_dict(),'mlp.params')#只保存“参数”,不保存模型结构 20 21#4. 加载模型参数 22# 实例化了原始多层感知机模型的一个备份。直接读取文件中存储的参数 23clone = MLP() # 必须要先声明一下,才能导入参数 24#clone = 原来那个模型的复制品 25clone.load_state_dict(torch.load("mlp.params")) 26#eval() 作用:进入“测试模式”(关闭 dropout / batchnorm 等) 27print(clone.eval()) # eval()是进入测试模式 28 29#5. 验证是否成功 30#用同一个输入 31Y_clone = clone(X) 32#检查:两个输出是否一样 33print(Y_clone == Y)
MLP( (hidden): Linear(in_features=20, out_features=256, bias=True) (output): Linear(in_features=256, out_features=10, bias=True) ) tensor([[True, True, True, True, True, True, True, True, True, True], [True, True, True, True, True, True, True, True, True, True]])
《深度学习(13)PyTorch神经网络基础》 是转载文章,点击查看原文。

