一、背景介绍
在离线批处理场景中,编写一个 Join SQL 是再平常不过的操作——两张有限的数据集,在某个键上关联,输出结果。但当你把这套 SQL 语义移植到实时流处理场景时,一切都变了。
| 特性 | 批处理 Join | 流处理 Join |
|---|---|---|
| 数据特征 | 有限、静态、全量数据集 | 无限、动态、无界数据流 |
| 执行模式 | 一次性全量匹配,结果固定 | 持续计算,结果随新数据实时更新 |
| 状态管理 | 无需长期状态,计算完成即释放 | 必须维护历史状态以匹配未来数据 |
| 时间维度 | 无时间概念,基于完整数据集 | 强依赖事件时间 / 处理时间处理乱序与延迟 |
| 计算成本 | 可预测,适合大规模数据 | 持续消耗资源,需控制状态大小与计算频率 |
在实时数仓建设与流式计算中,Flink SQL Join 在生产环境面临三大核心挑战:
- 无界性与状态爆炸:流数据是无穷尽的,传统的等值Join(Regular Join)需要将两侧的数据全部保存在State中,长时间运行极易导致OOM(内存溢出)。
- 数据乱序与延迟:实时数据到达算子的时间可能偏离其真实发生时间(Event Time乱序),如何避免因为数据迟到导致Join结果错误或遗漏?
- 数据漂移:在关联维度表时,维表数据是动态更新的(如用户地址变更),流表数据应该关联哪个历史版本的维表?这就是流计算中著名的"Temporal Issue"(时态问题)。
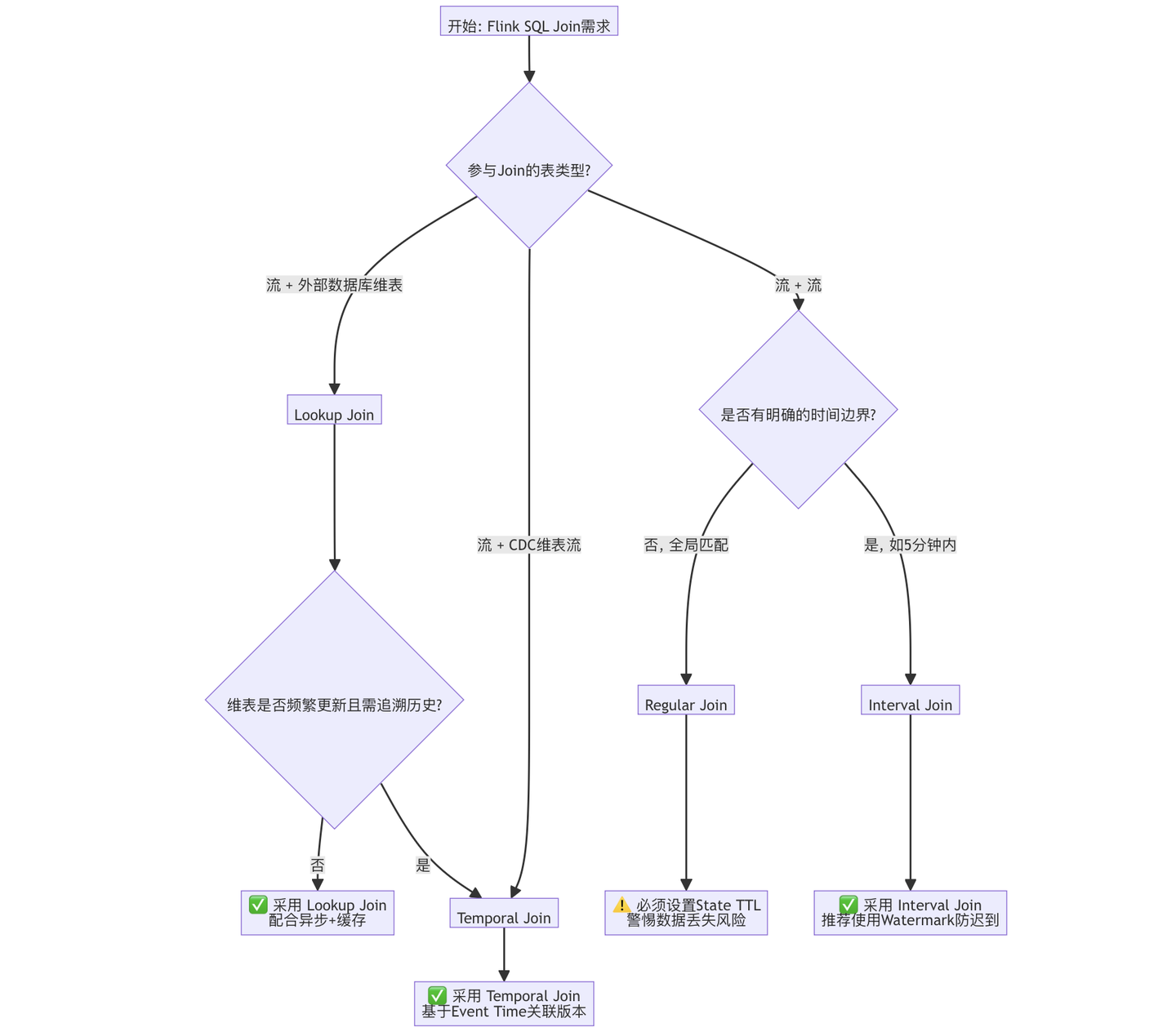
Flink SQL 通过扩展标准 SQL 语义,针对流处理场景提供了四种核心 Join 实现,每种方式都在状态管理、时间处理和适用场景上做了权衡优化。

二、Flink SQL 核心 Join 方式详解
1.Regular Join(常规 Join)
Regular Join 是最通用的 Join 类型,语法与传统批 SQL 完全一致。其执行机制是:Flink 在状态中完整保存两侧输入流的所有历史记录。当一条新数据到达时,Flink 会探查另一侧的状态,找出所有匹配的记录并输出结果。
核心问题在于:Flink 无法预知未来是否会有一条数据能与过去的数据匹配,因此它必须永久保留所有数据,这导致状态无限增长。
- 适用场景:
- 数据量小且更新频率低的场景(如配置表关联)
- 对数据完整性要求高,允许延迟匹配的场景(如用户画像补全)
- 离线数据实时修正(如历史数据更新后关联实时流)
- 限制:
- 必须配置table.exec.state.ttl避免状态爆炸
- 仅支持等值 Join(ON 条件中至少有一个等值谓词),不支持 Cross Join/Theta Join
生产实践中,Regular Join极少直接用于大数据量场景——优先考虑 Interval Join 或 Temporal Join 来获得有界状态。
- 语法说明:Regular Join 支持四种标准 Join 类型:INNER、LEFT、RIGHT、FULL OUTER;标准SQL语法
SELECT * FROM A JOIN B ON A.id = B.id。
Regular Join 的一个重要特性是支持回撤流(Retraction)。以 Left Join 为例:当左流数据先到达但右流尚无匹配时,会先输出+[L, null];当右流后续数据到达并匹配上后,Flink 会先输出-[L, null]回撤之前的错误结果,再输出+[L, R]正确结果。
2.Interval Join(区间 Join)
Interval Join 通过时间窗口约束来解决 Regular Join 的状态无限增长问题。它将 Join 限制在两条流数据时间戳落在特定相对时间区间内的配对,Flink 可以安全地丢弃超出窗口范围的数据状态。
核心机制:每条流的数据在状态中只保留一段时间(窗口长度),超出后自动清理。状态大小是有界且可预测的。
- 适用场景:
- 事件关联(如订单 - 支付、点击 - 曝光、物流 - 签收)
- 实时对账与监控(需限定时间窗口的业务场景)
- 流数据去重(基于时间窗口匹配重复记录)
- 核心优势:
- 自动状态清理,状态大小可控,适合长期运行
- 计算效率高,仅匹配时间窗口内数据,减少计算量
- 支持事件时间,通过 Watermark 处理乱序数据
- 语法说明:在
ON条件中使用BETWEEN ... AND ...结合时间属性字段,满足A.ts BETWEEN B.ts - INTERVAL 'x' AND B.ts + INTERVAL 'y'或等价条件。
与 Regular Join 类似,Interval Join 中任意一条流的数据到达都会触发结果更新。但相比 Regular Join,Interval Join 的优势在于状态是自动清理的——超出时间区间的数据会被安全丢弃。
3.Temporal Join(时态 Join)
Temporal Join 用于将流与版本表(Versioned Table)关联,关联到数据发生时刻的特定版本快照。这在批处理中类似“拉链表”或“快照 Join”的概念,是处理缓慢变化维度(SCD) 的标准方案。
Temporal Join 的核心价值在于:当关联一个会随时间变化的维表时,能够确保关联到数据发生时该维表的快照状态,而不是关联到当前的维表状态——这对于审计和精确回溯至关重要。
- 适用场景:
- 实时计算(如订单金额计算需关联下单时的商品价格)
- 汇率转换(按交易时间关联对应汇率)
- 用户画像分析(关联用户行为发生时的用户属性)
- 数据溯源(查询历史数据对应的维度状态)
- 核心价值:
- 保证结果一致性,不受维度表后续更新影响
- 状态可控,仅保留维度表的版本数据,而非全量历史
- 支持迟到数据处理,通过 Watermark 对齐时间版本
Temporal Join 支持两种时间语义:
事件时间 Temporal Join:使用事件时间关联维表对应时刻的快照。要求维表必须是一个版本表(通常由 CDC 流构建),且两侧使用相同的时间属性。
处理时间 Temporal Join:使用当前处理时间关联维表的最新版本快照。右表需要是一个支持查找的维表连接器(如 HBase、MySQL)。
- 语法说明:维表后面需跟
FOR SYSTEM_TIME AS OF关键字,指明关联的是哪个时间点的维表快照。
4.Lookup Join(维表 Join)
Lookup Join 是流与外部系统(如 Redis、MySQL、HBase) 的关联。当每条流式数据到达时,Flink 通过查询外部存储实时获取维表数据,将维表属性补充到流数据中。
- 适用场景:
- 实时数仓维度补充(如用户、商品、地域维度)
- 外部系统数据关联(如查询 CRM 系统获取客户信息)
- 低延迟维度更新(维表数据频繁更新,无需全量同步)
- 优化建议:
- 开启异步查询(lookup.async=true)提升吞吐量
- 配置本地缓存减少外部系统查询压力
- 优先选择高性能外部存储(如 Redis 替代 MySQL)
- 合理设置缓存 TTL,平衡数据新鲜度与查询性能
- 语法说明:同样使用
FOR SYSTEM_TIME AS OF,但后面跟的是处理时间属性。
5.多维对比与最佳实践指南
| 特性 | Regular Join | Interval Join | Temporal Join | Lookup Join |
|---|---|---|---|---|
| 关联类型 | 流 - 流 | 流 - 流 | 流 - 维表(版本化) | 流 - 外部维表 |
| 状态管理 | 无界(需 TTL) | 有界(自动清理) | 可控(版本历史) | 无状态(外部查询) |
| 时间依赖 | 无时间约束 | 强依赖时间区间 | 强依赖事件时间 / 处理时间 | 可选(处理时间) |
| 适用场景 | 小规模、完整性优先 | 事件关联、对账 | 版本一致性、历史回溯 | 实时维度补充 |
| 性能表现 | 差(状态膨胀) | 优(状态可控) | 中(版本维护) | 中(IO 依赖) |
| 延迟特性 | 低(内存匹配) | 低(内存匹配) | 低(内存匹配) | 中高(IO 延迟) |
| 数据一致性 | 最终一致 | 窗口内一致 | 版本一致 | 外部系统一致 |
| 官方推荐度 | 低(仅特殊场景) | 高(双流关联首选) | 高(维度版本关联) | 高(外部维表关联) |
为了在实际开发中快速选择正确的Join方式,请参考以下决策流程:
在生产环境中的常见优化思路可参考如下:
| 优化方向 | 具体策略 | 适用场景 |
|---|---|---|
| 数据分布 | 合理分区,避免数据倾斜 | 所有 Join 类型,特别是大表关联 |
| MiniBatch 优化 | 开启table.exec.mini-batch.enabled=true | 高吞吐场景,减少状态更新频率 |
| 异步查询 | Lookup Join 开启 async 模式 | 外部维表 IO 密集型场景 |
| 缓存策略 | Lookup Join 配置本地缓存 | 热点维度数据,降低外部系统压力 |
| 多表优化 | 三表以上 Join 使用 Multi-way Join | 减少中间结果存储,提升性能 |
| 广播优化 | 小表广播(BROADCAST hint) | 大表 + 小表 Join,避免数据传输 |
三、总结展望
Flink SQL 提供了四种互补的 Join 实现,解决了流处理场景下数据关联的核心挑战。Flink SQL Join 技术演进的本质,是在状态大小与结果正确性之间寻求平衡。Regular Join 追求完全的准确性(任何晚到的数据都能关联),代价是状态无限增长;Interval Join、Window Join 通过时间约束主动舍弃超出范围的数据,换取有界状态;Temporal Join、Lookup Join 则通过外部化维表状态来减轻内部存储压力。理解这一本质,才能在不同的业务场景中做出正确的 Join 类型选择。
《Flink技术实践-FlinkSQL Join技术全解》 是转载文章,点击查看原文。

