
🫧个人主页:小年糕是糕手
🎨你不能左右天气,但你可以改变心情;你不能改变过去,但你可以决定未来!
目录
一、输入输出
1.1、单组测试用例
1°计算 (a+b)/c 的值
2°与 7 无关的数
1.2、多组测试用例
情况一
1°多组输入a+b II
2°斐波那契数列
3°制糊串
情况二
1°多组输入a+b
2°数字三角形
3°定位查找
情况三
1°字符统计
拓展函数
2°多组数据a+b III
1.3、输入时的特殊技巧
1°含空格字符串的输入技巧 -- 统计数字字符个数
2°数字的特殊处理方式 -- 小乐乐改数字
1.4、scanf / printf与cin / cout的对比
1°格式控制差异
2°性能差异
数字游戏
求第 k 小的数
3°优化方案
二、函数
2.1、概述
1°普通参数
2°数组
3°字符串
4°全局变量
2.2、返回值
2.3、声明和定义
2.4、函数调用
1°传值调用
2°引用
3°效率比较
2.5、函数重载
练习
1°最大数 max(x,y,z)
拓展函数
max
min
2°求正整数 2 和 n 之间的完全数
3°素数个数
4°素数对
5°素数回文数的个数
6°区间内的真素数
三、递归
3.1、概述
3.2、典型案例解析
1°计算阶乘
迭代
递归
2°斐波那契数列
迭代
递归
练习
一、输入输出
前面我们学过了很多种输入输出,cin / cout、scanf / printf、getline、fgets等等,但是实际上的oj编程题中情况一般都是比较常见的几种,下面为大家做个小结并结合一些习题帮助大家更好理解
1.1、单组测试用例
**1°**计算 (a+b)/c 的值
1#include<iostream> 2using namespace std; 3int main() 4{ 5 int a,b,c; 6 cin>>a>>b>>c; 7 int ret=(a+b)/c; 8 cout<<ret<<endl; 9 return 0; 10}
2°与 7 无关的数
1#include<iostream> 2#include<cmath> 3using namespace std; 4int main() 5{ 6 int n; 7 cin >> n; 8 int sum = 0; 9 int i = 1; 10 while (i <= n) 11 { 12 //判断i是否是和7无关 13 if ((i % 7 != 0) && (i % 10 != 7) && (i / 10 != 7)) 14 { 15 sum += i * i; 16 } 17 i++; 18 } 19 cout << sum << endl; 20 return 0; 21}
相信通过前面的学习这两题的代码大家已经是信手拈来了,也没啥好解释的这两道题,只是让大家体会一下什么是单组测试用例,我们重点来看下面的内容:
1.2、多组测试用例
情况一
这部分我们来看测试数据组数已知的情况
1°多组输入a+b II
1#include<iostream> 2using namespace std; 3int main() 4{ 5 int n; 6 cin >> n; 7 int a, b; 8 int ret; 9 while (n--) 10 { 11 ret = 0; 12 cin >> a >> b; 13 ret = a + b; 14 cout << ret << endl; 15 } 16 return 0; 17}
2°斐波那契数列
这里我们提供两种思路,其实还有一种递归的思路,下面章节我们会学习,这里留个悬念,思路一我们是循环读取多组输入的数字a,对每个a用迭代法计算第a个斐波那契数并输出。
1#include<iostream> 2using namespace std; 3int main() 4{ 5 int n; 6 cin>>n; 7 int a; 8 while(n--)//n次访问 9 { 10 cin>>a; 11 //计算第n个斐波那契数 12 int x = 1; 13 int y = 1; 14 int z = 1; 15 while (a > 2) 16 { 17 z = x + y; 18 x = y; 19 y = z; 20 a--; 21 } 22 cout << z << endl; 23 } 24 return 0; 25}
思路二我们采用计算好前30个斐波那契数,存储到ret数组中,需要第几个就从下标几的位置去取
1#include <iostream> 2using namespace std; 3int main() 4{ 5 int n = 0; 6 int a = 0; 7 int i = 0; 8 //计算好前30个斐波那契数,存储到ret数组中 9 //需要第⼏个就从下标⼏的位置去取 10 int ret[40] = { 0, 1, 1 }; 11 for (i = 3; i < 30; i++) 12 { 13 ret[i] = ret[i - 1] + ret[i - 2]; 14 } 15 cin >> n; 16 int z = 0; 17 while (n--) 18 { 19 cin >> a; 20 cout << ret[a] << endl; 21 } 22 return 0; 23}
**3°**制糊串
1#include<iostream> 2#include<string> 3using namespace std; 4int main() 5{ 6 string s, t; 7 cin >> s >> t; 8 string s1, t1; 9 int q, l1, r1, l2, r2; 10 cin >> q; 11 while (q--) 12 { 13 cin >> l1 >> r1 >> l2 >> r2; 14 s1 = s.substr(l1 - 1, r1 - l1 + 1); 15 t1 = t.substr(l2 - 1, r2 - l2 + 1); 16 //比较 17 if (s1 < t1) 18 cout << "yifusuyi" << endl; 19 else if (s1 > t1) 20 cout << "erfusuer" << endl; 21 else 22 cout << "ovo" << endl; 23 } 24 return 0; 25}
编程小技巧:
题目中说 “有 q 次询问”,意思是程序要处理 q 组测试数据,(也就是对应 q 次循环),我们要针对每次询问,给出一个结果。
其实就是之前的单组测试变成了 q 组测试,在之前的代码上套一层 while 循环即可。当有 q 次询问的时候,while (q--) 是非常方便的方式。然后就按照单组输入的方式处理每组输入的数据就好了
情况二
这部分我们来看测试数据组数未知的情况
1°多组输入a+b
1#include<iostream> 2using namespace std; 3int main() 4{ 5 int a,b; 6 while(cin >> a >> b) 7 { 8 cout << a + b <<endl; 9 } 10 return 0; 11}
cin >> a;会返回一个流对象的引用,即cin本身。在 C++ 中,流对象cin可以被用作布尔值来检查流的状态。如果流的状态良好(即没有发生错误),流对象的布尔值为true。如果发生错误(如遇到输入结束符或类型不匹配),布尔值为false。
在
while (cin >> a >> b)语句中,循环的条件部分检查cin流的状态。如果流成功读取到 2 个值,cin >> a >> b返回的流对象cin将被转换为true,循环将继续。如果读取失败(例如遇到输入结束符或无法读取到 2 个值),cin >> a >> b返回的流对象cin将被转换为false,循环将停止。
2°数字三角形
1#include<iostream> 2using namespace std; 3int main() 4{ 5 int n; 6 while(cin >> n) 7 { 8 for(int i = 1;i <= n;i++) 9 { 10 for(int j = 1;j <= i;j++) 11 { 12 cout << j << ' '; 13 } 14 cout<<endl; 15 } 16 17 } 18 return 0; 19}
这个题目其实很类似我们前面写过的,判断质数,乘法口诀表这类
3°定位查找
这里为大家展示两种最常见的写法:
1#include<iostream> 2#include<cstring> 3using namespace std; 4int main() 5{ 6 int n; 7 int arr[20] = {0}; 8 while(cin >> n) 9 { 10 for(int i = 0;i < n;i++) 11 { 12 cin >> arr[i]; 13 } 14 int m; 15 cin >> m; 16 17 int pos = -1; // 标记位置 18 for(int j = 0; j < n; j++) // 从0开始遍历 19 { 20 if(arr[j] == m) 21 { 22 pos = j; 23 break; // 第一次出现就停止 24 } 25 } 26 27 if(pos != -1) 28 cout << pos << endl; 29 else 30 cout << "No" << endl; 31 32 memset(arr, 0, sizeof(arr)); 33 } 34 return 0; 35}
我们来解释这第一段代码:我们定义了一个整型n,代表n组数据,然后定义了一个数组暂且全部初始化为0,下面我们进入while循环,定义了一个for循环来给这个数组赋值,下面定义并且输入一个m作为我们的要查找的值,下面定义了一个pos用来标记位置,然后我们遍历数组并且与m进行比较,如果找到了就跳出循环并且给pos位置赋值标记下标,如果没找到pos还是一开始的值,我们打印no即可,最后使用我们之前学过的memset给数组置为0即可
这个思路很简单,但是其实代码的水平不是很高,有点冗余,下面给出优化之后的解法:
1#include <iostream> 2using namespace std; 3const int N = 25; 4int arr[N]; 5int main() 6{ 7 int n = 0; 8 int m = 0; 9 while (cin >> n) 10 { 11 //输入n个数字,存放在arr中 12 for (int i = 0; i < n; i++) 13 { 14 cin >> arr[i]; 15 } 16 //输入m 17 cin >> m; 18 int i = 0; 19 //在arr数组中查找m 20 for (i = 0; i < n; i++) 21 { 22 if (m == arr[i]) 23 { 24 cout << i << endl; 25 break; 26 } 27 } 28 if (i == n) 29 cout << "No" << endl; 30} 31 return 0; 32}
这里我们舍弃了memset,因为这里其实根本不需要去清空数组,上一次的结果会被我们下一次直接覆盖,我们查找的范围也是根据元素个数来的,所以根本不需要重置数组。
情况三
这部分我们来看特殊值结束测试数据的情况
1°字符统计
这题我们依旧有两种思路,我们可以逐个字符的读取,然后统计,这里可以使用getchar(),我们也可以一次性读取整个字符串然后统计
1#include<iostream> 2using namespace std; 3int Letters, Digits, Others; 4int main() 5{ 6 int ch = 0; 7 while ((ch = getchar()) != '?') 8 { 9 if ((ch >= 'a' && ch <= 'z') || (ch >= 'A' && ch <= 'Z')) 10 Letters++; 11 else if (ch >= '0' && ch <= '9') 12 Digits++; 13 else 14 Others++; 15 } 16 cout << "Letters=" << Letters << endl; 17 cout << "Digits=" << Digits << endl; 18 cout << "Others=" << Others << endl; 19 return 0; 20}
这里将那几个参数定义为全局变量是因为:全局变量 / 静态变量 → 系统自动帮你赋值为 0
拓展函数
下面为大家介绍几个函数帮助大家简化代码:
1//头文件 2#include <cctype>
| 函数 | 作用 |
|---|---|
| isalpha(c) | 是否是字母(大小写都算) |
| islower(c) | 是否小写字母 -- 小写字母 a-z |
| isupper(c) | 是否大写字母 -- 大写字母 A-Z |
| isdigit(c) | 是否数字 -- 数字 0-9 |
| isspace(c) | 是否空格、换行、制表符 |
返回值规则 完全一模一样
所有这 5 个函数的返回值规则:
- 如果【是】 → 返回一个 非 0 的整数(真)
- 如果【不是】 → 返回 0(假)
下面我们对代码进行优化:
1#include<iostream> 2#include<cctype> 3using namespace std; 4int Letters, Digits, Others; 5int main() 6{ 7 int ch = 0; 8 while ((ch = getchar()) != '?') 9 { 10 if ((islower(ch)) || (isupper(ch))) 11 Letters++; 12 else if (isdigit(ch)) 13 Digits++; 14 else 15 Others++; 16 } 17 cout << "Letters=" << Letters << endl; 18 cout << "Digits=" << Digits << endl; 19 cout << "Others=" << Others << endl; 20 return 0; 21}
1#include<iostream> 2#include<cctype> 3using namespace std; 4int Letters, Digits, Others; 5int main() 6{ 7 int ch = 0; 8 while ((ch = getchar()) != '?') 9 { 10 if (isalpha(ch)) 11 Letters++; 12 else if (isdigit(ch)) 13 Digits++; 14 else 15 Others++; 16 } 17 cout << "Letters=" << Letters << endl; 18 cout << "Digits=" << Digits << endl; 19 cout << "Others=" << Others << endl; 20 return 0; 21}
下面我们来看方法二:
1#include<iostream> 2#include<string> 3using namespace std; 4int Letters, Digits, Others; 5int main() 6{ 7 string s; 8 getline(cin, s, '?'); 9 for (auto e : s) 10 { 11 if (isalpha(e)) 12 Letters++; 13 else if (isdigit(e)) 14 Digits++; 15 else 16 Others++; 17 } 18 cout << "Letters=" << Letters << endl; 19 cout << "Digits=" << Digits << endl; 20 cout << "Others=" << Others << endl; 21 return 0; 22}
这里需要注意我们之前介绍过的getline的第二种用法,其实还有一种方法就是使用getline的第一种写法,然后写个pop_back,也可以满足需求
2°多组数据a+b III
1#include<iostream> 2using namespace std; 3int main() 4{ 5 int a, b; 6 while (cin >> a >> b) 7 { 8 if (a == 0 && b == 0) 9 break; 10 cout << a + b << endl; 11 } 12 return 0; 13}
这里其实还有一种写法,利用到了逗号表达式:逗号隔开的一串表达式的特点:从左向右依次计算,整个表达式的结果是最后一个表达式的结果
1#include<iostream> 2using namespace std; 3int main() 4{ 5 int a, b; 6 while (cin >> a >> b, a || b) 7 { 8 cout << a + b << endl; 9 } 10 return 0; 11}
1.3、输入时的特殊技巧
根据我们现在掌握的知识,含空格的字符串,如要读取有 fgets、scanf、getchar、getline 四种方式解决,但是有时候,根据题目的情况,不一定非要完整的读取这个带空格的字符串,而是将字符串中空格隔开的每一个字符串,当做一个单词处理更方便,也避免了读取带空格字符串的各种问题。
1°含空格字符串的输入技巧 -- 统计数字字符个数
这个题目其实与字符统计那个题目非常类似,我们依旧可以采取整个字符串一次性读取,然后处理字符串,也可以采取逐个单词的方式处理,下面给出两种方案的代码:
1#include<iostream> 2#include<string> 3using namespace std; 4int main() 5{ 6 string s; 7 getline(cin, s); 8 int count = 0; 9 for (auto e : s) 10 { 11 if (isdigit(e)) 12 count++; 13 } 14 cout << count << endl; 15 return 0; 16}
1#include<iostream> 2#include<string> 3using namespace std; 4int main() 5{ 6 string s; 7 int count = 0; 8 while (cin >> s) 9 { 10 for (auto e : s) 11 { 12 if (isdigit(e)) 13 count++; 14 } 15 } 16 cout << count << endl; 17 return 0; 18}
2°数字的特殊处理方式 -- 小乐乐改数字
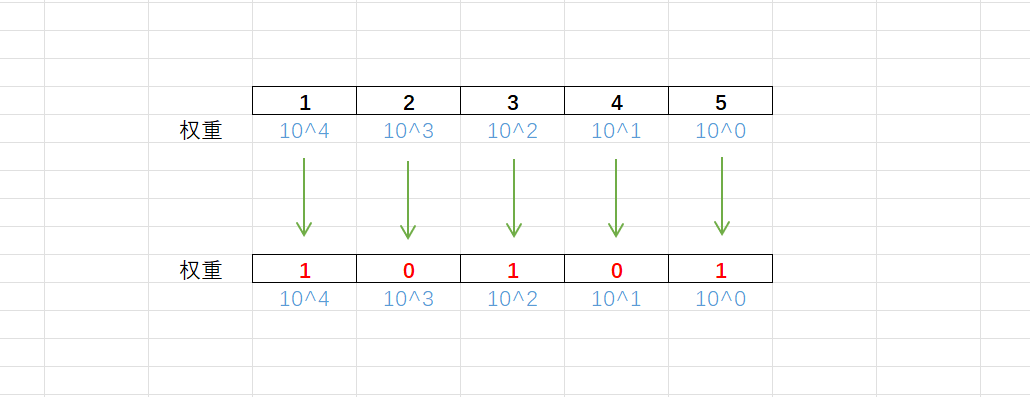
1#include<iostream> 2#include<cmath> 3#include<string> 4using namespace std; 5 6int main() { 7 int n; 8 cin >> n; 9 int i = 0; //标记⼀下此时处理到多少位 10 int ret = 0; 11 while (n) { 12 if (n % 10 % 2) //如果这⼀位是奇数 13 ret += 1 * pow(10, i); 14 else 15 ret += 0 * pow(10, i); 16 n /= 10; //把最后⼀位干掉 17 i++; 18 } 19 cout << ret << endl; 20 return 0; 21}
其实我们还有一种思路就是将输入的内容当做字符串处理:
1#include<iostream> 2#include<cmath> 3#include<string> 4using namespace std; 5 6int main() { 7 string s; 8 cin >> s; 9 for (int i = 0; i < s.size();i++) 10 { // 数字字符与对应的数的奇偶⼀致 11 if (s[i] % 2) 12 { 13 s[i] = '1'; 14 } 15 else 16 { 17 s[i] = '0'; 18 } 19 } 20 cout << stoi(s) << endl; // 转换成数字输出 21 return 0; 22}
1.4、scanf / printf与cin / cout的对比
1°格式控制差异
scanf和printf不能自动识别输入数据的类型,需要手动指定格式字符串,容易出现格式错误。开发者需要确保格式字符串与变量类型匹配,否则会导致未定义行为。cin和cout会根据变量类型自动处理输入输出,避免格式化错误。相对scanf和printf而且,C++ 的cin和cout更加易用。scanf和printf:格式化输出更精确直观,特别适合复杂格式的输入输出,比如:在要求指定格式输出的时候,printf函数就比cout更加方便和灵活。
区别
2°性能差异
结论:
scanf和printf通常比cin和cout快。
原因:
cin和cout由于要考虑兼容 C 语言的输入和输出,封装实现的更加复杂,通常比scanf和printf稍慢,但这种差异在大多数应用场景中可以忽略不计。但是在竞赛的题目中,尤其是当输入、输出数据量较大时,使用
cin和cout完成输入输出,经常会出现Time Limit Exceeded的情况。而scanf和printf就不存在类似的问题。下面给大家准备了两个案例。
数字游戏

我们从这个题目的输入描述应该就不难看出这个题目的数据量是非常大的,题目也提示我们请选择较快的读入方式,下面给出两种输入方式所展现的代码,大家不用看懂代码只需要去对比一下性能差异即可:
1#include <iostream> 2using namespace std; 3int t, x; 4int main() 5{ 6 cin >> t; 7 while (t--) 8 { 9 cin >> x; 10 int ret = 0; 11 while (x) 12 { 13 int count = 0, high = 0; 14 int tmp = x; 15 while (tmp) 16 { 17 //计算最右边的1代表的值 18 int low = tmp & -tmp; 19 //如果low中剩余的1就是最后⼀个1就是最左边的1 20 if (tmp == low) 21 { 22 high = low; 23 } 24 //去掉最右边的1 25 tmp -= low; 26 count++; 27 } 28 if (count % 2 == 0) 29 { 30 x -= high; 31 } 32 else 33 { 34 x ^= 1; 35 } 36 ret++; 37 } 38 cout << ret << endl; 39 } 40 return 0; 41} 42
1#include <iostream> 2using namespace std; 3int t, x; 4int main() 5{ 6 scanf("%d", &t); 7 while (t--) 8 { 9 scanf("%d", &x); 10 int ret = 0; 11 while (x) 12 { 13 int count = 0, high = 0; 14 int tmp = x; 15 while (tmp) 16 { 17 //计算最右边的1代表的值 18 int low = tmp & -tmp; 19 //如果low中剩余的1就是最后⼀个1就是最左边的1 20 if (tmp == low) 21 { 22 high = low; 23 } 24 //去掉最右边的1 25 tmp -= low; 26 count++; 27 } 28 if (count % 2 == 0) 29 { 30 x -= high; 31 } 32 else 33 { 34 x ^= 1; 35 } 36 ret++; 37 } 38 printf("%d\n", ret); 39 } 40 return 0; 41} 42

这是两次的运行时间大家很明显就可以看出差异了
求第 k 小的数
这题我们依旧采用两种输入输出方式进行提交,我们来看看有什么区别:
1#include <iostream> 2#include <cstdio> 3#include <algorithm> 4using namespace std; 5const int N = 5000010; 6int arr[N]; 7int main() 8{ 9 int n, k; 10 cin >> n >> k; 11 for (int i = 0; i < n; i++) 12 { 13 cin >> arr[i]; 14 } 15 sort(arr, arr + n); 16 cout << arr[k] << endl; 17 return 0; 18} 19
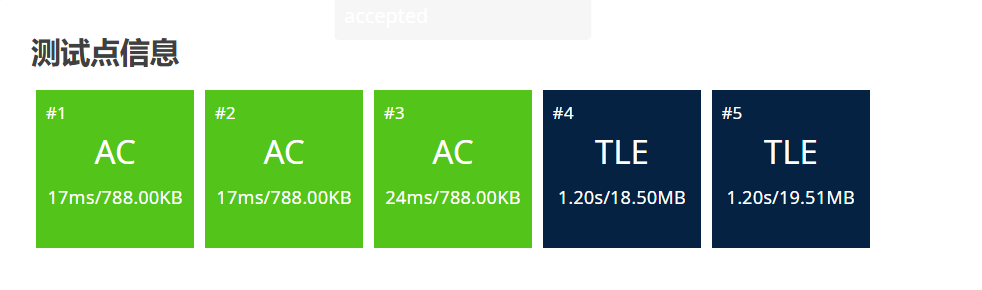
我们发现超时了,下面我们一种输入输出方式:
1#include <iostream> 2#include <cstdio> 3#include <algorithm> 4using namespace std; 5const int N = 5000010; 6int arr[N]; 7int main() 8{ 9 int n, k; 10 cin >> n >> k; 11 for (int i = 0; i < n; i++) 12 { 13 scanf("%d", &arr[i]); 14 } 15 sort(arr, arr + n); 16 cout << arr[k] << endl; 17 return 0; 18}

总结一下其实就是 2 个点:
- C++ 中为了支持混合使用
cin/cout和scanf/printf,C++ 标准库默认会将cin、cout等 C++ 流对象与stdin、stdout等 C 标准库的流对象同步在一起。这种同步操作意味着每次使用cin或cout时,都会自动刷新 C 标准库的缓冲区,以确保 C++ 和 C 的 I/O 是一致的。这就导致了性能的下降。- 在默认情况下,
cin和cout之间存在一种绑定关系。这种绑定意味着,每当从cin读取数据时,任何之前通过cout输出的内容都会被强制刷新到屏幕上。这种绑定也可能导致性能问题,特别是在需要频繁读取大量数据的情况下。
3°优化方案
如果大家还是想要去使用cin和cout也不是不可以只需要加上下面三行代码即可:
1//在io需求⽐较⾼的地⽅,如部分⼤量输⼊的竞赛题中,加上以下3⾏代码 2//可以提⾼C++IO效率 3ios_base::sync_with_stdio(false);//取消给C语⾔输⼊输出缓冲区的同步 4cin.tie(nullptr);//取消了cin和cout的绑定 5cout.tie(nullptr); 6
二、函数
2.1、概述
为大家准备了一篇可以精准解决函数基础概念及基本语法的博客:
1°普通参数
下面为大家强调一些关键点,我们首先来看一个简单的加法函数:
1#include<iostream> 2using namespace std; 3int Add(int x, int y) 4{ 5 int z = 0; 6 z = x + y; 7 return z; 8} 9int main() 10{ 11 int a = 0; 12 int b = 0; 13 //输⼊ 14 cin >> a >> b; 15 //调⽤加法函数,完成a和b的相加 16 //求和的结果放在r中 17 int r = Add(a, b); 18 //输出 19 cout << r << endl; 20 return 0; 21}
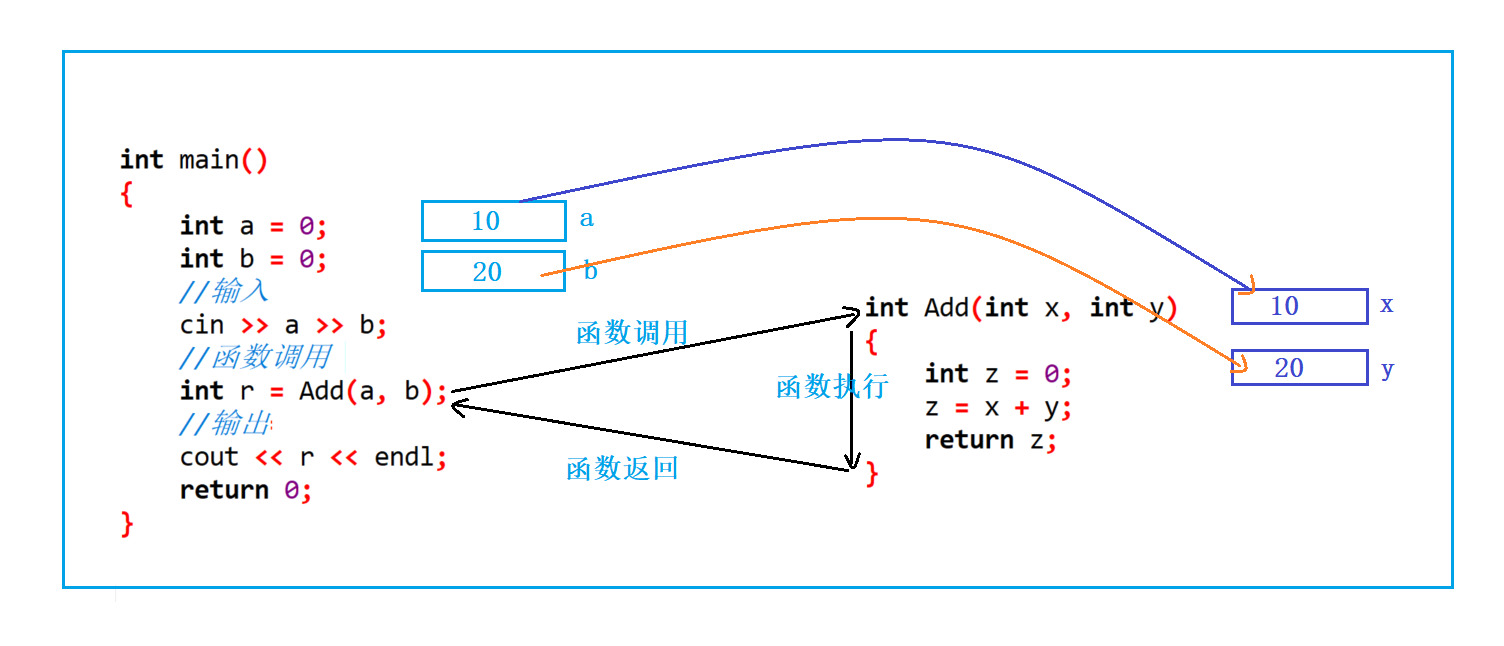
我们首先是对Add函数有个定义,有了函数之后我们下面调用Add函数的时候,传递给函数的参数a和b称为实际参数,也就是我们常说的实参;定义函数的时候,在函数名Add后的括号中写的x和y,称为形式参数,简称形参。
为什么叫形式参数呢?实际上,如果只是定义了 Add 函数,而不去调用的话,Add 函数的参数 x 和 y 只是形式上存在的,不会向内存申请空间,不会真实存在的,所以叫形式参数。形式参数只有在函数被调用的过程中为了存放实参传递过来的值,才向内存申请空间,这个过程就是形式的实例化。虽然我们提到了实参是传递给形参的,他们之间是有联系的,但是形参和实参各自是独立的内存空间。
我们在调试的可以观察到,
x和y确实得到了a和b的值,但是x和y的地址和a和b的地址是不一样的,当a和b传参给形参x和y的时候,x和y只是得到了a和b的值,他们得有自己独立的空间。所以我们可以理解为形参是实参的一份临时拷贝。
简单概括一下就是:形参不用就不占空间,用了就去额外开辟空间(地址不同,形参实参互不影响),形参是实参的一份临时拷贝
2°数组
当我们将函数和数组练习起来的时候就要注意下面的几点:
- 函数的实参的名字和形参的名字可以相同,也可以不同
- 函数的形式参数要和函数的实参个数匹配
- 函数的实参是数组,形参也写成数组形式的
- 形参如果是一维数组,数组大小可以省略不写
- 形参如果是二维数组,行可以省略,但是列不能省略
- 数组传参,形参是不会创建新的数组的
- 形参操作的数组和实参的数组是同一个数组
简单一句话概括就是:函数实参和形参名字可同可不同、个数要匹配;数组传参时形参不新建数组,直接操作原数组,一维形参数组大小可省略,二维只能省略行不能省略列。
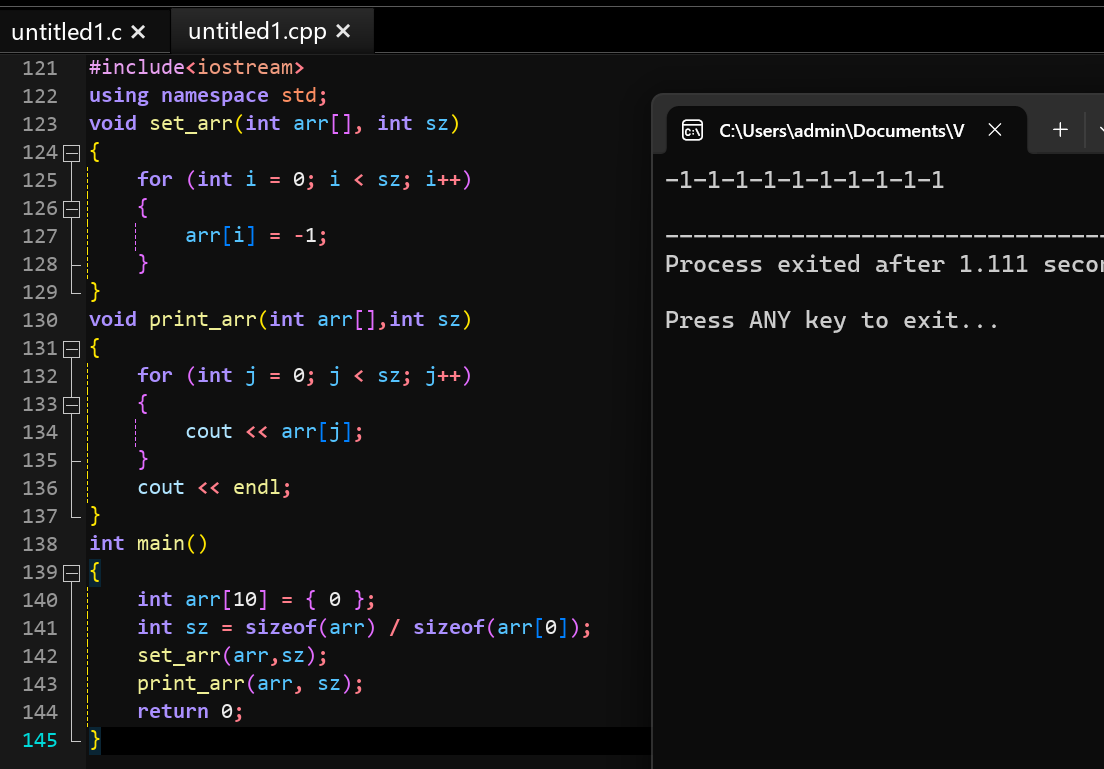
数组传参时,形参不会创建新数组,所以形参数组不需要指定大小!但是不可以写成int arr,这样会认为是一个整型变量而不是数组
3°字符串
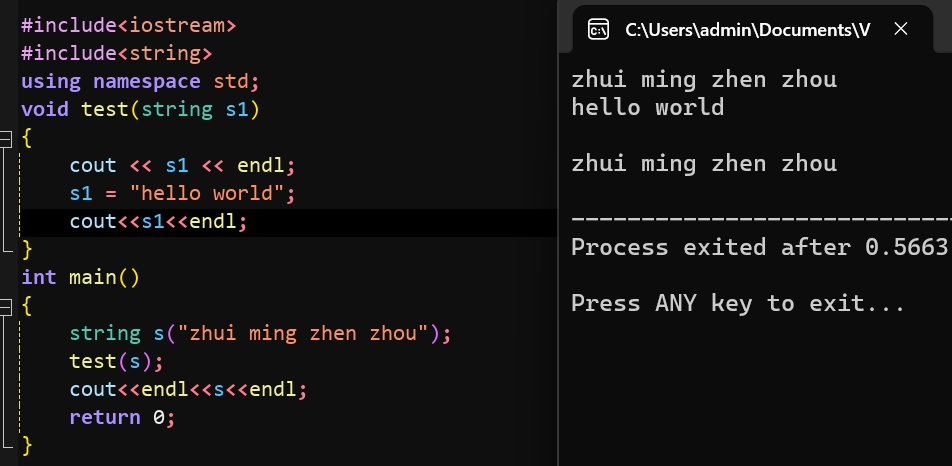
一句话直接概括就是:字符串传参:普通字符串形参是临时拷贝,修改不影响实参
4°全局变量
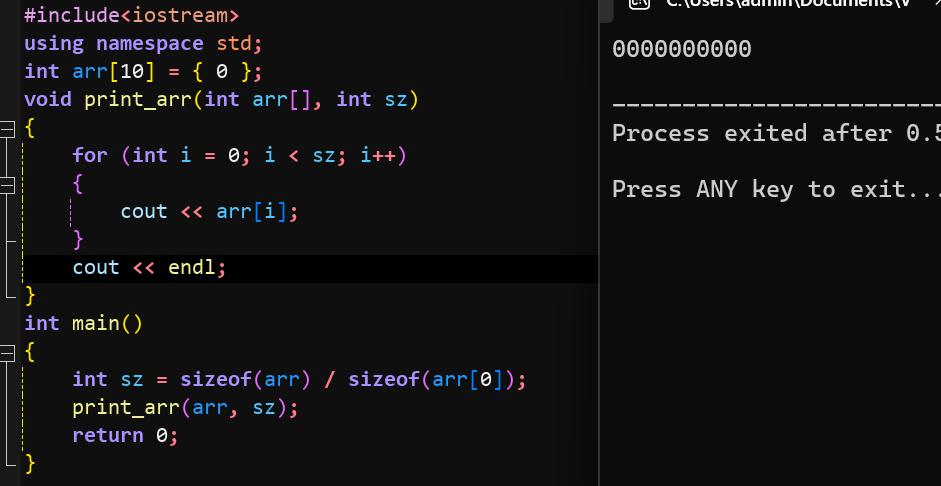
全局变量的作用域很大,在整个程序中都可以使用,那么只要把变量、数组等定义成全局变量,在函数中使用,是可以不用传参的。
当然,有时候变量或者数组,定义成全局的时候,是不能解决问题,比如:递归等场景,这时候,就得考虑传参的问题,后面会为大家讲解
2.2、返回值
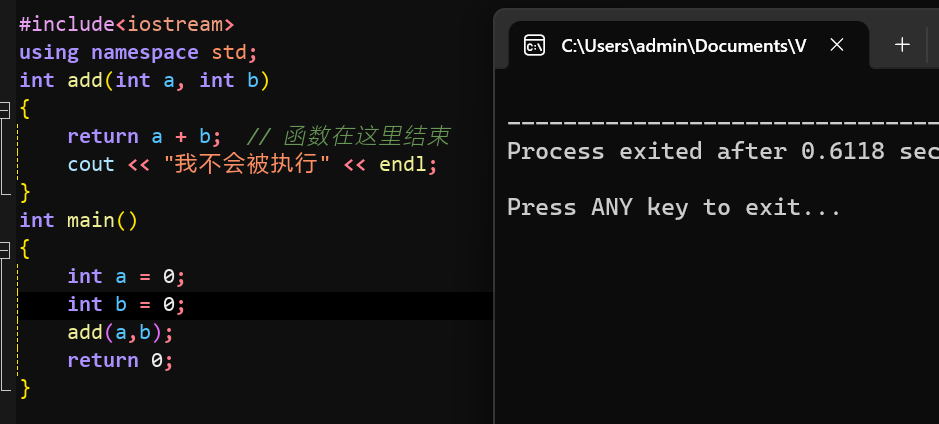
这里我们只说一点:return语句执行后,函数就彻底返回,后边的代码不再执行:
2.3、声明和定义
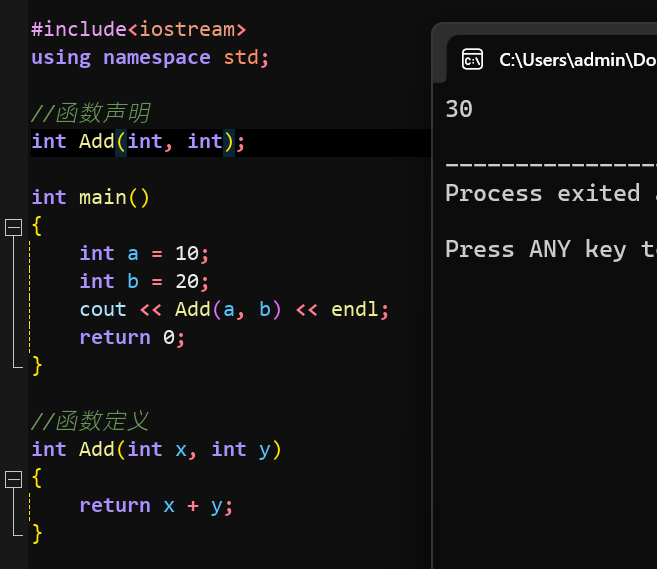
我们首先来看一下什么是函数声明什么是函数定义:
1//函数声明 2int Add(int x, int y); 3 4//函数定义 5int Add(int x, int y) 6{ 7 return x + y; 8}
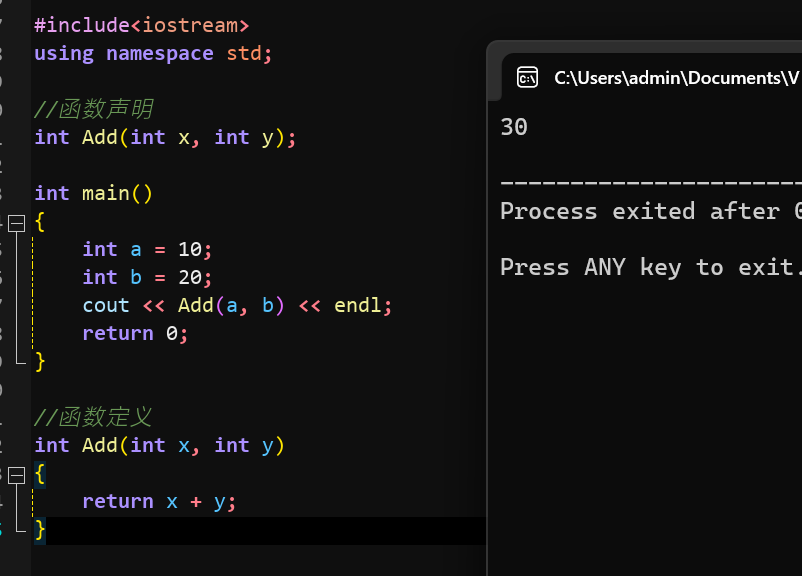
声明放前面,定义放后面,主函数能正常调用:
函数使用的时候要注意:1)函数要满足先声明后使用;2)函数的定义是一种特殊的声明;3)函数声明的时候形参的变量名是可以省略的,只保留类型即可:
2.4、函数调用
1°传值调用
写一个1函数Max,求两个整数的较大值:
1#include <iostream> 2using namespace std; 3int Max(int x, int y) 4{ 5 return x > y ? x : y; 6} 7int main() 8{ 9 int a = 0; 10 int b = 0; 11 cin >> a >> b; 12 int c = Max(a, b); 13 cout << c << endl; 14 return 0; 15} 16
调用Max函数时,就是传值调用。传值调用就是将实参的数据直接传递给形参。这个过程其实是将实参的值拷贝一份给Max函数使用,这份副本其实就是形参变量。这时形参和实参是不同的变 量,所以对形参的修改,不会影响实参。这种情况下参数传递的方式只能从实参到形参,也就是单向传递。为了理解什么是单向传递,我们看一下下面一个函数:
写一个函数Swap,交换两个整型变量的值:
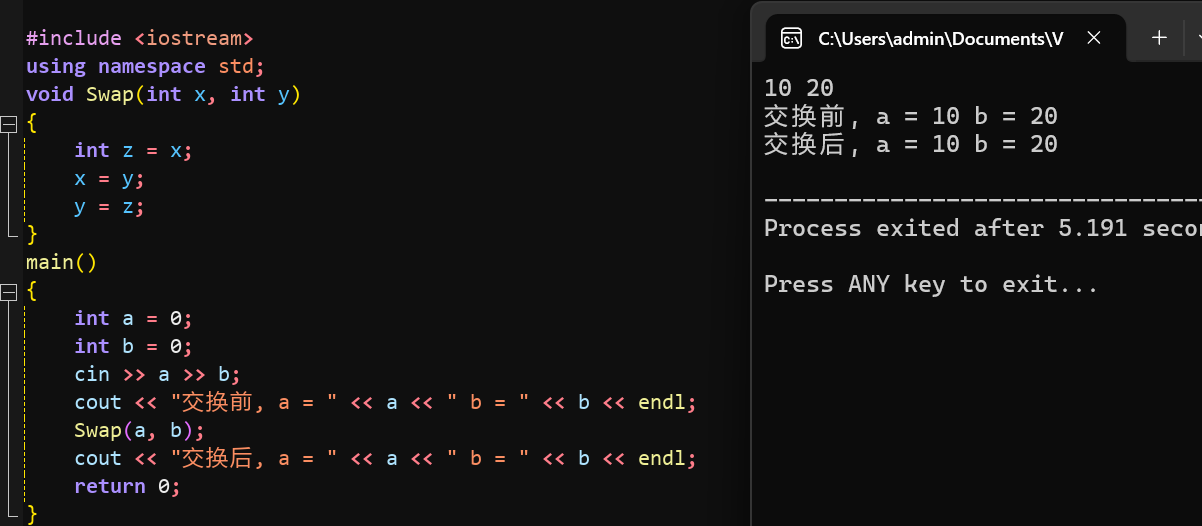
我们发现函数的思路没有任何问题但是代码结果却和我们想的完全不一样,这是为什么呢?
其实
Swap函数里的x和y确实会交换,但main里的a和b丝毫未变。这就是值传递的特点:形参与实参占用不同内存,对形参的修改不会影响实参,数据单向传递,因此交换失败。一句话概括:x和y是独立空间,交换它们不等于交换a和b。
那怎么样才能实现交换呢?下面我们就来看看C++中的引用:
2°引用
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量是同一块内存空间
类型& 引用别名 = 引用对象
- 引用在定义时必须初始化
- 一个变量可以有多个引用
- 引用一旦引用一个实体,再不能引用其他实体
引用就相当于个一个变量起一个别名:
1#include<iostream> 2using namespace std; 3int main() 4{ 5 int a = 0; 6 // 引⽤:b和c是a的别名 7 int& b = a; 8 int& c = a; 9 // 也可以给别名b取别名,d相当于还是a的别名 10 int& d = b; 11 ++d; 12 // 这⾥取地址我们看到是⼀样的 13 cout << &a << endl; 14 cout << &b << endl; 15 cout << &c << endl; 16 cout << &d << endl; 17 return 0; 18}
我们来看运行结果发现是一模一样的,我们就相当于给一块空间取了一个名字和三个别名,就类似于家人给我们取的小名一样,他们喊大名或者小名本质上就是在喊我们:

下面我们来对swap函数进行更改:
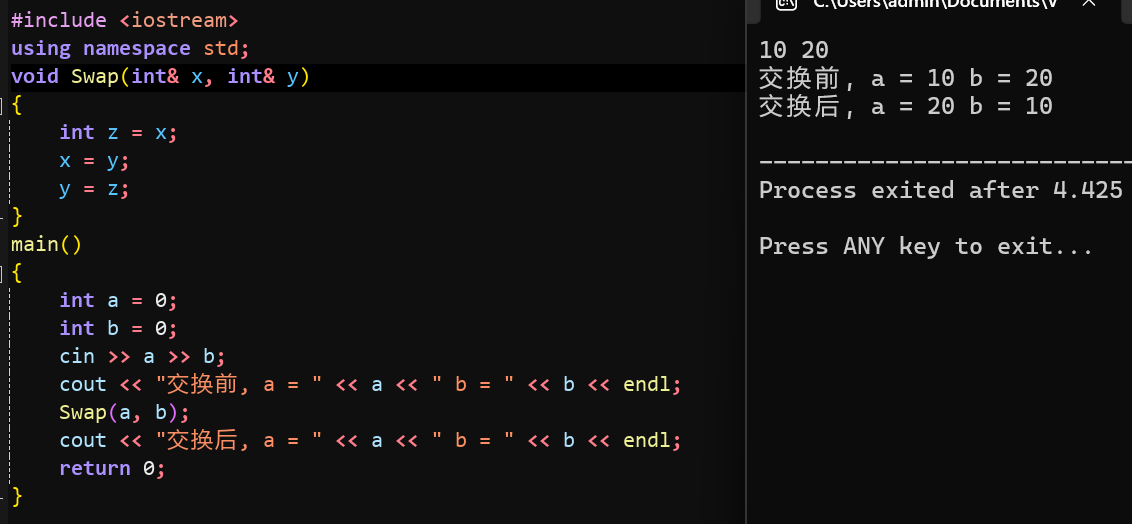
我们现在就实现了Swap交换函数,其实C++STL中也提供了一个库函数swap,这个函数可以用来交换两个变量也可以交换两个数组(容器的值):

1#include <iostream> 2#include <utility> 3using namespace std; 4int main() 5{ 6 int a = 0; 7 int b = 0; 8 cin >> a >> b; 9 cout << "交换前, a = " << a << " b = " << b << endl; 10 swap(a, b);//直接使⽤库函数swap交换两个变量 11 cout << "交换后, a = " << a << " b = " << b << endl; 12 13 //swap也可以交换两个数组 14 int arr1[4]; // arr1: 0 0 0 0 15 int arr2[] = { 10,20,30,40 }; // arr1: 0 0 0 0 arr2: 10 20 30 40 16 swap(arr1, arr2); // arr1: 10 20 30 40 arr2: 0 0 0 0 17 18 for (int e : arr1) 19 cout << e << " "; 20 cout << endl; 21 22 return 0; 23}
那么字符串能不能使用引用的方式传参呢?当时是可以的:
1#include <iostream> 2using namespace std; 3void printString(string& s) 4{ 5 cout << s << endl; 6 s = "zhui ming zhen zhou"; 7} 8int main() 9{ 10 string s("hello world"); 11 printString(s); 12 cout << s << endl; 13 return 0; 14}
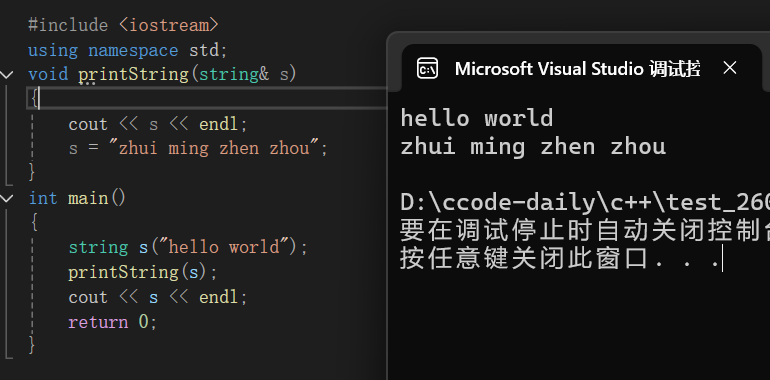
3°效率比较
采用传值调用过程中,函数传参,将实参传递给形参的时候,形参会创建新的空间,再将实参的数据给形参拷贝一份;但是引用传参的方式,就不存在数据的拷贝,只是在形参的部分建立引用的关系,形参就是实参。所以引用传参的效率要高于传值调用的方式。
💡小提示:数组在传参的时候,形参和实参本来就是同一个数组,所以数组传参的时候,不需要使用引用参数。
2.5、函数重载
函数重载 + 引用巩固超详细版:
练习
关于函数的题目其实非常多这里为大家挑选一些较为典型的案例:
1°最大数 max(x,y,z)
1#include<iostream> 2#include<iomanip> 3using namespace std; 4 5int MAX(int x, int y, int z)//存储最大值 6{ 7 int m = x > y ? x : y; 8 return m > z ? m : z; 9} 10 11int main() 12{ 13 int a, b, c; 14 cin >> a >> b >> c; 15 double m = ((double)MAX(a, b, c) / ((MAX(a + b, b, c) * MAX(a, b, b + c)))); 16 cout << fixed << setprecision(3) << m << endl; 17 18 return 0; 19}
拓展函数
这里为大家拓展库函数max和min:
max
max
在 C++ 中,
max函数用于返回两个值中的较大值。它是 C++ 标准库<algorithm>头文件中的一个函数。
max函数可以用于各种类型,包括内置类型(如int、double)以及用户自定义类型(如类或结构体),只要这些类型支持比较操作。
1#include <algorithm> 2template <class T> 3const T & max(const T & a, const T & b); //默认⽐较 4template <class T, class Compare> 5const T& max(const T& a, const T& b, Compare comp); //⾃定义⽐较器
参数:
返回值:
总结
使用
max库函数需要包含<algorithm>头文件。对于整型、浮点型等基础数据类型,可以直接使用max函数比较大小;但在特殊场景下(如自定义结构体、类、字符串比较规则等),库函数无法满足需求,需要自定义比较规则来实现大小比较。
1#include <iostream> 2#include <algorithm> 3using namespace std; 4int main() 5{ 6 int x = 10; 7 int y = 20; 8 int m = max(x, y); 9 cout << "较大值是: " << m << endl; 10 11 return 0; 12}
1#include <iostream> 2#include <algorithm> 3#include <string> 4using namespace std; 5bool compareLength(const string& a, const string& b) 6{ 7 return a.size() < b.size(); //这⾥必须给⼀个判断⼩于的标准 8} 9int main() 10{ 11 string str1 = "apple"; 12 string str2 = "banana"; 13 string max_str = max(str1, str2, compareLength); 14 cout << "长度更长的字符串是" << max_str << endl; 15 16 return 0; 17}
min
在 C++ 中,
min函数用于返回两个值中的较小值。它和max函数类似,也是在 C++ 标准库<algorithm>头文件中的一个函数。使用和max函数一模一样,只是实现的效果恰好相反。
1#include <iostream> 2#include <algorithm> 3#include <string> 4using namespace std; 5bool compareLength(const string& a, const string& b) 6{ 7 return a.size() < b.size(); //这⾥必须给⼀个判断⼩于的标准 8} 9int main() 10{ 11 string str1 = "apple"; 12 string str2 = "banana"; 13 string min_str = min(str1, str2, compareLength); 14 15 cout << "长度更短的字符串是" << min_str << endl; 16 return 0; 17} 18
学完了之后我们可以对这题的代码进行优化:
1#include<iostream> 2#include<iomanip> 3#include<algorithm> 4using namespace std; 5 6int MAX(int x, int y, int z)//存储最大值 7{ 8 int m = max(x, y); 9 return max(m, z); 10} 11 12int main() 13{ 14 int a, b, c; 15 cin >> a >> b >> c; 16 double m = ((double)MAX(a, b, c) / ((MAX(a + b, b, c) * MAX(a, b, b + c)))); 17 cout << fixed << setprecision(3) << m << endl; 18 19 return 0; 20}
2°求正整数 2 和 n 之间的完全数
1#include<iostream> 2using namespace std; 3// 求n的所有因数之和 4int sumFactor(int n) 5{ 6 int sum = 0; 7 for (int i = 1; i < n; i++) 8 { 9 if (n % i == 0) { // 如果 i 是 n 的因数 10 sum += i; // 加到总和里 11 } 12 } 13 return sum; 14} 15int main() 16{ 17 int n; 18 cin >> n; 19 for (int i = 2; i <= n; i++) 20 { 21 if (i == sumFactor(i)) 22 cout << i << endl; 23 } 24 return 0; 25}
3°素数个数
素数也叫质数,是指在大于1的自然数中,除了1和它本身以外不再有其他因数的自然数:
1#include <iostream> 2using namespace std; 3// 判断素数:是素数返回 true,不是返回 false 4bool check_prime(int m) 5{ 6 for (int i = 2; i < m; i++) 7 { 8 if (m % i == 0) // 能被整除 → 不是素数 9 return false; 10 } 11 return true; // 循环结束都没整除 → 是素数 12} 13int main() 14{ 15 int n; 16 cin >> n; 17 int count = 0; 18 for (int i = 2; i <= n; i++) 19 { 20 if (check_prime(i)) // 是素数 → 计数 21 { 22 count++; 23 } 24 } 25 cout << count << endl; 26 return 0; 27}
其实判断素数还有一种方式我们去利用sqrt()函数:
1#include <iostream> 2#include <cmath> // 用 sqrt 必须加这个头文件 3using namespace std; 4// 判断素数:是素数返回 true,不是返回 false 5bool check_prime(int m) 6{ 7 // 原来:i < m 8 // 现在:i <= sqrt(m) (优化核心) 9 for (int i = 2; i <= sqrt(m); i++) 10 { 11 if (m % i == 0) // 能被整除 → 不是素数 12 return false; 13 } 14 return true; // 循环结束都没整除 → 是素数 15} 16int main() 17{ 18 int n; 19 cin >> n; 20 int count = 0; 21 for (int i = 2; i <= n; i++) 22 { 23 if (check_prime(i)) // 是素数 → 计数 24 { 25 count++; 26 } 27 } 28 cout << count << endl; 29 return 0; 30}
4°素数对
1#include <iostream> 2#include <cmath> 3using namespace std; 4bool is_prime(int n) 5{ 6 int j = 0; 7 if (n < 2) 8 return false; 9 for (j = 2; j <= sqrt(n); j++) 10 { 11 if (n % j == 0) 12 return false; 13 } 14 return true; 15} 16int main() 17{ 18 int n = 0; 19 cin >> n; 20 int i = 0; 21 int flag = 0; 22 for (i = 2; i + 2 <= n; i++) 23 { 24 if (is_prime(i) && is_prime(i + 2)) 25 { 26 cout << i << " " << i + 2 << endl; 27 flag++; 28 } 29 } 30 if (flag == 0) 31 cout << "empty" << endl; 32 return 0; 33} 34
5°素数回文数的个数
1#include<iostream> 2#include<cmath> 3#include<string> 4using namespace std; 5//判断是否是素数 6bool isPrime(int m) 7{ 8 if (m < 2) 9 return false; 10 for (int i = 2; i <= sqrt(m); i++) 11 { 12 if (m % i == 0) 13 return false; 14 } 15 return true; 16} 17//判断是否是回文数 18bool ispalindrome(int m) 19{ 20 int ret = m; 21 //将数字转换成字符 22 string s = to_string(ret); 23 int left = 0; 24 int right = s.size() - 1; 25 while (left < right) 26 { 27 char tmp = s[left]; 28 s[left] = s[right]; 29 s[right] = tmp; 30 left++; 31 right--; 32 } 33 //将字符转换成数字 34 int num = stoi(s); 35 if (num == m) 36 return true; 37 else 38 return false; 39} 40int main() 41{ 42 int n; 43 cin >> n; 44 int count = 0;//统计个数 45 for (int i = 11; i <= n; i++) 46 { 47 if (isPrime(i) && ispalindrome(i)) 48 count++; 49 } 50 cout << count << endl; 51 return 0; 52}
这是我第一遍写的代码,这段代码完全可以跑对这题但是其实还有优化的地方,比如回文数判断按那里我的做法是将数字先转换成string类型的字符串让他有下标然后去对比,最后转换成原数字和之前的数字比较,但是其实可以不用这么麻烦,回文数判断没必要反转 + 转数字,回文数不要反转再转数字,直接比较对称字符大家可以自行去尝试优化一下
6°区间内的真素数
1#include<iostream> 2#include<string> 3#include<cmath> 4using namespace std; 5bool isPrime(int m) 6{ 7 if (m < 2) 8 return false; 9 for (int i = 2; i <= sqrt(m); i++) 10 { 11 if (m % i == 0) 12 return false; 13 } 14 return true; 15} 16// 反序后判断是否为素数 17bool reversePrime(int m) 18{ 19 string s = to_string(m); 20 int left = 0; 21 int right = s.size() - 1; 22 while (left < right) 23 { 24 char tmp = s[left]; 25 s[left] = s[right]; 26 s[right] = tmp; 27 left++; 28 right--; 29 } 30 int ret = stoi(s); 31 return isPrime(ret); 32} 33int main() 34{ 35 int M, N; 36 cin >> M >> N; 37 int flag = 1; // 标记是否为第一个输出 38 int cnt = 0; // 统计真素数个数 39 for (int i = M; i <= N; i++) 40 { 41 if (isPrime(i) && reversePrime(i)) 42 { 43 cnt++; 44 if (flag) 45 { 46 cout << i; 47 flag = 0; 48 } 49 else 50 { 51 cout << "," << i; 52 } 53 } 54 } 55 // 若无真素数,输出 No 56 if (cnt == 0) 57 cout << "No"; 58 cout << endl; 59 return 0; 60}
我写的代码基本都已可以看懂并且跑出题目为准,要是想要优化提升效率还需大家自己去尝试,后面C++的内容我也会为大家出一篇博客有关提升代码效率,大家可以期待一下,以上就是函数部分的简单内容,还是需要大家多刷题才能更好掌握
三、递归
3.1、概述
为大家准备了一篇可以初步了解递归的博客(大家直接看递归的内容即可):
3.2、典型案例解析
1°计算阶乘
我们用递归和迭代两种方式为大家解决:
迭代
1#include<iostream> 2using namespace std; 3int main() 4{ 5 int n; 6 cin >> n; 7 int sum = 1; 8 for (int i = 1; i <= n; i++) 9 { 10 sum *= i; 11 } 12 cout << sum << endl; 13 return 0; 14}
递归
1#include<iostream> 2using namespace std; 3int fac(int n) 4{ 5 if (n == 0) 6 return 1; 7 else 8 return n * fac(n - 1); 9} 10int main() 11{ 12 int n; 13 cin >> n; 14 cout << fac(n) << endl; 15 return 0; 16}
这里还是要提醒大家一下:注意递归的中止条件,不然代码会有死循环、程序崩溃等问题
递归在书写的时候,有2个必要条件:
<1>、递归存在限制条件,当满足这个限制条件的时候,递归便不再继续。
<2>、每次递归调用之后越来越接近这个限制条件。
2°斐波那契数列
我们依旧使用递归与迭代两种方式为大家解决:
迭代
1#include<iostream> 2using namespace std; 3int main() 4{ 5 int n; 6 cin >> n;//数据组数 7 while (n--) 8 { 9 int m;//第几个斐波那契数 10 cin >> m; 11 int x = 1; int y = 1; 12 int z = 0; 13 if (m == 1 || m == 2) 14 cout << 1 << endl; 15 else 16 { 17 while (m > 2) 18 { 19 m--; 20 z = x + y; // 先把新数算出来(保存旧数据) 21 x = y; // 再挪 22 y = z; // 最后更新 23 } 24 cout << z << endl; 25 } 26 } 27 return 0; 28}
递归
1#include<iostream> 2using namespace std; 3int Fac(int m) 4{ 5 //m表示第几个斐波那契数 6 if (m == 1 || m == 2) 7 return 1; 8 else 9 return Fac(m - 1) + Fac(m - 2); 10} 11int main() 12{ 13 int n; 14 cin >> n;//数据组数 15 while (n--) 16 { 17 int m;//m表示第几个斐波那契数 18 cin >> m; 19 cout << Fac(m) << endl; 20 } 21 return 0; 22}
💡 核心结论先放这
递归 ≈ 层层套娃,占地方,容易炸 循环 ≈ 原地转圈,省空间,更高效
📦 通俗解释:函数调用和栈帧
你可以把内存的栈区想象成一个摞盘子的架子:
- 每调用一次函数,就往架子上放一个新盘子(这个盘子就是「栈帧」,用来放这个函数里的临时变量)。
- 函数执行完返回了,才把这个盘子拿走,空间还给系统。
🔄 递归为什么费空间、容易炸?
递归就是自己调用自己,相当于:
- 你先放了一个盘子(第一层函数)
- 还没拿走,又在上面放一个(第二层递归调用)
- 再放一个、再放一个…… 一直摞到很深
- 直到最后一层函数才开始返回,然后从顶往下一个一个拿走盘子
如果递归层数太多,盘子摞得太高,就会把架子压垮—— 这就是「栈溢出(stack overflow)」,程序直接崩溃。
🔁 循环为什么更高效?
循环是在同一个函数里反复跑逻辑:
- 只需要一开始放一个盘子(整个循环都用这一个盘子)
- 变量在同一个空间里反复覆盖更新,不会额外占更多盘子
- 没有频繁的「放盘子 / 拿盘子」开销,所以更快、更省内存
✅ 什么时候用递归?什么时候用循环?
- 优先用循环:大部分问题(比如计数、遍历),循环效率更高,不会有栈溢出风险。
- 递归更适合:逻辑特别复杂、用循环写会非常绕的场景(比如树的遍历、分治算法)。这时候递归代码更简洁、更好懂,哪怕多占一点内存、慢一点,也是值得的。
📌 一句话总结
- 递归:代码好写,但费内存,深度大了容易崩。
- 循环:代码可能稍繁琐,但省内存、跑得快,更稳定。
- 简单问题用循环,复杂问题用递归,看场景选就行。
还有一题和上述的非常类似,大家可以练练手:
1#include<iostream> 2using namespace std; 3int Fac(int m) 4{ 5 if (m < 1) 6 return 0; 7 else 8 return Fac(m - 1) + m; 9 10} 11int main() 12{ 13 int N; 14 cin >> N; 15 int ret = Fac(N); 16 cout << ret << endl; 17 return 0; 18}
练习
https://www.luogu.com.cn/problem/B2144
https://www.luogu.com.cn/problem/B2145
https://www.luogu.com.cn/problem/B2147
https://www.luogu.com.cn/problem/B2148
https://www.luogu.com.cn/problem/B2143

《【35天从0开始备战蓝桥杯 -- Day5】》 是转载文章,点击查看原文。


